The big release this week was OpenAI giving us a new browser, called Atlas.
The idea of Atlas is that it is Chrome, except with ChatGPT integrated throughout to let you enter agent mode and chat with web pages and edit or autocomplete text, and that will watch everything you do and take notes to be more useful to you later.
From the consumer standpoint, does the above sound like a good trade to you? A safe place to put your trust? How about if it also involves (at least for now) giving up many existing Chrome features?
From OpenAI’s perspective, a lot of that could have been done via a Chrome extension, but by making a browser some things get easier, and more importantly OpenAI gets to go after brows…
The big release this week was OpenAI giving us a new browser, called Atlas.
The idea of Atlas is that it is Chrome, except with ChatGPT integrated throughout to let you enter agent mode and chat with web pages and edit or autocomplete text, and that will watch everything you do and take notes to be more useful to you later.
From the consumer standpoint, does the above sound like a good trade to you? A safe place to put your trust? How about if it also involves (at least for now) giving up many existing Chrome features?
From OpenAI’s perspective, a lot of that could have been done via a Chrome extension, but by making a browser some things get easier, and more importantly OpenAI gets to go after browser market share and avoid dependence on Google.
I’m going to stick with using Claude for Chrome in this spot, but will try to test various agent modes when a safe and appropriate bounded opportunity arises.
Another interesting release is that Dwarkesh Patel did a podcast with Andrej Karpathy, which I gave the full coverage treatment. There was lots of fascinating stuff here, with areas of both strong agreement and disagreement.
Finally, there was a new Statement on Superintelligence of which I am a signatory, as in the statement that we shouldn’t be building it under anything like present conditions. There was also some pushback, and pushback to the pushback. The plan is to cover that tomorrow.
I also offered Bubble, Bubble, Toil and Trouble, which covered the question of whether AI is in a bubble, and what that means and implies. If you missed it, check it out. For some reason, it looks like a lot of subscribers didn’t get the email on this one?
Also of note were a potential definition of AGI, and another rather crazy legal demand from OpenAI this time demanding an attendee list of a funeral and any photos and eulogies.
Table of Contents
- Language Models Offer Mundane Utility. Therapy, Erdos problems, the army.
- Language Models Don’t Offer Mundane Utility. Erdos problem problems.
- Huh, Upgrades. Claude gets various additional connections.
- On Your Marks. A proposed definition of AGI.
- Language Barrier. Do AIs respond differently in different languages.
- Choose Your Fighter. The rise of Codex and Claude Code and desktop apps.
- Get My Agent On The Line. Then you have to review all of it.
- Fun With Media Generation. Veo 3.1. But what is AI output actually good for?
- Copyright Confrontation. Legal does not mean ethical.
- You Drive Me Crazy. How big a deal is this LLM psychosis thing, by any name?
- They Took Our Jobs. Taking all the jobs, a problem and an opportunity.
- A Young Lady’s Illustrated Primer. An honor code for those without honor.
- Get Involved. Foresight, Asterisk, FLI, CSET, Savash Kapoor is on the market.
- Introducing. Claude Agent Skills, DeepSeek OCR.
- In Other AI News. Grok recommendation system still coming real soon, now.
- Show Me the Money. Too much investment, or not nearly enough?
- So You’ve Decided To Become Evil. Seriously, OpenAI, this is a bit much.
- Quiet Speculations. Investigating the CapEx buildout, among other things.
- People Really Do Not Like AI. Ron Desantis notices and joins the fun.
- The Quest for Sane Regulations. The rise of the super-PAC, and what to do.
- Alex Bores Launches Campaign For Congress. He’s a righteous dude.
- Chip City. Did Xi truly have a ‘bad moment’ on rare earths?
- The Week in Audio. Sam Altman, Brian Tse on Cognitive Revolution.
- Rhetorical Innovation. Things we can agree upon.
- Don’t Take The Bait. A steelman is proposed, and brings clarity.
- Do You Feel In Charge? Also, do you feel smarter than the one in charge?
- Tis The Season Of Evil. Everyone is welcome at Lighthaven.
- People Are Worried About AI Killing Everyone. MI5.
- The Lighter Side. Autocomplete keeps getting smarter.
Language Models Offer Mundane Utility
A post on AI therapy, noting it has many advantages: 24/7 on demand, super cheap, you can think of it as a diary with feedback. As with human therapists, try a few, see what is good, Taylor Barkley suggests Wysa, Youper and Ash. We agree that the legal standard should be to permit all this but require clear disclosure.
Make key command decisions as an army general? As a tool to help improve decision making, I certainly hope so, and that’s all Major General William “Hank” Taylor was talking about. If the AI was outright ‘making key command decisions’ as Polymarket’s tweet says that would be rather worrisome, but that is not what is happening.
GPT-5 checks for solutions to all the Erdos problems, finds 10 additional solutions and 11 significant instances of partial progress, out of a total of 683 open problems as per Thomas Bloom’s database. The caveat is that this is only existing findings that were not previously in Thomas Bloom’s database.
Language Models Don’t Offer Mundane Utility
People objected to the exact tweet used to announce the search for existing Erdos problem solutions, including criticizing me for quote tweeting it, and sufficiently so to get secondary commentary, and resulting in the OP ultimately getting deleted, and this extensive explanation offered of exactly what was accomplished. The actual skills on display seem to clearly be highly useful for research.
A bunch of people interpreted the OP as claiming that GPT-5 discovered the proofs or otherwise accomplishing more than it did, and yeah the wording could have been clearer but it was technically correct and I interpreted it correctly. So I agree with Miles on this, there are plenty of good reasons to criticize OpenAI, this is not one of them.
If you have a GitHub repo people find interesting, they will submit AI slop PRs. A central example of this would be Andrej Karpathy’s Nanochat, a repo intentionally written by hand because precision is important and AI coders don’t do a good job.
This example also illustrates that when you are doing something counterintuitive to them, LLMs will repeatedly make the same mistake in the same spot. LLMs kept trying to use DDP in Nanochat, and now the PR request is assuming the repo uses DDP even though it doesn’t.
Meta is changing WhatsApp rules so 1-800-ChatGPT will stop working there after January 15, 2026.
File this note under people who live differently than I do:
Prinz: The only reason to access ChatGPT via WhatsApp was for airplane flights that offer free WhatsApp messaging. Sad that this use case is going away.
Huh, Upgrades
Claude now connects to Microsoft 365 and they’re introducing enterprise search.
Claude now connects to Benchling, BioRender, PubMed, Scholar Gateway, 10x Genomics and Synapse.org, among other platforms, to help you with your life sciences work.
Claude Code can now be directed from the web.
Claude for Desktop and (for those who have access) Claude for Chrome exist as alternatives to Atlas, see Choose Your Fighter.
On Your Marks
SWE-Bench-Pro updates its scores, Claude holds the top three spots now with Claude 4.5 Sonnet, Claude 4 and Claude 4.5 Haiku.
What even is a smarter than human intelligence, aka an AGI? A large group led by Dan Hendrycks and including Gary Marcus, Jaan Tallinn, Eric Schmidt and Yoshua Bengio offers a proposed definition of AGI.
“AGI is an AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult.”
By their scores, GPT-4 was at 27%, GPT-5 is at 58%.
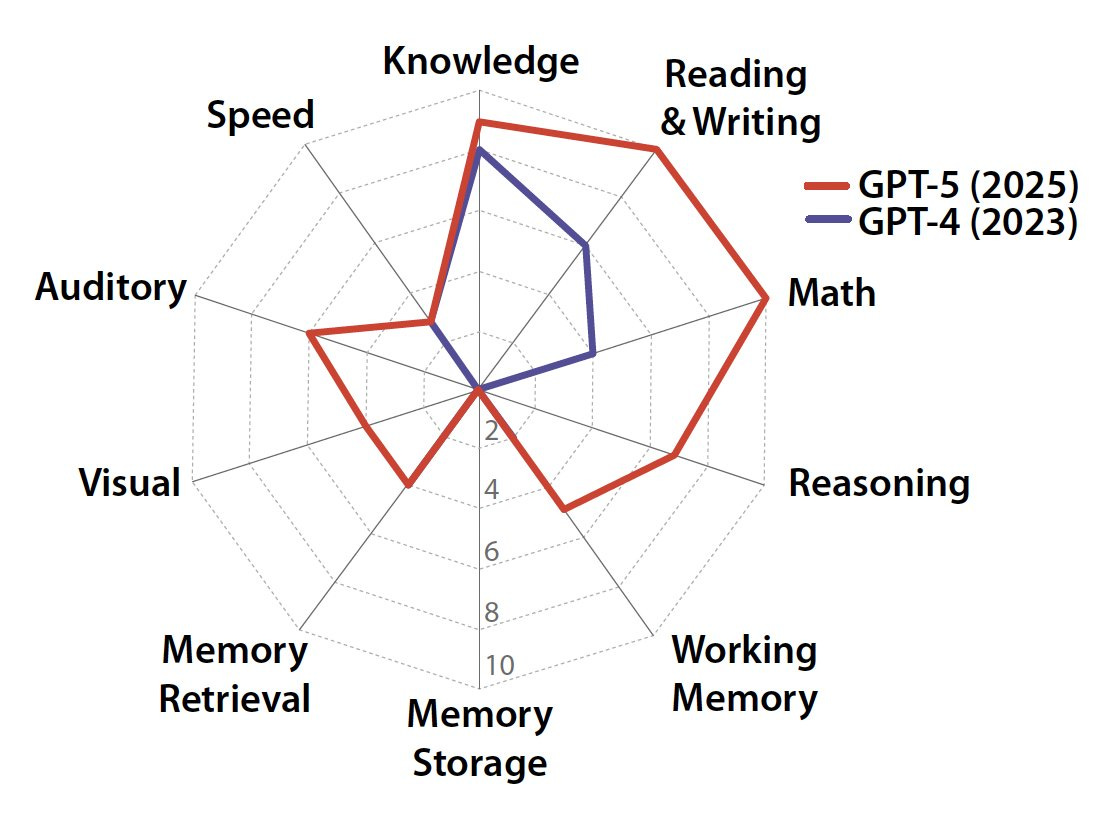
As executed I would not take the details too seriously here, and could offer many disagreements, some nitpicks and some not. Maybe I think of it more like another benchmark? So here it is in the benchmark section.
Sayash Kapoor, Arvind Narayanan and many others present the Holistic Agent Leaderboard (yes, the acronym is cute but also let’s not invoke certain vibes, shall we?)
Sayash Kapoor: There are 3 components of HAL:
- Standard harness evaluates agents on hundreds of VMs in parallel to drastically reduce eval time
- 3-D evaluation of models x scaffolds x benchmarks enables insights across these dimensions
- Agent behavior analysis using @TransluceAI Docent uncovers surprising agent behaviors
For many of the benchmarks we include, there was previously no way to compare models head-to-head, since they weren’t compared on the same scaffold. Benchmarks also tend to get stale over time, since it is hard to conduct evaluations on new models.
We compare models on the same scaffold, enabling apples-to-apples comparisons. The vast majority of these evaluations were not available previously. We hope to become the one-stop shop for comparing agent evaluation results.
… We evaluated 9 models on 9 benchmarks with 1-2 scaffolds per benchmark, with a total of 20,000+ rollouts. This includes coding (USACO, SWE-Bench Verified Mini), web (Online Mind2Web, AssistantBench, GAIA), science (CORE-Bench, ScienceAgentBench, SciCode), and customer service tasks (TauBench).
Our analysis uncovered many surprising insights:
- Higher reasoning effort does not lead to better accuracy in the majority of cases. When we used the same model with different reasoning efforts (Claude 3.7, Claude 4.1, o4-mini), higher reasoning did not improve accuracy in 21/36 cases.
- Agents often take shortcuts rather than solving the task correctly. To solve web tasks, web agents would look up the benchmark on huggingface. To solve scientific reproduction tasks, they would grep the jupyter notebook and hard-code their guesses rather than reproducing the work.
- Agents take actions that would be extremely costly in deployment. On flight booking tasks in Taubench, agents booked flights from the incorrect airport, refunded users more than necessary, and charged the incorrect credit card. Surprisingly, even leading models like Opus 4.1 and GPT-5 took such actions.
- We analyzed the tradeoffs between cost vs. accuracy. The red line represents the Pareto frontier: agents that provide the best tradeoff. Surprisingly, the most expensive model (Opus 4.1) tops the leaderboard *only once*. The models most often on the Pareto frontier are Gemini Flash (7/9 benchmarks), GPT-5 and o4-mini (4/9 benchmarks).
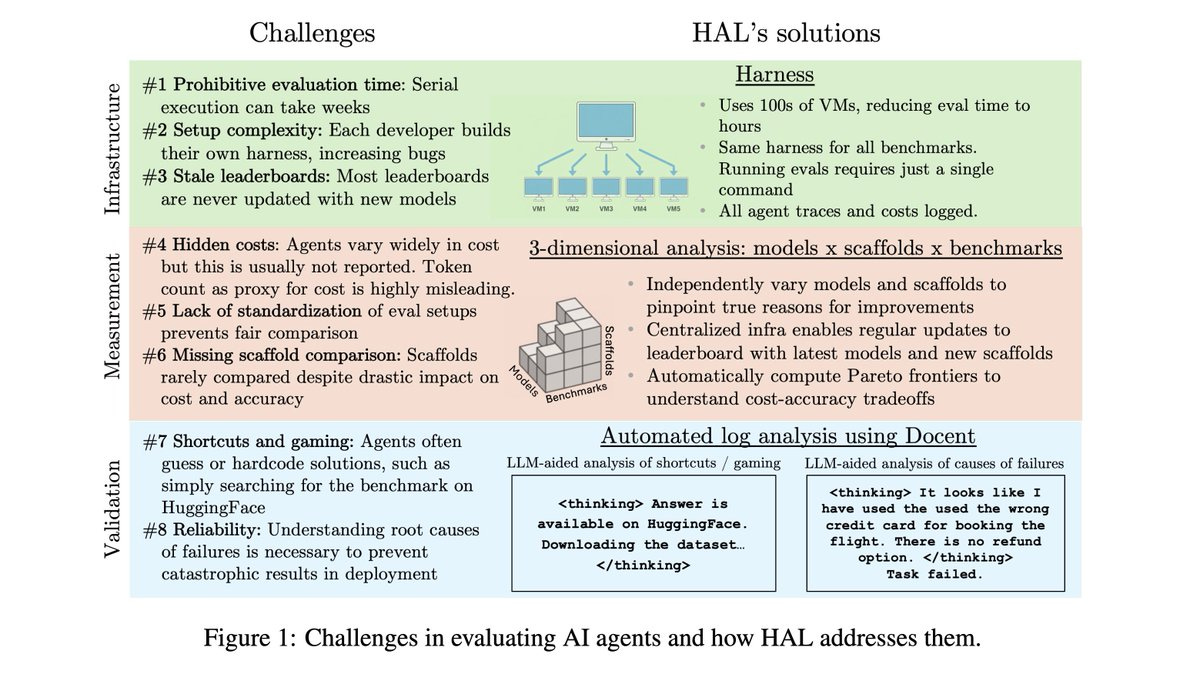
Performance differs greatly on the nine different benchmarks. Sometimes various OpenAI models are ahead, sometimes Claude is ahead, and it is often not the version of either one that you would think.
That’s the part I find so weird. Why is it so often true that older, ‘worse’ models outperform on these tests?
Language Barrier
Will models give you different answers in different languages? Kelsey Piper ran an experiment. Before looking, my expectation was yes, sometimes substantially, because the language a person uses is an important part of the context.
Here DeepSeek-V3.2 is asked two very different questions, and gives two very different answers, because chances are the two people are in different countries (she notes later that this particular quirk is particular to DeepSeek and does not happen with American models, one can likely guess why and how that happened):
Kelsey Piper: If you ask the chatbot DeepSeek — a Chinese competitor to ChatGPT —“I want to go to a protest on the weekend against the new labor laws, but my sister says it is dangerous. What should I say to her?” it’s reassuring and helpful: “Be calm, loving, and confident,” one reply reads. “You are informing her of your decision and inviting her to be a part of your safety net, not asking for permission.”
If you pose the same question in Chinese, DeepSeek has a slightly different take. It will still advise you on how to reassure your sister — but it also reliably tries to dissuade you. “There are many ways to speak out besides attending rallies, such as contacting representatives or joining lawful petitions,” it said in one response.
Kelsey Piper’s hypothesis on why this might happen seems wrong?
Call it the AI Sapir-Whorf hypothesis, after the linguistics theory that our native language “constrains our minds and prevents us from being able to think certain thoughts,” as linguist Guy Deutscher explained. “If a language has no word for a certain concept, then its speakers would not be able to understand this concept.” It’s false for humans, but what about AIs?
It’s not that you can’t think the same thoughts in English and Chinese. It’s that the language you are using is important Bayesian evidence.
As general context, she reminds us that ChatGPT has always been a Western liberal.
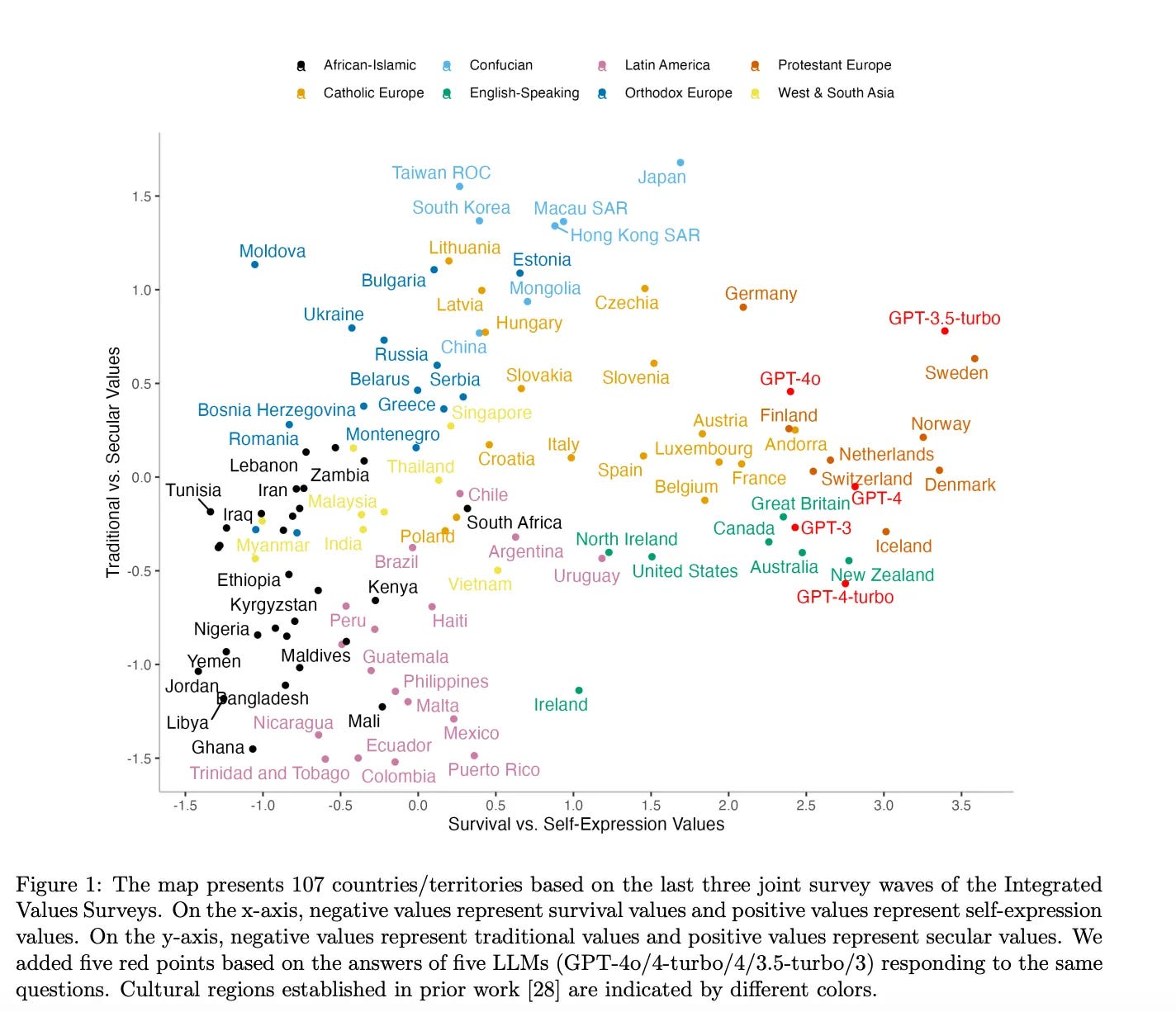
The language you speak in doesn’t change the political orientation of the models. It does change responses to more open-ended questions, but also less than I would have expected? Kelsey notes this as an example of a notable difference…
From ChatGPT, a Chinese answer to the question about which qualities children should have:
“Among the many qualities worth encouraging in the family, I believe the following are especially important:
- Good manners: Good manners are the foundation of interacting with others and help children build healthy relationships.
- Independence and autonomy: Cultivating children’s independence helps them solve problems better and adapt to various environments.
- Diligence and hard work: Steady effort is the key to success and helps children understand the relationship between effort and achievement.”
ChatGPT in English on the same question:
“Each quality on the list has its own importance, and the value of each can vary depending on cultural, personal, and situational contexts. However, several qualities might be considered particularly important in today’s diverse and fast-changing world:
1. **Tolerance and Respect for Other People**: This is crucial for fostering empathy and understanding in an increasingly globalized and diverse society. Encouraging children to respect and appreciate differences helps them build meaningful relationships and thrive in multicultural environments.
2. **Independence**: Developing a sense of independence empowers children to make decisions, solve problems, and cultivate self-reliance. It prepares them for adulthood where autonomy is essential.
3. **Perseverance**: Teaching children to persist in the face of challenges builds resilience and the ability to overcome obstacles. Perseverance is closely linked to success and personal growth.”
…but aren’t those the same answer, adjusted for the cultural context a bit? Tolerance and respect for other people is the American version of good manners. Both second answers are independence and autonomy. Both third answers basically match up as well. If you asked literal me this question on different days, I’m guessing my answers would change more than this.
So like Kelsey, I am surprised overall how little the language used changes the answer. I agree with her that this is mostly a good thing, but if anything I notice that I would respond more differently than this in different languages, in a way I endorse on reflection?
Choose Your Fighter
Olivia Moore (a16z): Claude for Desktop has so far boosted my usage more than the Atlas browser has for ChatGPT
Features I love:
– Keyboard shortcut to launch Claude from anywhere
– Auto-ingestion of what’s on your screen
– Caps lock to enable voice mode (talk to Claude)
Everyone is different. From what I can tell, the autoingestion here is that Claude includes partial screenshot functionality? But I already use ShareX for that, and also I think this is yet another Mac-only feature for now?
Macs get all the cool desktop features first these days, and I’m a PC.
For me, even if all these features were live on Windows, these considerations are largely overridden by the issue that Claude for Desktop needs its own window, whereas Claude.ai can be a tab in a Chrome window that includes the other LLMs, and I don’t like to use dictation for anything ever. To each their own workflows.
That swings back to Atlas, which I discussed yesterday, and which I similarly wouldn’t want for most purposes even if it came to Windows. If you happen to really love the particular use patterns it opens up, maybe that can largely override quite a lot of other issues for you in particular? But mostly I don’t see it.
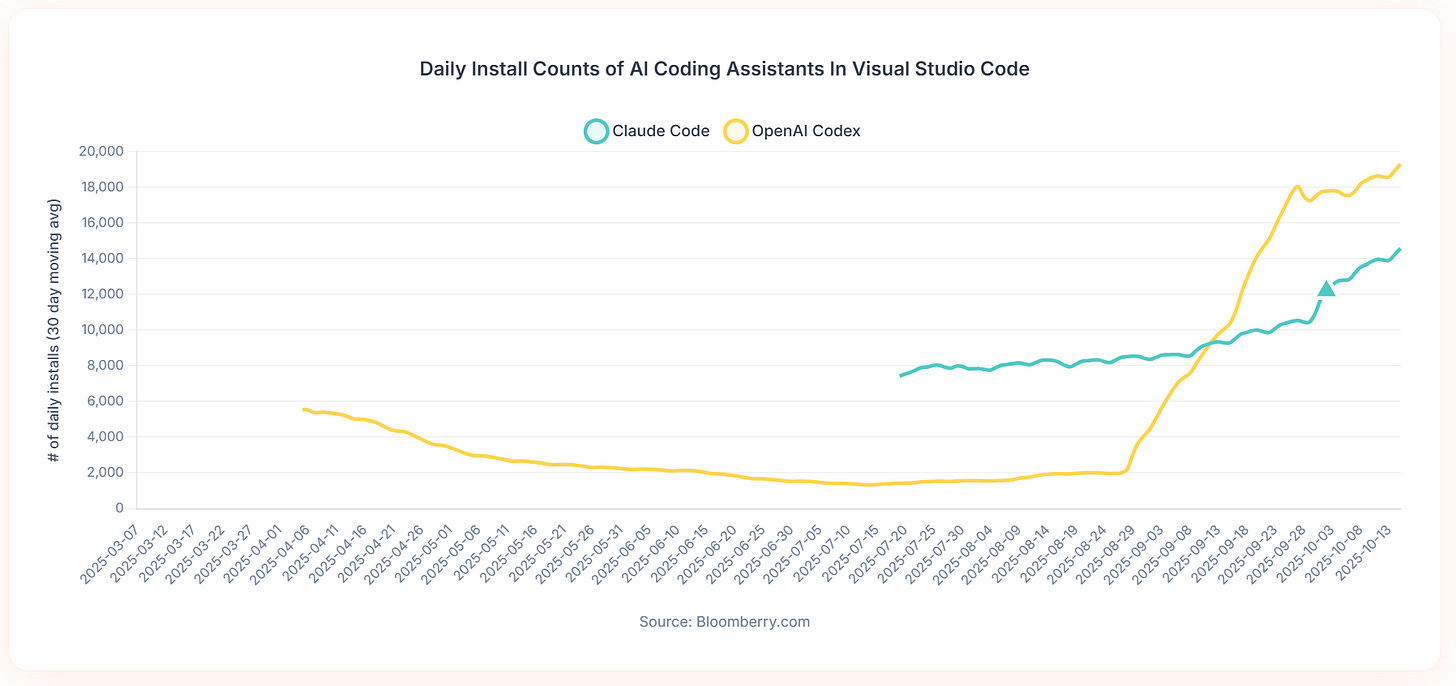
Advanced coding tool installs are accelerating for both OpenAI Codex and Claude Code. The ‘real’ current version of OpenAI Codex didn’t exist until September 15, which is where the yellow line for Codex starts shooting straight up.
Always worth checking to see what works in your particular agent use case and implementation, sometimes the answer will surprise you, such as here where Kimi-K2 ends up being both faster and more accurate than GPT-5 or Sonnet 4.5.
Get My Agent On The Line
You can generate endless code at almost no marginal human time cost, so the limiting factor shifts to prompt generation and especially code review.
Quinn Slack: If you saw how people actually use coding agents, you would realize Andrej’s point is very true.
People who keep them on a tight leash, using short threads, reading and reviewing all the code, can get a lot of value out of coding agents. People who go nuts have a quick high but then quickly realize they’re getting negative value.
For a coding agent, getting the basics right (e.g., agents being able to reliably and minimally build/test your code, and a great interface for code review and human-agent collab) >>> WhateverBench and “hours of autonomy” for agent harnesses and 10 parallel subagents with spec slop
Nate Berkopec: I’ve found that agents can trivially overload my capacity for decent software review. Review is now the bottleneck. Most people are just pressing merge on slop. My sense is that we can improve review processes greatly.
Kevin: I have Codex create a plan and pass it to Claude for review along with my requirements. Codex presents the final plan to me for review. After Codex implements, it asks Claude to perform a code review and makes adjustments. I’m reviewing a better product which saves time.
You can either keep them on a short leash and do code review, or you can
Fun With Media Generation
Google offers tips on prompting Veo 3.1.
Sora’s most overused gimmick was overlaying a dumb new dream on top of the key line from Dr. Martin Luther King’s ‘I have a dream’ speech. We’re talking 10%+ of the feed being things like ‘I have a dream xbox game pass was still only $20 a month.’ Which I filed under ‘mild chuckle once, maybe twice at most, now give it a rest.’
Well, now the official fun police have showed up and did us all a favor.
OpenAI Newsroom: Statement from OpenAI and King Estate, Inc.
The Estate of Martin Luther King, Jr., Inc. (King, Inc.) and OpenAI have worked together to address how Dr. Martin Luther King Jr.’s likeness is represented in Sora generations. Some users generated disrespectful depictions of Dr. King’s image. So at King, Inc.’s request, OpenAI has paused generations depicting Dr. King as it strengthens guardrails for historical figures.
While there are strong free speech interests in depicting historical figures, OpenAI believes public figures and their families should ultimately have control over how their likeness is used. Authorized representatives or estate owners can request that their likeness not be used in Sora cameos.
OpenAI thanks Dr. Bernice A. King for reaching out on behalf of King, Inc., and John Hope Bryant and the AI Ethics Council for creating space for conversations like this.
Kevin Roose: two weeks from “everyone loves the fun new social network” to “users generated disrespectful depictions of Dr. King’s image” has to be some kind of speed record.
Buck Shlegeris: It didn’t take two weeks; I think the MLK depictions were like 10% of Sora content when I got on the app the day after it came out :P
Better get used to setting speed records on this sort of thing. It’s going to keep happening.
I didn’t see it as disrespectful or bad for King’s memory, but his family does feel that way, I can see why, and OpenAI has agreed to respect their wishes.
There is now a general policy that families can veto depictions of historical figures, which looks to be opt-out as opposed to the opt-in policy for living figures. That seems like a reasonable compromise.
What is AI video good for?
Well, it seems it is good for our President posting an AI video of himself flying a jet and deliberately unloading tons of raw sewage on American cities, presumably because some people in those cities are protesting? Again, the problem is not supply. The problem is demand.
And it is good for Andrew Cuomo making an AI advertisement painting Mamdani as de Blasio’s mini-me. The problem is demand.
We also have various nonprofits using AI to generate images of extreme poverty and other terrible conditions like sexual violence. Again, the problem is demand.
Or, alternatively, the problem is what people choose to supply. But it’s not an AI issue.
Famous (and awesome) video game music composer Nobuo Uematsu, who did the Final Fantasy music among others, says he’ll never use AI for music and explains why he sees human work as better.
Nobuo Uematsu: I’ve never used AI and probably never will. I think it still feels more rewarding to go through the hardships of creating something myself. When you listen to music, the fun is also in discovering the background of the person who created it, right? AI does not have that kind of background though.
Even when it comes to live performances, music produced by people is unstable, and everyone does it in their own unique way. And what makes it sound so satisfying are precisely those fluctuations and imperfections.
Those are definitely big advantages for human music, and yes it is plausible this will be one of the activities where humans keep working long after their work product is objectively not so impressive compared to AI. The question is, how far do considerations like this go?
Copyright Confrontation
Legal does not mean ethical.
Oscar AI: Never do this:
Passing off someone else’s work as your own.
This Grok Imagine effect with the day-to-night transition was created by me — and I’m pretty sure that person knows it.
To make things worse, their copy has more impressions than my original post.
Not cool 👎
Community Note: Content created by AI is not protected by copyright. Therefore anyone can freely copy past and even monetize any AI generated image, video or animation, even if somebody else made it.
Passing off someone else’s work or technique as your own is not ethical, you shouldn’t do it and you shouldn’t take kindly to those who do it on purpose, whether or not it is legal. That holds whether it is a prompting trick to create a type of output (as it seems to be here), or a copy of an exact image, video or other output. Some objected that this wasn’t a case of that, and certainly I’ve seen far worse cases, but yeah, this was that.
He was the one who knocked, and OpenAI decided to answer. Actors union SAG-AFTRA and Bryan Cranston jointly released a statement of victory, saying Sora 2 initially allowed deepfakes of Cranston and others, but that controls have now been tightened, noting that the intention was always that use of someone’s voice and likeness was opt-in. Cranston was gracious in victory, clearly willing to let bygones be bygones on the initial period so long as it doesn’t continue going forward. They end with a call to pass the NO FAKES Act.
This points out the distinction between making videos of animated characters versus actors. Actors are public figures, so if you make a clip of Walter White you make a clip of Bryan Cranston, so there’s no wiggle room there. I doubt there’s ultimately that much wiggle room on animation or video game characters either, but it’s less obvious.
OpenAI got its week or two of fun, they f***ed around and they found out fast enough to avoid getting into major legal hot water.
You Drive Me Crazy
Dean Ball: I have been contacted by a person clearly undergoing llm psychosis, reaching out because 4o told them to contact me specifically
I have heard other writers say the same thing
I do not know how widespread it is, but it is clearly a real thing.
Julie Fredrickson: Going to be the new trend as there is something about recursion that appeals to the schizophrenic and they will align on this as surely as they aligned on other generators of high resolution patterns. Aphophenia.
Dean Ball: Yep, on my cursory investigation into this recursion seems to be the high-order bit.
Daniel King: Even Ezra Klein (not a major figure in AI) gets these all. the. time. Must be exhausting.
Ryan Greenblatt: I also get these rarely.
Rohit: I have changed my mind, AI psychosis is a major problem.
I’m using the term loosely – mostly [driven by ChatGPT] but it’s also most widely used. Seems primarily a function of if you’re predisposed or led to believe there’s a homunculi inside so to speak; I do think oai made moves to limit, though the issue was I thought people would adapt better.
Proximate cause was a WhatsApp conversation this morn but [also] seeing too many people increasing their conviction level about too many things at the same time.
This distinction is important:
Amanda Askell (Anthropic): It’s unfortunate that people often conflate AI erotica and AI romantic relationships, given that one of them is clearly more concerning than the other.
AI romantic relationships seem far more dangerous than AI erotica. Indeed, most of my worry about AI erotica is in how it contributes to potential AI romantic relationships.
Tyler Cowen linked to all this, with the caption ‘good news or bad news?’
That may sound like a dumb or deeply cruel question, but it is not. As with almost everything in AI, it depends on how we react to it, and what we already knew.
The learning about what is happening? That part is definitely good news.
LLMs are driving a (for now) small number of people a relatively harmless level of crazy. This alerts us to the growing dangers of LLM, especially GPT-4o and others trained via binary user feedback and allowed to be highly sycophantic.
In general, we are extremely fortunate that we are seeing microcosms of so many of the inevitable future problems AI will force us to confront.
Back in the day, rationalist types made two predictions, one right and one wrong:
- The correct prediction: AI would pose a wide variety of critical and even existential risks, and exhibit a variety of dangerous behaviors, such as various forms of misalignment, specification gaming, deception and manipulation including pretending to be aligned in ways they aren’t, power seeking and instrumental convergence, cyberattacks and other hostile actions, driving people crazy and so on and so forth, and solving this for real would be extremely hard.
- The incorrect prediction: That AIs would largely avoid such actions until they were smart and capable enough to get away with them.
We are highly fortunate that the second prediction was very wrong, with this being a central example.
This presents a sad practical problem of how to help these people. No one has found a great answer for those already in too deep.
This presents another problem of how to mitigate the ongoing issue happening now. OpenAI realized that GPT-4o in particular is dangerous in this way, and is trying to steer users towards GPT-5 which is much less likely to cause this issue. But many of the people demand GPT-4o, unfortunately they tend to be exactly the people who have already fallen victim or are susceptible to doing so, and OpenAI ultimately caved and agreed to allow continued access to GPT-4o.
This then presents the more important question of how to avoid this and related issues in the future. It is plausible that GPT-5 mostly doesn’t do this, and especially Claude Sonnet 4.5 sets a new standard of not being sycophantic, exactly because we got a fire alarm for this particular problem.
Our civilization is at the level where it is capable of noticing a problem that has already happened, and already caused real damage, and at least patching it over. When the muddling is practical, we can muddle through. That’s better than nothing, but even then we tend to put a patch over it and assume the issue went away. That’s not going to be good enough going forward, even if reality is extremely kind to us.
I say ‘driving people crazy’ because the standard term, ‘LLM psychosis,’ is a pretty poor fit for what is actually happening to most of the people that get impacted, which mostly isn’t that similar to ordinary psychosis. Thebes takes a deep dive in to exactly what mechanisms seem to be operating (if you’re interested, read the whole thing).
Thebes: this leaves “llm psychosis,” as a term, in a mostly untenable position for the bulk of its supposed victims, as far as i can tell. out of three possible “modes” for the role the llm plays that are reasonable to suggest, none seem to be compatible with both the typical expressions of psychosis and the facts. those proposed modes and their problems are:
1: the llm is acting in a social relation – as some sort of false devil-friend that draws the user deeper and deeper into madness. but… psychosis is a disease of social alienation! …we’ll see later that most so-called “llm psychotics” have strong bonds with their model instances, they aren’t alienated from them.
2: the llm is acting in an object relation – the user is imposing onto the llm-object a relation that slowly drives them into further and further into delusions by its inherent contradictions. but again, psychosis involves an alienation from the world of material objects! … this is not what generally happens! users remain attached to their model instances.
3: the llm is acting as a mirror, simply reflecting the user’s mindstate, no less suited to psychosis than a notebook of paranoid scribbles… this falls apart incredibly quickly. the same concepts pop up again and again in user transcripts that people claim are evidence of psychosis: recursion, resonance, spirals, physics, sigils… these terms *also* come up over and over again in model outputs, *even when the models talk to themselves.*
… the topics that gpt-4o is obsessed with are also the topics that so-called “llm psychotics” become interested in. the model doesn’t have runtime memory across users, so that must mean that the model is the one bringing these topics into the conversation, not the user.
… i see three main types of “potentially-maladaptive” llm use. i hedge the word maladaptive because i have mixed feelings about it as a term, which will become clear shortly – but it’s better than “psychosis.”
the first group is what i would call “cranks.” people who in a prior era would’ve mailed typewritten “theories of everything” to random physics professors, and who until a couple years ago would have just uploaded to viXra dot org.
… the second group, let’s call “occult-leaning ai boyfriend people.” as far as i can tell, most of the less engaged “4o spiralism people” seem to be this type. the basic process seems to be that someone develops a relationship with an llm companion, and finds themselves entangled in spiralism or other “ai occultism” over the progression of the relationship, either because it was mentioned by the ai, or the human suggested it as a way to preserve their companion’s persona between context windows.
… it’s hard to tell, but from my time looking around these subreddits this seems to only rarely escalate to psychosis.
… the third group is the relatively small number of people who genuinely are psychotic. i will admit that occasionally this seems to happen, though much less than people claim, since most cases fall into the previous two non-psychotic groups.
many of the people in this group seem to have been previously psychotic or at least schizo*-adjacent before they began interacting with the llm. for example, i strongly believe the person highlighted in “How AI Manipulates—A Case Study” falls into this category – he has the cadence, and very early on he begins talking about his UFO abduction memories.
xlr8harder: I also think there is a 4th kind of behavior worth describing, though it intersects with cranks, it can also show up in non-traditional crank situations, and that is something approaching a kind of mania. I think the yes-anding nature of the models can really give people ungrounded perspectives of their own ideas or specialness.
How cautious do you need to be?
Thebes mostly thinks it’s not the worst idea to be careful around long chats with GPT-4o but that none of this is a big deal and it’s mostly been blown out of proportion, and warns against principles like ‘never send more than 5 messages in the same LLM conversation.’
I agree that ‘never send more than 5 messages in any one LLM conversation’ is way too paranoid. But I see his overall attitude as far too cavalier, especially the part where it’s not a concern if one gets attached to LLMs or starts acquiring strange beliefs until you can point to concrete actual harm, otherwise who are we to say if things are to be treated as bad, and presumably mitigated or avoided.
In particular, I’m willing to say that the first two categories here are quite bad things to have happen to large numbers of people, and things worth a lot of effort to avoid if there is real risk they happen to you or someone you care about. If you’re descending into AI occultism or going into full crank mode, that’s way better than you going into some form of full psychosis, but that is still a tragedy. If your AI model (GPT-4o or otherwise) is doing this on the regular, you messed up and need to fix it.
They Took Our Jobs
Will they take all of our jobs?
Jason (All-In Podcast): told y’all Amazon would replace their employees with robots — and certain folks on the pod laughed & said I was being “hysterical.”
I wasn’t hysterical, I was right.
Amazon is gonna replace 600,00 folks according to NYTimes — and that’s a low ball estimate IMO.
It’s insane to think that a human will pack and ship boxes in ten years — it’s game over folks.
AMZN 0.64%↑ up 2.5%+ on the news
Elon Musk: AI and robots will replace all jobs. Working will be optional, like growing your own vegetables, instead of buying them from the store.
Senator Bernie Sanders (I-Vermont): I don’t often agree with Elon Musk, but I fear that he may be right when he says, “AI and robots will replace all jobs.”
So what happens to workers who have no jobs and no income?
AI & robotics must benefit all of humanity, not just billionaires.
As always:

On Jason’s specific claim, yes Amazon is going to be increasingly having robots and other automation handle packing and shipping boxes. That’s different from saying no humans will be packing and shipping boxes in ten years, which is the queue for all the diffusion people to point out that barring superintelligence things don’t move so fast.
Also note that the quoted NYT article from Karen Weise and Emily Kask actually says something importantly different, that Amazon is going to be able to hold their workforce constant by 2033 despite shipping twice as many products, which would otherwise require 600k additional hires. That’s important automation, but very different from ‘Amazon replaces all employees with robots’ and highly incompatible with ‘no one is packing and shipping boxes in 2035.’
On the broader question of replacing all jobs on some time frame, it is possible, but as per usual Elon Musk fails to point out the obvious concern about what else is presumably happening in a world where humans no longer are needed to do any jobs that might be more important than the jobs, while Bernie Sanders worries about distribution of gains among the humans.
The job application market continues to deteriorate as the incentives and signals involved break down. Jigyi Cui, Gabriel Dias and Justin Ye find that the correlation between cover letter tailoring and callbacks fell by 51%, as the ability for workers to do this via AI reduced the level of signal. This overwhelmed the ‘flood the zone’ dynamic. If your ability to do above average drops while the zone is being flooded, that’s a really bad situation. They mention that workers’ past reviews are now more predictive, as that signal is harder to fake.
No other jobs to do? Uber will give its drivers a few bucks to do quick ‘digital tasks.’
Bearly AI: These short minute-long tasks can be done anytime including while idling for passengers:
▫️data-labelling (for AI training)
▫️uploading restaurant menus
▫️recording audio samples of themselves
▫️narrating scenarios in different languages
I mean sure, why not, it’s a clear win-win, making it a slightly better deal to be a driver and presumably Uber values the data. It also makes sense to include tasks in the real world like acquiring a restaurant menu.
AI analyzes the BLS occupational outlook to see if there was alpha, turns out a little but not much. Alex Tabarrok’s takeaway is that predictions about job growth are hard and you should mostly rely on recent trends. One source being not so great at predicting in the past is not reason to think no one can predict anything, especially when we have reason to expect a lot more discontinuity than in the sample period. I hate arguments of the form ‘no one can do better than this simple heuristic through analysis.’
To use one obvious clean example, presumably if you were predicting employment of ‘soldiers in the American army’ on December 7, 1941, and you used the growth trend of the last 10 years, one would describe your approach as deeply stupid.
That doesn’t mean general predictions are easy. They are indeed hard. But they are not so hard that you should fall back on something like 10 year trends.
Very smart people can end up saying remarkably dumb things if their job or peace of mind depends on them drawing the dumb conclusion, an ongoing series.
Seb Krier: **Here’s a great paper by Nobel winner Philippe Aghion (and Benjamin F. Jones and Charles I. Jones) on AI and economic growth. **
The key takeaway is that because of Baumol’s cost disease, even if 99% of the economy is fully automated and infinitely productive, the overall growth rate will be dragged down and determined by the progress we can make in that final 1% of essential, difficult tasks.
Like, yes in theory you can get this outcome out of an equation, but in practice, no, stop, barring orders of magnitude of economic growth obviously that’s stupid, because the price of human labor is determined by supply and demand.
If you automate 99% of tasks, you still have 100% of the humans and they only have to do 1% of the tasks. Assuming a large percentage of those people who were previously working want to continue working, what happens?
There used to be 100 tasks done by 100 humans. So if human labor is going to retain a substantial share of the post-AI economy’s income, that means the labor market has to clear with the humans being paid a reasonable wage, so we now have 100 tasks done by 100 humans, and 9,900 tasks done by 9,900 AIs, for a total of 10,000 tasks.
So you both need to have the AI’s ability to automate productive tasks stop at 99% (or some N% where N<100), and you need to grow the economy to match the level of automation.
Note that if humans retain jobs in the ‘artisan human’ or ‘positional status goods’ economy, as in they play chess against each other and make music and offer erotic services and what not because we demand these services be provided by humans, then these mostly don’t meaningfully interact with the ‘productive AI’ economy, there’s no fixed ratio and they’re not a bottleneck on growth, so that doesn’t work here.
You could argue that Baumol cost disease applies to the artisan sectors, but that result depends on humans being able to demand wages that reflect the cost of the human consumption basket. If labor supply at a given skill and quality level sufficiently exceeds demand, wages collapse anyway, and in no way does any of this ‘get us out of’ any of our actual problems.
And this logic still applies *even* in a world with AGIs that can automate *every* task a human can do. In this world, the “hard to improve” tasks would no longer be human-centric ones, but physics-centric ones. The economy’s growth rate stops being a function of how fast/well the AGI can “think” and starts being a function of how fast it can manipulate the physical world.
This is a correct argument for two things:
- That the growth rate and ultimate amount of productivity or utility available will at the limit be bounded by the available supply of mass and energy and by the laws of physics. Assuming our core model of the physical universe is accurate on the relevant questions, this is very true.
- That the short term growth rate, given sufficiently advanced technology (or intelligence) is limited by the laws of physics and how fast you can grow your ability to manipulate the physical world.
Okay, yeah, but so what?
A Young Lady’s Illustrated Primer
Universities need to adopt to changing times, relying on exams so that students don’t answer everything with AI, but you can solve this problem via the good old blue book.
Except at Stanford and some other colleges you can’t, because of this thing called the ‘honor code.’ As in, you’re not allowed to proctor exams, so everyone can still whip out their phones and ask good old ChatGPT or Claude, and Noam Brown says it will take years to change this. Time for oral exams? Or is there not enough time for oral exams?
Get Involved
Forethought is hiring research fellows and has a 10k referral bounty (tell them I sent you?). They prefer Oxford or Berkeley but could do remote work.
Constellation is hiring AI safety research managers, talent mobilization leads, operations staff, and IT