 I’m on the right, biting a nail nervously. We’re in an Italian hotel because this happened on day 1 of our offsite.
I’m on the right, biting a nail nervously. We’re in an Italian hotel because this happened on day 1 of our offsite.
On Monday the AWS us-east-1 region had its worst outage in over 10 years. The whole thing lasted over 16 hours and affected 140 AWS services, including, critically, EC2. SLAs were blown, an eight-figure revenue reduction will follow. Before Monday, I’d spent around 7 years in industry and never personally had production nuked by a public cloud outage. I generally regarded AWS’s reliability as excellent, industry-leading.
What the hell happened?
A number of smart engineers have come to this major bust-up and covered it with the blanket of a simple explanation…
I’m on the right, biting a nail nervously. We’re in an Italian hotel because this happened on day 1 of our offsite.
On Monday the AWS us-east-1 region had its worst outage in over 10 years. The whole thing lasted over 16 hours and affected 140 AWS services, including, critically, EC2. SLAs were blown, an eight-figure revenue reduction will follow. Before Monday, I’d spent around 7 years in industry and never personally had production nuked by a public cloud outage. I generally regarded AWS’s reliability as excellent, industry-leading.
What the hell happened?
A number of smart engineers have come to this major bust-up and covered it with the blanket of a simple explanation: brain drain; race condition; it’s always DNS; the cloud is unreliable, go on-prem. You’re not going to understand software reliability if you can summarize an outage of this scale in an internet comment. Frankly, I’m not even going to understand it after reading AWS’s 4000 word summary and thinking about it for hours. But I’m going to hold the hot takes and try.
I wrote Modal’s internal us-east-1 incident postmortem before AWS published their “service disruption summary”: https://aws.amazon.com/message/101925. Our control plane being in us-east-1, we got hit hard. Along with hundreds of other affected companies, we’re interested in a peek under the hood of the IaaS we depend on.
Arriving a few days after the outage, this public summary is a small window into the inner workings of the most experienced hyperscaler engineering operation in the world. I’ll analyze each of the three outage phases, call out key features, and then try, with limited information, to derive a lesson or two from this giant outage. Before proceeding, it is recommended to read the summary carefully.
Out of one service outage, one hundred and forty service outages are born
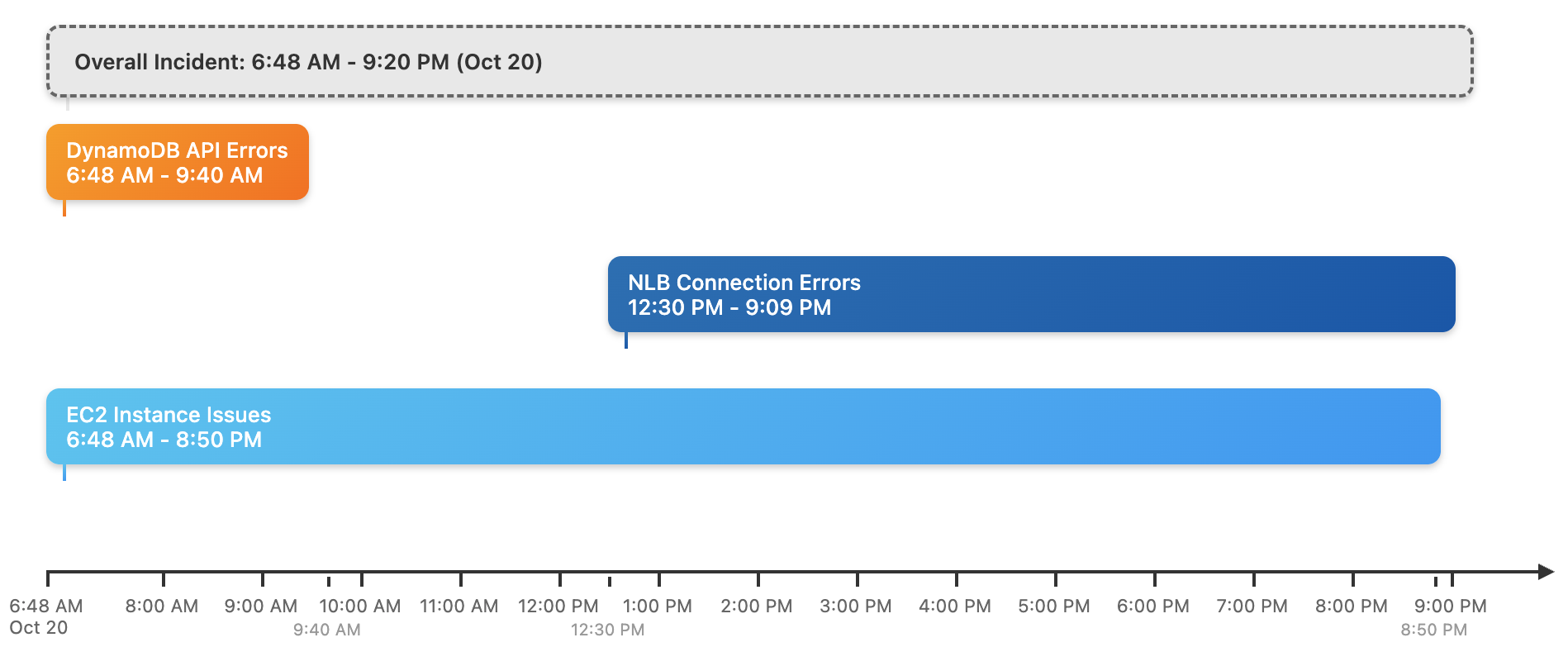
How did a DynamoDB service failure at 6:48AM UTC October 20th become a 140 service failure epidemic?
AWS breaks down their summary into dedicated sections for the DynamoDB, EC2, and Network Load Balancer (NLB) services. They add a final section lumping together the other 137 affected services (which included Lambda, IAM, STS, Elasticache, ECR, Secrets Manager).
This document structure is suitable as it matches the structure of the outage.
DynamoDB precipitated all other service failures because it is used by EC2 and caused EC2 to go down, or because a service depended on DynamoDB directly. EC2 and DynamoDB are used extensively within AWS for service implementation, thus the wildfire spread to around 70% of all AWS services in the us-east-1 region.
It is widely known that AWS dogfoods its own cloud services, e.g. DynamoDB, for the implementation of Amazon.com and other AWS services. DynamoDB and EC2 are ‘layer zero’ bedrock services within AWS. If they go down, basically everything else does.
A simple race condition
The root cause of this issue was a latent race condition in the DynamoDB DNS management system that resulted in an incorrect empty DNS record for the service’s regional endpoint (dynamodb.us-east-1.amazonaws.com) that the automation failed to repair.
It is unsurprising that AWS DynamoDB maintains a large-scale, automated DNS load balancing system to serve dynamodb.us-east-1.amazonaws.com, perhaps the most hammered endpoint in SaaS behind s3.us-east-1.amazonaws.com.
What is surprising is that a classic Time-of-check-time-of-use (TOCTOU) bug was latent in their system until Monday. Call me naive, but I thought AWS, an organization running a service that averages 100 million RPS, would have flushed out TOCTOU bugs from their critical services.
In an eye straining 786 word mega-paragraph, they outline their issues, which I will try summarize.
To maintain population of all DNS entries for dynamodb.us-east-1.amazonaws.com, they run three DNS Enactors, one in each of in us-east-1a, us-east-1b, us-east1c. Each of these three Enactors performs mutations without coordination.
For resiliency, the DNS Enactor operates redundantly and fully independently in three different Availability Zones (AZs).
One of these Enactors, say us-east-1a, became extremely slow. They don’t say anything about the cause of the latency, but it believe it was extreme (10-100x) because the system design seems to allow for some deviation from mean latency.
They use a typical “keep last N” garbage collection mechanism to remove old DNS plans. We also do this at Modal to garbage collect old machine images. Crucially, the last N must never include an active resource. I assume the DynamoDB team picked a large N to ensure they ‘never’ delete an active plan, which implies the Enactor’s latency in us-east-1a was extreme.
To a first approximation, we can say that accidents are almost always the result of incorrect estimates of the likelihood of one or more things. — Why you should read accident reports, Holloway, C. Michael
The plan being applied by the slow Enactor fell out of the N generations safety window and became old, eligible for deletion. It was the old plan deletion which turned a ‘stale DNS plan’ degradation into a full-blown ‘zero DNS entries’ outage.
Now, back to the TOCTOU issue. Why is an Enactor allowed to make only one plan staleness check for N plan mutations? I suspect it’s because querying the DNS Planner for staleness is magnitudes more expensive than making a plan mutation. It would be non-performant, and seemingly unnecessary*,* to make N checks for N fast plan mutations.1
Without this TOCTOU bug, there’s no ‘stale DNS plan’ degradation and thus no opportunity to mistakenly delete an old plan.2
We’re at two faults so far, but there’s more. Using the Swiss cheese model of accident causation we can pass through a couple more Emmental holes.
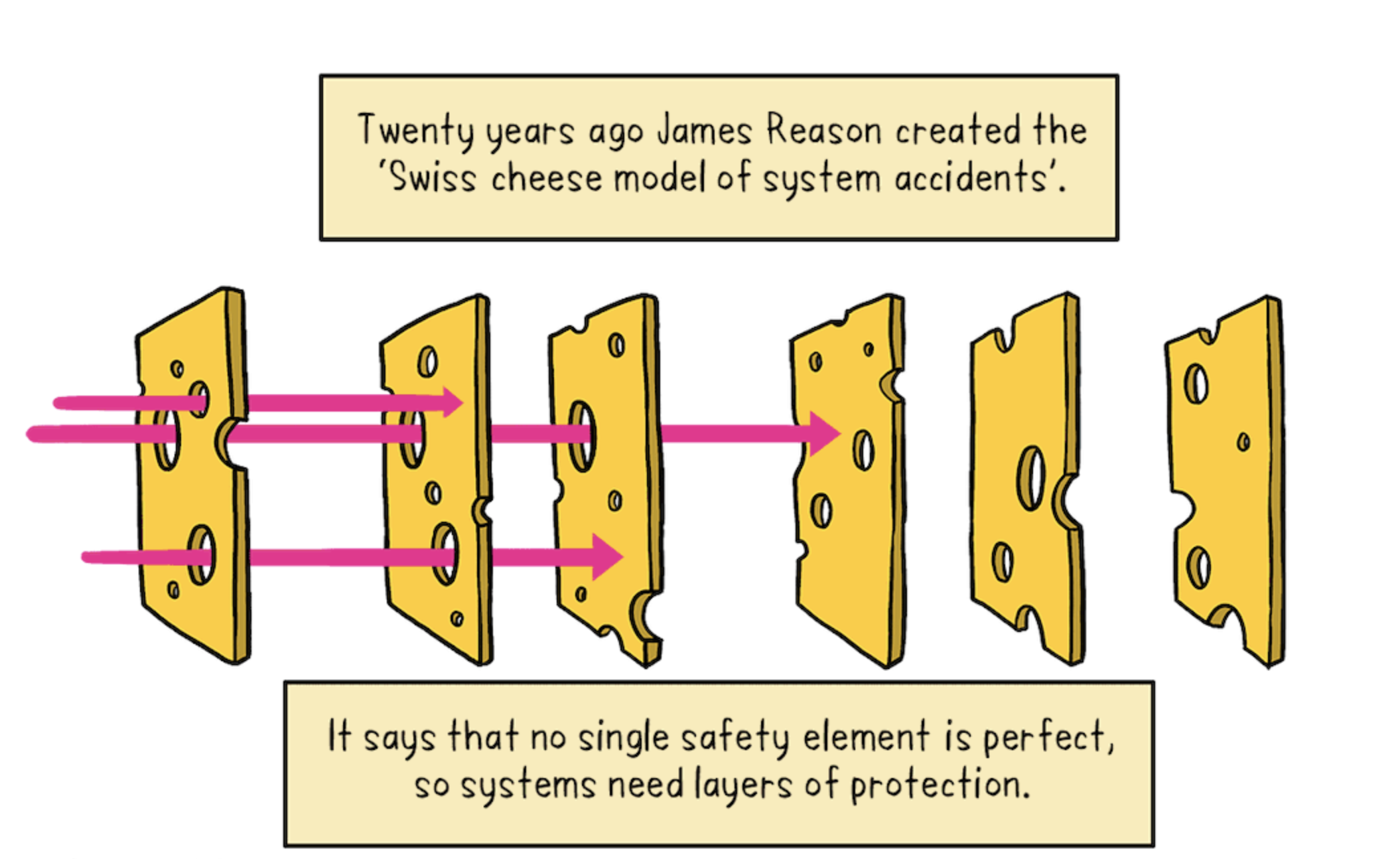
Deleting the active plan is a disaster, but the Enactor’s cleanup phase didn’t check for it. This absent guard appears to be another fault.
Some have pointed out that the Enactor deleting the Planner’s plans is weird, but I think it makes sense. The Planner is allowed to be a straightforward append-only system of outputs. The Enactor makes forward progress against the plan log and maintains the window of active DNS records. If the Planner is deleting plans, it’s also making writes against Route53.
After deleting the ‘active’ plan, the Enactor state was corrupted and unrecoverable without “manual operation intervention”, which took over 2 hours to be done.
It is surprising that this corruption and DNS ‘empty state’ was not auto-recovered. dynamodb.us-east-1.amazonaws.com had zero IP addresses associated. In production that’s a pants-on-fire situation. Could the Enactors not have fallen back to some useful, non-empty state and restored partial service?
Anyone considering this system failure outside the DynamoDB team has the struggle of keyhole observation added to the problem of hindsight bias. I won’t have the temerity to suggest remediation, or declare a root cause. But there is much that is familiar in the DynamoDB DNS failure, and I’ll be looking for it in future design documents.
A root cause
The selection of events to include in an event chain is dependent on the stopping rule used to determine how far back the sequence of explanatory events goes. Although the first event in the chain is often labeled the initiating event or root cause , the selection of an initiating event is arbitrary and previous events and conditions could always be added. — Engineering a safer world
Having read the DynamoDB section of the summary, some are tempted to declare discovery of the root cause: a race condition.
The software industry today holds the root cause analysis (RCA) as a primary activity of postmortem write ups. Google “postmortem template” and almost every offered template includes a section for root cause(s) analysis. The top result, Atlassian’s, includes it. A couple year’s ago Atlassian’s is what I found and copied as Modal’s internal template.
But leading reliability engineers have moved on from centering root cause analysis. It is useful, but an inadequate model of incident occurrence.
Most obviously, RCA has an infinite regress problem. The cause of the extreme Enactor latency in one AZ is unexplained, but it is is antecedent to the race condition and could be considered a root cause. But, say the latency was causes by high packet drop, what caused that? On and on we go, boast against the current—
More interestingly, however, is the myopia induced by RCA. Yes, the extreme latency trigger the race condition bug. It was a precipitating event, but it is just one of many latent faults that could emerge from the dynamics of the DynamoDB system. And as shown above by the Swiss cheese analysis, multiple control mechanisms combined into an unrecoverable failure once the latency emerged.
Today’s leading distributed systems engineers, including the SRE’s at Google, analyze failure as a control problem.
Instead of asking “What software service failed?” we ask “What interactions between parts of the system were inadequately controlled? — The Evolution of SRE at Google
Looking for a control problem, we see not just the race condition deletion, but the latency, the garbage collection, the guarding (or lack thereof), the state corruption, the alerting, and the human operator.
This incident summary contains perhaps the first public reference to an AWS Droplet and the DropletWorkflow Manager (DWFM). Droplets are physical servers upon which all EC2 instances run.
The DWFM depends on DynamoDB to complete “state checks”, which are heartbeats between DWFM and every physical server managed. If the heartbeat with a server stops, the DWFM’s control of the server is cut off. Without this control, no creation or state transition can occur on an EC2 instance, affecting every EC2 user in us-east-1 except those which left all their instances RUNNING between 6:48AM and 8:50PM UTC. Yikes.
DynamoDB is a critical dependency of the DWFM and triggered the EC2 service failure. But it gets interesting once DynamoDB recovers around 9:40AM UTC. EC2 is down or degraded for another 11 hours.
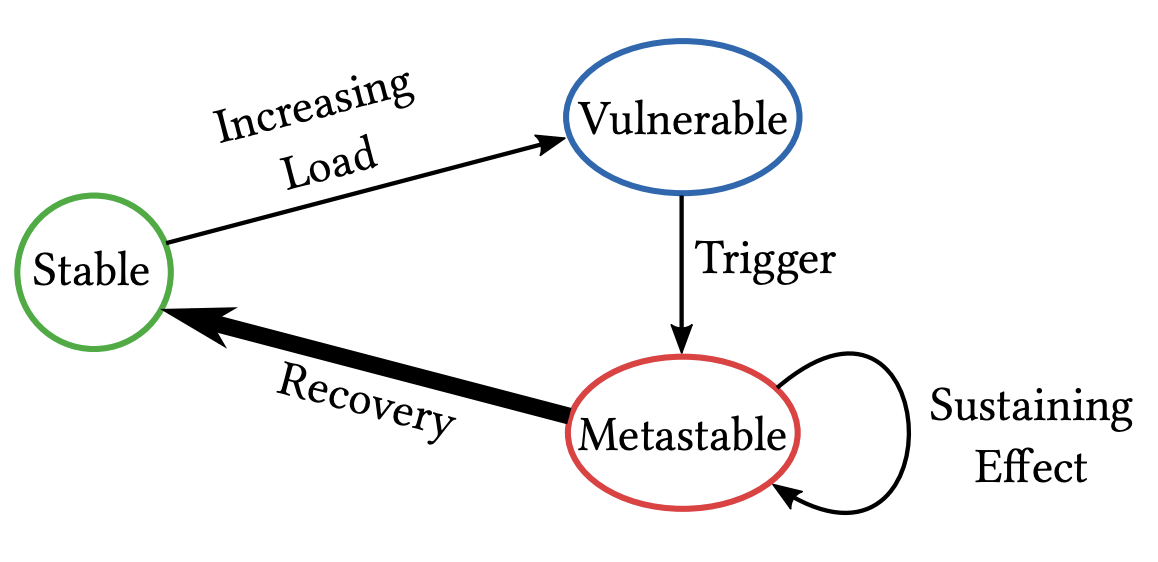 States and transitions of a system experiencing a metastable failure. From *Metastable Failures in Distributed Systems.
States and transitions of a system experiencing a metastable failure. From *Metastable Failures in Distributed Systems.
In normal operation of EC2, the DWFM maintains a large number (~10^6) of active leases against physical servers and a very small number (~10^2) of broken leases, the latter of which the manager is actively attempting to reestablish.
The DynamoDB outage, which lasted almost 3 hours, caused widespread heartbeat timeouts and thus thousands of leases broke. I’d estimate that the number of broken leases reached at least 10^5, or three OOMs larger than normal.
With a huge queue of leases to reestablish, the DWFM system has two possible transitions. One is a slow, gradual burn down of the lease backlog (recovery). The other is a congestive collapse, where the lease queue remains high (a “sustaining effect”) until manual intervention.
Unfortunately, the DWFM entered congestive collapse.
…, due to the large number of droplets, efforts to establish new droplet leases took long enough that the work could not be completed before they timed out. — AWS Summary
It’s most interesting here to consider why collapse occurred. Was the unit of work completion somehow O(queue depth), ie. instead of processing one lease at a time the DWFM processes an all-or-nothing block of leases? Or, did the DWFM become a thundering herd and overwhelm a downstream component between it and the Droplets?
The congestive collapse of EC2 could only be restored by manual intervention by engineers, where they restarted DWFM servers presumably to drop the in-memory queued lease work and restore goodput in the system.
For a while now I’ve eagerly followed the public blogging of Marc Brooker, a distinguished engineer at AWS with key contributions to Lambda, EBS, and EC2. I’m sure he’s wired up after this outage, because he has been evangelizing the analysis of metastable failure for years now.
The presence and peril of the metastable failure state has likely been widely known within AWS engineering leadership for around 4 years. And yet it bit them in their darling EC2. I eagerly await the blog post, Marc.
NLB
At around 16:00 UTC in the now internally famous #incident-41-hfm_failures incident channel I began investigating a degradation in our Sandbox product. It turned out that AWS NLB trouble was causing Modal clients to fail to establish a gRPC connection with api.modal.com (which points at NLB load balancers).
The NLB service went down because EC2 has a Network Manager responsible for propagating network configuration when new EC2 instances are created or instance transitions (e.g. stopping) occur, and this manager fell behind under the weight of backlogged work.
The most interesting bit of the NLB service outage was that the NLB healthcheck system received bad feedback because of network configuration staleness and incorrectly performed AZ failovers.
The alternating health check results increased the load on the health check subsystem, causing it to degrade, resulting in delays in health checks and triggering automatic AZ DNS failover to occur.
Under control systems analysis, the potential for bad feedback is exactly the kind of thing that gets designed for. The healthcheck system behaved exactly as intended giving the inputs it received— it was a reliable component interacting unsafely with a broken environment.
In their discussion of remediations, the line item for NLB is about control for bad feedback.
For NLB, we are adding a velocity control mechanism to limit the capacity a single NLB can remove when health check failures cause AZ failover.
Humble conclusions
You only get so many major AWS incidents in your career, so appreciate the ones that you get. AWS’s reliability is the best in the world. I have used all major US cloud providers for years now, and until Monday’s us-east-1 outage AWS was clearly the most reliable. This is perhaps their biggest reliability failure in a decade. We should learn something from it.
I disagree with the popular early explanations. The “brain drain” theory has a high burden of proof and very little evidence. It possible that brain drain delayed remediation—this was a 14 hour outage—but we can’t see their response timeline. There’s also no evidence that us-east-1, being the oldest region, suffered from its age.3 The systems involved (DynamoDB, DNS Enactor, DWFM) are probably running globally. Also, those suggesting AWS’s reliability has fallen behind its competitors are too hasty. GCP had a severe global outage just last June.
My main takeaway is that in our industry the design, implementation, and operation of production systems still regularly falls short of what we think we’re capable of. DynamoDB hit a fairly straightforward race condition and entered into unrecoverable state corruption. EC2 went into congestion collapse. NLB’s healthcheck system got misdirected by bad data. We’ve seen these before, we’ll see them again. We’re still early with the cloud.
Software systems are far more complex and buggy than we realize. Useful software systems, such as EC2, always operate in a degraded state with dozens of present or latent bugs and faults. The presence of constant safety, of the cherished five 9s, is not a miracle, but a very challenging design and operational endeavor.
Monday was a bad day for hyper-scaled distributed systems. But in in the long run the public cloud industry will root out its unsound design and operation. Today’s advanced correctness and reliability practices will become normal.
After writing this, I’m now doubting it. It’s also plausible that the TOCTOU bug existed for no good reason. ↩ 1.
Some commentators on the incident have noted that stale writes would be avoided with locking and fencing tokens, but AWS did note that for “resilience” the enactors are not allowed to coordinate (via a distributed locking service). ↩ 1.
I would say however that us-east-1 has notably more outages than other regions (eg. us-east-2) and should be avoided where possible. I believe it’s relevant that us-east-1 is by far the biggest and most complex AWS region. In future I will avoid us-east-1 when capacity and new features aren’t important concerns. ↩