When you design APIs that return large datasets, pagination is not optional. Without it, you risk overwhelming your database, your network, and your consumers. Pagination is the art of breaking data into manageable chunks, and like most things in software architecture, there is no single best way to do it. Each strategy has trade-offs that affect performance, consistency, and developer experience.
In this post, I will walk you through six common pagination strategies: Offset-based, Cursor-based, Keyset-based, Page-based, Time-based, and Hybrid approaches. For each, I will explain how it works, show you C# examples, and highlight the advantages and disadvantages. Along the way, I will use diagrams and analogies to make the concepts stick.
When developers first implement pagination…
When you design APIs that return large datasets, pagination is not optional. Without it, you risk overwhelming your database, your network, and your consumers. Pagination is the art of breaking data into manageable chunks, and like most things in software architecture, there is no single best way to do it. Each strategy has trade-offs that affect performance, consistency, and developer experience.
In this post, I will walk you through six common pagination strategies: Offset-based, Cursor-based, Keyset-based, Page-based, Time-based, and Hybrid approaches. For each, I will explain how it works, show you C# examples, and highlight the advantages and disadvantages. Along the way, I will use diagrams and analogies to make the concepts stick.
When developers first implement pagination, they almost invariably reach for the offset-based approach. It’s intuitive, simple to understand, and maps directly to the familiar concept of page numbers.
Offset-based pagination works by using two main parameters: an offset (or skip) and a limit (or take/pageSize). Think of it like reading a book: to get to page three with 10 items per page, you tell the database to “skip the first 20 items, then give me the next 10.”
The client requests a specific chunk of data by specifying how many records to skip from the beginning and how many to retrieve.
limit=10&offset=0: Get records 1-10 (Page 1)limit=10&offset=10: Get records 11-20 (Page 2)limit=10&offset=20: Get records 21-30 (Page 3)
C#
[HttpGet]
public async Task<IActionResult> GetProducts(
[FromQuery] int pageNumber = 1,
[FromQuery] int pageSize = 10)
{
// Basic validation
if (pageNumber < 1) pageNumber = 1;
if (pageSize < 1) pageSize = 10;
// Enforce a max page size
const int maxPageSize = 50;
pageSize = pageSize > maxPageSize? maxPageSize : pageSize;
var totalRecords = await _context.Products.CountAsync();
var products = await _context.Products
.OrderBy(p => p.Id)
.Skip((pageNumber - 1) * pageSize)
.Take(pageSize)
.ToListAsync();
var response = new
{
TotalRecords = totalRecords,
TotalPages = (int)Math.Ceiling(totalRecords / (double)pageSize),
PageNumber = pageNumber,
PageSize = pageSize,
Data = products
};
return Ok(response);
}
The method multiplies the page index by the page size to determine how many rows to skip before grabbing the requested slice. Always add deterministic ordering before you skip; otherwise, the database is free to reshuffle results between calls.
The interaction is simple and direct, as shown in this diagram:

The Performance Trap of Large Offsets
For small datasets, this approach works perfectly fine. However, as your table grows and users navigate to deeper pages, a hidden performance bomb detonates. The database, to fulfill a request with a large offset, must still scan and sort the records, and only then discard the ones that were skipped.
This creates a dangerous, hidden coupling in your system. The performance of your API endpoint is not stable, and it is inversely proportional to the total data volume. As your database grows, the response time for fetching page 1,000 silently degrades, leading to a “performance creep” that can suddenly cross a critical threshold and cause system-wide outages. Your API’s performance becomes unpredictably tied to the number of rows in your table.
The Data Consistency Problem
Performance isn’t the only issue. In a dynamic system with frequent writes, offset pagination is fundamentally unstable. Consider this scenario:
- A user requests page 1 (offset=0, limit=10) and sees items 1 through 10.
- Before they request the next page, a new item is added to the database at the very beginning.
- The user requests page 2 (offset=10, limit=10).
Because of the new item, what was previously item 10 is now item 11. The second page request will return items 11 through 20. The user will see item 10 (now at position 11) twice, and they will have completely missed the original item 11. The opposite happens if an item is deleted. This shifting “window” of data makes offset pagination unreliable for datasets that change frequently.
You might have noticed that my C# example used pageNumber and pageSize, which is often called “page-based” pagination. It’s crucial to understand that this is almost always just a user-friendly abstraction built on top of offset-based pagination.
Internally, the API server simply converts the page number and size into an offset using a simple formula: offset = (pageNumber - 1) * pageSize.
This distinction is important. While providing a pageNumber is more intuitive for API consumers, it does not change the underlying mechanics. Your API will still suffer from the exact same performance degradation and data consistency issues inherent to the offset approach. The convenience for the client doesn’t magically fix the inefficiency in the database.
Keyset and Cursor Pagination: A Performant Alternative
To solve the deep-rooted problems of offset pagination, we need a different approach. Keyset pagination, also known as the “seek method,” is the high-performance pattern used by large-scale systems like social media feeds to handle massive, dynamic datasets.
The terms “keyset” and “cursor” are often used interchangeably, which can be confusing. For API designers, it’s helpful to draw a clear distinction:
- Keyset Pagination (The Technique): This is the database-level strategy. Instead of skipping rows, it uses a
WHEREclause to filter for records that come after the last item seen on the previous page. This requires a stable and unique sort order. The “keyset” refers to the set of column values from the last record that are used for filtering (e.g., Id, or a combination of CreatedAt and Id). - Cursor Pagination (The Implementation): This refers to the token the API provides to the client to mark its position. The “cursor” is the value the client sends back to get the next page. This cursor can be transparent (e.g., the raw ID or timestamp) or opaque (an encoded, meaningless string that hides implementation details).
In short, you use the keyset technique in your database query, and you expose a cursor in your API.
The magic of keyset pagination lies in changing the query from “skip N rows” to “get rows after this specific row.” Instead of .Skip(), we use .Where().
Let’s say the last product on the previous page had an Id of 100. The query for the next page becomes incredibly simple and efficient:
C#
var lastSeenId = 100; // Value from the previous page's cursor
var pageSize = 10;
var products = await _context.Products
.OrderBy(p => p.Id)
.Where(p => p.Id > lastSeenId) // The "seek" condition
.Take(pageSize)
.ToListAsync();
Why is this so much faster? Because the database can use an index on the Id column to jump directly to the starting point. It doesn’t need to scan and discard thousands of rows from the beginning of the table. The query performance remains consistently fast, whether you’re on page 2 or page 20,000.
Handling Non-Unique Sort Keys
A critical requirement for keyset pagination is that the sorting key must be unique. What if you’re sorting by a CreatedAt timestamp, where multiple records could share the exact same value? If you only filter by WHERE CreatedAt > lastTimestamp, you could miss records with the same timestamp.
The solution is to create a composite key by adding a unique tie-breaker column to the ORDER BY and WHERE clauses. The Id is a perfect candidate.
The query becomes:
C#
var lastTimestamp =...; // From the cursor
var lastId =...; // From the cursor
var products = await _context.Products
.OrderBy(p => p.CreatedAt)
.ThenBy(p => p.Id)
.Where(p => p.CreatedAt > lastTimestamp ||
(p.CreatedAt == lastTimestamp && p.Id > lastId))
.Take(pageSize)
.ToListAsync();
This ensures a perfectly stable and unique ordering, guaranteeing no data is missed.
The Power of the Opaque Cursor
While you could simply return the lastId to the client as the cursor, a more robust approach is to use an opaque cursor. This is a string, often Base64-encoded, that contains all the information the server needs to fetch the next page but is meaningless to the client.
The primary benefit is decoupling. The client is no longer aware of your internal database schema or sorting logic. You could change your pagination strategy from sorting by Id to sorting by CreatedAt and Id without breaking a single client. The client’s contract is simple: “Here is the cursor you gave me last time; give me the next page.”
Here’s a simple C# implementation for creating and decoding an opaque cursor:
C#
public record ProductCursor(DateTime CreatedAt, int Id);
public static class CursorEncoder
{
public static string Encode(ProductCursor cursor)
{
var json = System.Text.Json.JsonSerializer.Serialize(cursor);
var bytes = System.Text.Encoding.UTF8.GetBytes(json);
return Convert.ToBase64String(bytes);
}
public static ProductCursor Decode(string encodedCursor)
{
var bytes = Convert.FromBase64String(encodedCursor);
var json = System.Text.Encoding.UTF8.GetString(bytes);
return System.Text.Json.JsonSerializer.Deserialize<ProductCursor>(json);
}
}
Your API would encode the CreatedAt and Id of the last item into a string and return it as nextCursor. The client then passes this string back on the next request.
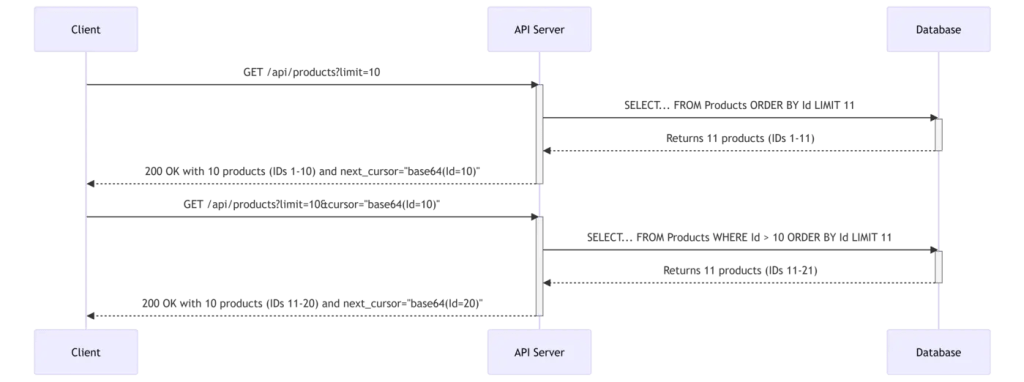
Client-Server Interaction with Cursors
This diagram illustrates the flow using an opaque cursor. Notice the trick of fetching limit + 1 items to determine if a next page exists without a separate COUNT query.
The Trade-off: No “Jump to Page”
The primary drawback of keyset and cursor pagination is that it doesn’t support random access, i.e., jumping directly to a specific page number. The design is inherently sequential, built for “next” and “previous” navigation. This makes it perfect for infinite scrolling UIs but a poor fit for interfaces that require traditional page number links. This is a prime example of how a backend architectural choice directly impacts and constrains the frontend user experience.
In the real world, requirements are rarely simple. Sometimes, a single pagination strategy isn’t enough. Hybrid pagination involves intelligently combining multiple techniques to meet complex needs, offering flexibility at the cost of increased complexity.
A common requirement is to paginate through a subset of data. For instance, a user might want to see all their orders placed within a specific date range. You can combine keyset pagination with other filters. The keyset provides efficient iteration within the filtered result set.
The API request might look like: GET /orders?cursor=abc&start_time=2023-01-01&end_time=2023-01-31.
The server-side query would apply both filters:
C#
var ordersQuery = _context.Orders
.Where(o => o.OrderDate >= startTime && o.OrderDate <= endTime);
// Apply cursor logic on top of the filtered query
if (cursor!= null)
{
ordersQuery = ordersQuery.Where(o => o.Id > cursor.LastId);
}
var orders = await ordersQuery
.OrderBy(o => o.Id)
.Take(pageSize)
.ToListAsync();
Infinite Scroll with Jump-to-Page
Modern user interfaces often present a challenging requirement: users want the fluid, engaging experience of infinite scrolling for casual browsing, but also the ability to jump directly to a specific page for targeted navigation. This pits the strengths of cursor pagination (infinite scroll) directly against the main feature of offset pagination (random access).
A pragmatic hybrid solution can provide the best of both worlds by making a conscious architectural trade-off:
- Use Cursor Pagination for Sequential Navigation: All “next” and “previous” page requests should use a cursor. This ensures the most common user action, scrolling, is highly performant, scalable, and consistent.
- Use Offset Pagination for Random Access: When a user explicitly clicks to “jump to page 50,” the client makes a single request using offset-based pagination (pageNumber=50). We acknowledge that this initial request will be less performant, but we accept this as a one-time cost for a less frequent action.
- Return Cursors with the Offset Response: This is the key to the hybrid approach. The response to the offset-based request for page 50 must include not just the data for that page, but also the cursors for the next page (page 51) and the previous page (page 49).
With these cursors in hand, the client can seamlessly switch back to the highly efficient cursor-based method for all subsequent scrolling. This hybrid model optimizes for the common case (scrolling) while still enabling the less frequent one (jumping), representing a mature compromise between ideal performance and ideal user experience.
Distilling everything we’ve discussed, here is an actionable checklist and a summary of the trade-offs to guide your implementation.
- Always Enforce a Max Page Size: Never fully trust the client to provide a reasonable page size. Implement a server-side default and a hard maximum limit to prevent a single user from requesting millions of records and causing a denial-of-service, whether accidental or malicious.
- Stable Ordering is Non-Negotiable: Every paginated query must have an OrderBy clause. Without it, the database provides no guarantee of the order of results between requests, making pagination meaningless. For keyset/cursor pagination, this ordering must be unique and backed by a database index.
- Design a Rich Pagination Response DTO: Don’t just return a raw array of data. Your response object should include metadata that empowers the client to build a rich, intuitive UI. Include properties like
totalRecords,totalPages(for offset),hasNextPage,hasPreviousPage, and thenextCursor. - Index Your Database for Performance: The performance of your pagination is directly tied to your database indexing strategy. Ensure that the columns used in your
ORDER BYandWHEREclauses are properly indexed. For composite keys (e.g., (CreatedAt,Id)), create a composite index in your database for maximum performance.
Strategy Comparison
This table summarizes the core trade-offs between the different pagination strategies, providing a quick reference for your architectural decisions.
| Strategy | How it Works | Performance | Data Consistency | Use Case | Jump to Page? |
|---|---|---|---|---|---|
| Offset-Based | SKIP/TAKE. Skips N rows. | Poor on large datasets (degrades with offset). | Unstable with frequent writes (missed/duplicate items). | Small, static datasets; admin UIs. | Yes (Primary Feature) |
| Page-Based | page/pageSize. Abstraction over Offset. | Same as Offset-based. | Same as Offset-based. | User-facing UIs where page numbers are intuitive. | Yes |
| Keyset-Based | WHERE id > lastId. Seeks to a key. | Excellent & consistent; leverages indexes. | Stable. Unaffected by writes to other pages. | Large datasets, infinite scroll, high-write environments. | No |
| Cursor-Based | Keyset with an opaque token. | Same as Keyset-based. | Same as Keyset-based. | Public APIs where decoupling the client is important. | No |
| Time-Based | Keyset using a timestamp key. | Excellent, if timestamp is indexed. | Stable, but requires a unique tie-breaker. | Chronological data (feeds, logs, events). | No |
| Hybrid | Combines multiple strategies. | Varies. Can optimize for common paths. | Varies. Can be complex to manage. | Complex UIs needing both infinite scroll and page jumps. | Yes (with trade-offs) |
Conclusion
We’ve seen that pagination is far more than a simple feature for splitting up data. It is a fundamental component of your API’s architecture and its data access strategy. The choice between offset and cursor, transparent and opaque, is a decision that directly impacts scalability, reliability, and the user experience you can deliver.
Therefore, I urge you to treat pagination as a first-class design concern from day one. Before writing a single line of code, think about your data. How large will it get? How often will it change? What kind of navigation experience does your user need?
Choosing the right pagination strategy early is a deliberate act of architectural design. It will save you from painful refactoring, unpredictable performance issues, and late-night production outages. By making this choice consciously, you build APIs that are not just functional for today but are truly built to last.