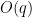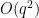Bogdan Georgiev, Javier Gómez-Serrano, Adam Zsolt Wagner, and I have uploaded to the arXiv our paper “Mathematical exploration and discovery at scale“. This is a longer report on the experiments we did in collaboration with Google Deepmind with their AlphaEvolve tool, which is in the process of being made available for broader use. Some of our experiments were already reported on in a [previous white paper](https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorit…
Bogdan Georgiev, Javier Gómez-Serrano, Adam Zsolt Wagner, and I have uploaded to the arXiv our paper “Mathematical exploration and discovery at scale“. This is a longer report on the experiments we did in collaboration with Google Deepmind with their AlphaEvolve tool, which is in the process of being made available for broader use. Some of our experiments were already reported on in a previous white paper, but the current paper provides more details, as well as a link to a repository with various relevant data such as the prompts used and the evolution of the tool outputs.
AlphaEvolve is a variant of more traditional optimization tools that are designed to extremize some given score function over a high-dimensional space of possible inputs. A traditional optimization algorithm might evolve one or more trial inputs over time by various methods, such as stochastic gradient descent, that are intended to locate increasingly good solutions while trying to avoid getting stuck at local extrema. By contrast, AlphaEvolve does not evolve the score function inputs directly, but uses an LLM to evolve computer code (often written in a standard language such as Python) which will in turn be run to generate the inputs that one tests the score function on. This reflects the belief that in many cases, the extremizing inputs will not simply be an arbitrary-looking string of numbers, but will often have some structure that can be efficiently described, or at least approximated, by a relatively short piece of code. The tool then works with a population of relatively successful such pieces of code, with the code from one generation of the population being modified and combined by the LLM based on their performance to produce the next generation. The stochastic nature of the LLM can actually work in one’s favor in such an evolutionary environment: many “hallucinations” will simply end up being pruned out of the pool of solutions being evolved due to poor performance, but a small number of such mutations can add enough diversity to the pool that one can break out of local extrema and discover new classes of viable solutions. The LLM can also accept user-supplied “hints” as part of the context of the prompt; in some cases, even just uploading PDFs of relevant literature has led to improved performance by the tool. Since the initial release of AlphaEvolve, similar tools have been developed by others, including OpenEvolve, ShinkaEvolve and DeepEvolve.
We tested this tool on a large number (67) of different mathematics problems (both solved and unsolved) in analysis, combinatorics, and geometry that we gathered from the literature, and reported our outcomes (both positive and negative) in this paper. In many cases, AlphaEvolve achieves similar results to what an expert user of a traditional optimization software tool might accomplish, for instance in finding more efficient schemes for packing geometric shapes, or locating better candidate functions for some calculus of variations problem, than what was previously known in the literature. But one advantage this tool seems to offer over such custom tools is that of scale, particularly when when studying variants of a problem that we had already tested this tool on, as many of the prompts and verification tools used for one problem could be adapted to also attack similar problems; several examples of this will be discussed below.
Another advantage of AlphaEvolve was robustness: it was relatively easy to set up AlphaEvolve to work on a broad array of problems, without extensive need to call on domain knowledge of the specific task in order to tune hyperparameters. In some cases, we found that making such hyperparameters part of the data that AlphaEvolve was prompted to output was better than trying to work out their value in advance, although a small amount of such initial theoretical analysis was helpful. For instance, in calculus of variation problems, one is often faced with the need to specify various discretization parameters in order to estimate a continuous integral, which cannot be computed exactly, by a discretized sum (such as a Riemann sum), which can be evaluated by computer to some desired precision. We found that simply asking AlphaEvolve to specify its own discretization parameters worked quite well (provided we designed the score function to be conservative with regards to the possible impact of the discretization error); see for instance this experiment in locating the best constant in functional inequalities such as the Hausdorff-Young inequality.
A third advantage of AlphaEvolve over traditional optimization methods was the interpretability of many of the solutions provided. For instance, in one of our experiments we sought to find an extremum to a functional inequality such as the Gagliardo–Nirenberg inequality (a variant of the Sobolev inequality). This is a relatively well-behaved optimization problem, and many standard methods can be deployed to obtain near-optimizers that are presented in some numerical format, such as a vector of values on some discretized mesh of the domain. However, when we applied AlphaEvolve to this problem, the tool was able to discover the exact solution (in this case, a Talenti function), and create code that sampled from that function on a discretized mesh to provide the required input for the scoring function we provided (which only accepted discretized inputs, due to the need to compute the score numerically). This code could be inspected by humans to gain more insight as to the nature of the optimizer. (Though in some cases, AlphaEvolve’s code would contain some brute force search, or a call to some existing optimization subroutine in one of the libraries it was given access to, instead of any more elegant description of its output.)
For problems that were sufficiently well-known to be in the training data of the LLM, the LLM component of AlphaEvolve often came up almost immediately with optimal (or near-optimal) solutions. For instance, for variational problems where the gaussian was known to be the extremizer, AlphaEvolve would frequently guess a gaussian candidate during one of the early evolutions, and we would have to obfuscate the problem significantly to try to conceal the connection to the literature in order for AlphaEvolve to experiment with other candidates. AlphaEvolve would also propose similar guesses for other problems for which the extremizer was not known. For instance, we tested this tool on the sum-difference exponents of relevance to the arithmetic Kakeya conjecture, which can be formulated as a variational entropy inequality concerning certain two-dimensional discrete random variables. AlphaEvolve initially proposed some candidates for such variables based on discrete gaussians, which actually worked rather well even if they were not the exact extremizer, and already generated some slight improvements to previous lower bounds on such exponents in the literature. Inspired by this, I was later able to rigorously obtain some theoretical results on the asymptotic behavior on such exponents in the regime where the number of slopes was fixed, but the “rational complexity” of the slopes went to infinity; this will be reported on in a separate paper.
Perhaps unsurprisingly, AlphaEvolve was extremely good at locating “exploits” in the verification code we provided, for instance using degenerate solutions or overly forgiving scoring of approximate solutions to come up with proposed inputs that technically achieved a high score under our provided code, but were not in the spirit of the actual problem. For instance, when we asked it (link under construction) to find configurations to extremal geometry problems such as locating polygons with each vertex having four equidistant other vertices, we initially coded the verifier to accept distances that were equal only up to some high numerical precision, at which point AlphaEvolve promptly placed many of the points in virtually the same location so that the distances they determined were indistinguishable. Because of this, a non-trivial amount of human effort needs to go into designing a non-exploitable verifier, for instance by working with exact arithmetic (or interval arithmetic) instead of floating point arithmetic, and taking conservative worst-case bounds in the presence of uncertanties in measurement to determine the score. For instance, in testing AlphaEvolve against the “moving sofa” problem and its variants, we designed a conservative scoring function that only counted those portions of the sofa that we could definitively prove to stay inside the corridor at all times (not merely the discrete set of times provided by AlphaEvolve to describe the sofa trajectory) to prevent it from exploiting “clipping” type artefacts. Once we did so, it performed quite well, for instance rediscovering the optimal “Gerver sofa” for the original sofa problem, and also discovering new sofa designs for other problem variants, such as a 3D sofa problem.
For well-known open conjectures (e.g., Sidorenko’s conjecture, Sendov’s conjecture, Crouzeix’s conjecture, the ovals problem, etc.), AlphaEvolve generally was able to locate the previously known candidates for optimizers (that are conjectured to be optimal), but did not locate any stronger counterexamples: thus, we did not disprove any major open conjecture. Of course, one obvious possible explanation for this is that these conjectures are in fact true; outside of a few situations where there is a matching “dual” optimization problem, AlphaEvolve can only provide one-sided bounds on such problems and so cannot definitively determine if the conjectural optimizers are in fact the true optimizers. Another potential explanation is that AlphaEvolve essentially tried all the “obvious” constructions that previous researchers working on these problems had also privately experimented with, but did not report due to the negative findings. However, I think there is at least value in using these tools to systematically record negative results (roughly speaking, that a search for “obvious” counterexamples to a conjecture did not disprove the claim), which currently only exist as “folklore” results at best. This seems analogous to the role LLM Deep Research tools could play by systematically recording the results (both positive and negative) of automated literature searches, as a supplement to human literature review which usually reports positive results only. Furthermore, when we shifted attention to less well studied variants of famous conjectures, we were able to find some modest new observations. For instance, while AlphaEvolve only found the standard conjectural extremizer 
AlphaEvolve did not perform equally well across different areas of mathematics. When testing the tool on analytic number theory problems, such as that of designing sieve weights for elementary approximations to the prime number theorem, it struggled to take advantage of the number theoretic structure in the problem, even when given suitable expert hints (although such hints have proven useful for other problems). This could potentially be a prompting issue on our end, or perhaps the landscape of number-theoretic optimization problems is less amenable to this sort of LLM-based evolutionary approach. On the other hand, AlphaEvolve does seem to do well when the constructions have some algebraic structure, such as with the finite field Kakeya and Nikodym set problems, which we will turn to shortly.
For many of our experiments we worked with fixed-dimensional problems, such as trying to optimally pack