- 17 Nov, 2025 *
UPDATE: If you want to understand how prompt caching works under the hood, read my blog how prompt caching works - paged attention and prefix caching plus practical tips. This blog is an extract out of that just covering the tips part for readability reasons.
Prompt caching is when LLM providers reuse previously computed key-value tensors for identical prompt prefixes, skipping redundant computation. When you hit the cache, you pay less and get faster responses.
Prompt caching basics and why even worry about it
If you use Codex/Claude Code/Cursor and check the API usage, you will notice a lot of the tokens are "cached". Luckily code is structured and multiple queries can attend to same context/prefixe…
- 17 Nov, 2025 *
UPDATE: If you want to understand how prompt caching works under the hood, read my blog how prompt caching works - paged attention and prefix caching plus practical tips. This blog is an extract out of that just covering the tips part for readability reasons.
Prompt caching is when LLM providers reuse previously computed key-value tensors for identical prompt prefixes, skipping redundant computation. When you hit the cache, you pay less and get faster responses.
Prompt caching basics and why even worry about it
If you use Codex/Claude Code/Cursor and check the API usage, you will notice a lot of the tokens are "cached". Luckily code is structured and multiple queries can attend to same context/prefixes to answer queries so lots of cache hits. This is what keeps the bills in control.
Code generation agents are a good example where the context grows very quickly and your input to output token ratio can be very large (which means prefill/decoding ratio is gonna be large - these are crucial concepts that I will cover in next few sections).

Codex shows cached tokens at end of session
This is where prompt caching saves you. Upto 10x savings on input tokens when the cache hits. You also get faster responses. As you can see in the image below, Sonnet 4.5 costs 1/10th on input tokens on cache hits.
anthropic is so greedy. they literally charge more on base price if you try to use prompt caching lol pic.twitter.com/kXVOw5SNGx
— sankalp (@dejavucoder) November 17, 2025
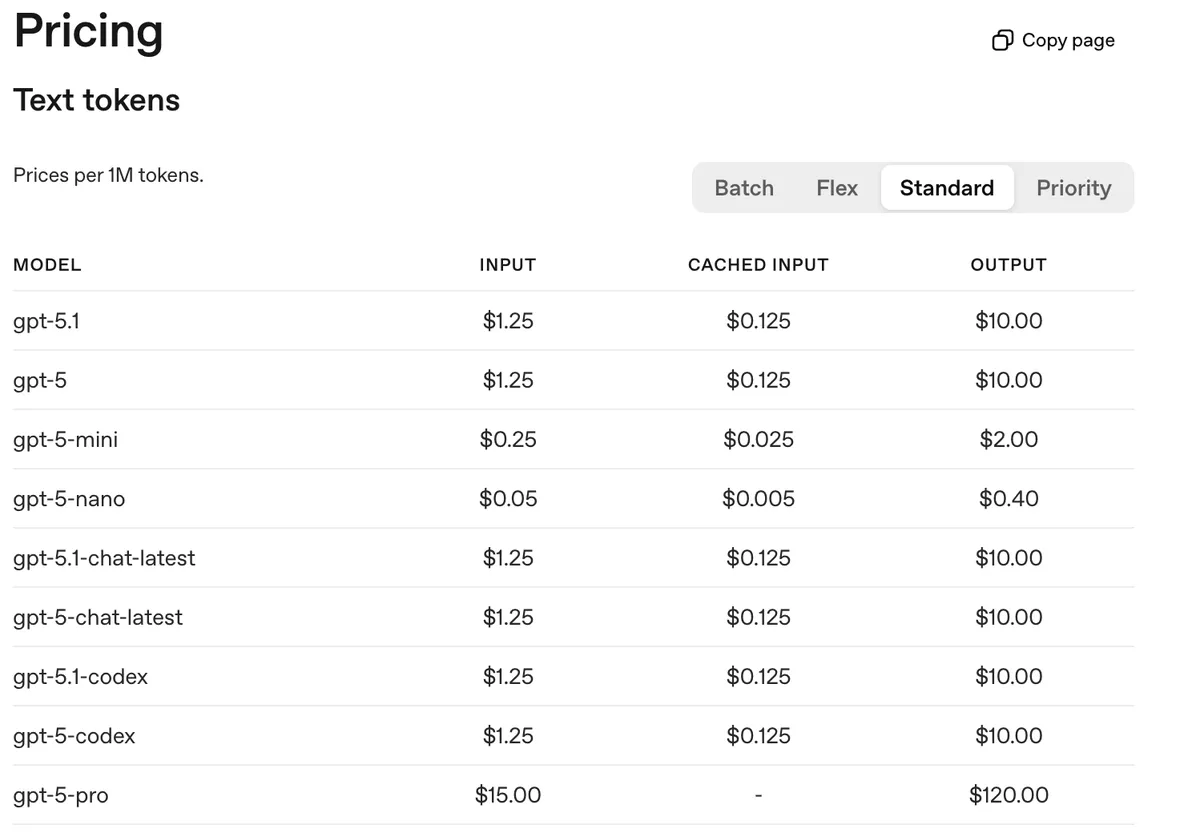
OpenAI prompt caching pricing - note no extra cost for storing tokens in cache
I was calling Anthropic greedy because they charge more for cache writes (and Sonnet/Opus already cost a lot). In comparison, OpenAI doesn’t charge extra. That’s a consumer lens. From a based engineer lens, storing key-value tensors in GPU VRAM or GPU-local storage has a cost - which explains the extra charge, as we’ll see later in this post.
OpenAI recently rolled out 24 hour cache retention policy for the GPT-5.1 series and GPT-4.1 model. By default, cached prefixes stay in GPU VRAM for 5-10 minutes of inactivity. The extended 24hr retention offloads KV tensors to GPU-local storage (SSDs attached to GPU nodes) when idle, loading them back into VRAM on cache hit.
Below are some different type of LLM call patterns where caching can be useful.

KV cache sharing examples. Blue boxes are shareable prompt parts, green boxes are non-shareable parts, and yellow boxes are non-shareable model outputs. Source: SGLang Blog
Tips to improve cache hits
OpenAI and Anthropic offer some tips in their docs. The main idea is to maintain a longest possible stable prefix.

OpenAI suggested practices. Source: OpenAI Docs
Although these tips are not very nuanced and there is a lot of room to make mistakes. A better guide that I found was Manus’ super helpful blog’s, the first section specifically.

Manus context engineering tips. Source: Manus Blog
I read this blog and a couple of other resources and ended up making some changes at the work problem I was yapping about at the start.
Make the prefix stable
I ended up removing all the user specific or dynamic content from my system prompt. This made it possible for other users to hit prompt cache even for the system prompt message as it will be a common prefix in the "kv-cache blocks" (more on this later)
Keep context append-only
In the feature I was building, there could be multiple tool calls and there moderately long outputs were getting stored in the messages array. I thought that this may degrade performance due to context rot for longer conversation so I was truncating just the tool call outputs in the messages array when the conversation got long. But in reality, I was breaking the prefix because of this so I decided to stop mutating because I preferred the cost and latency benefits. Now my context was append-only.
I am guessing Claude Code’s compaction is likely an append only process.
Use deterministic serialization
Manus blog mentions to have deterministic serialization. I ended up using sort_keys=True when serializing JSON in tool call outputs. Even if two objects are semantically identical, different key ordering produces different strings - which means different cache keys and cache misses. I knew about the first two but I didn’t think about this point.

Benchmarking cost difference of prompt caching. Use `sort_keys=True` in `json.dumps()` to ensure consistent key ordering. Source: Ankit’s Blog
Don’t change tool call definitions dynamically
Manus mentioned another important thing to keep in mind - tool call definitions are usually stored before or after the system prompt. Refer here. This means changing or removing certain tool call definitions will break the entire prefix afterwards.
Anthropic recently launched a Tool Search Tool which searches for tools on demand. You don’t need to mention all tools upfront. I wondered if it would break caching because tools usually sit at start or end of system prompt internally. Later I saw in the docs that these tool definitions are "appended" to the context - so it stays append-only.
tool call definitions sit before or after the system prompt so this is a cool approach although i wonder if the model brings up a new tool in middle of execution. won’t it break prompt caching? https://t.co/zVRkU0f5dh
— sankalp (@dejavucoder) November 24, 2025
prompt_cache_key and cache_control
For OpenAI, your API request needs to get routed to the same machine to hit the cache. OpenAI routes based on a hash of the initial prefix (~256 tokens). You can pass a prompt_cache_key parameter which gets combined with this prefix hash, helping you influence routing when many requests share long common prefixes. Note that this is not a cache breakpoint parameter - it’s a routing hint. This is something I need to experiment more with too.
For Anthropic, I think they don’t have automatic prefix caching (not 100% sure) so you need to explicitly mark cache_control breakpoints to tell them where to cache (as mentioned in Manus’ point 3). From each breakpoint, Anthropic checks backwards to find the longest cached prefix, with a 20-block lookback window per breakpoint.