In 2016, DeepMind famously used self-play with reinforcement learning (RL) to build AlphaGo. They trained their model by making it play against slightly older versions of itself. This steadily increased the difficulty of game states encountered, and more formally, induced an automatic curriculum - autocurricula - of tasks.
Despite the success of self-play in training AlphaGo, we have not yet widely used self-play to train language models. Andrej Karpathy explored the problem in more detail on the Dwarkesh Patel podcast: “there’s no equivalent of self-play in LLMs. Why can’t an LLM, for example, create a bunch of problems that another LLM is learning to solve? Then the LLM is always t…
In 2016, DeepMind famously used self-play with reinforcement learning (RL) to build AlphaGo. They trained their model by making it play against slightly older versions of itself. This steadily increased the difficulty of game states encountered, and more formally, induced an automatic curriculum - autocurricula - of tasks.
Despite the success of self-play in training AlphaGo, we have not yet widely used self-play to train language models. Andrej Karpathy explored the problem in more detail on the Dwarkesh Patel podcast: “there’s no equivalent of self-play in LLMs. Why can’t an LLM, for example, create a bunch of problems that another LLM is learning to solve? Then the LLM is always trying to serve more and more difficult problems”.
A couple of early forays have emerged from academia. Natasha Jaques’ Spiral solves zero sum games like TicTacToe, and Andrew Zhao’s AbsoluteZero shows impressive results on math problems. However, we are yet to witness anything approaching industrial scale and reliability. Noam Brown, a leading OpenAI research scientist who applied autocurricula to beat Diplomacy and Poker, recently underlined the difficulty of this problem: “self-play works for two player zero sum games…like Go, Poker and Starcraft but is so much harder to use in real world domains”.
This blog post explains from the ground-up why we should care about using autocurricula to train digital agents, and explores how unsupervised environment design and evolutionary algorithms might help us get there.
**Reinforcement Learning is all the rage **
Over the last few years, the path for training foundation models has settled into a seemingly stable pattern:
- We first use self-supervised learning with a next-token prediction objective on internet scale data to induce strong priors over perception and language.
- Next, we perform supervised fine-tuning (SFT) on a largely synthetic instruction-following dataset to make the model capable of answering questions rather than simply continuing text indefinitely.
- Finally, we further post-train the model with reinforcement learning against both human preferences, verifiable rewards, and model verifiers. This both ensures user satisfaction is maximized and elicits variable length reasoning to solve complex problems that go beyond the distribution of known human behavior, ergo improving domain adaptation and creativity.
The importance of this last step cannot be overstated. Improvements in RL are responsible for many of the advances frontier models have made in the last few years.
Given the success of this recipe, many AI labs are trying to scale reinforcement learning. They are all increasing their compute spend, the number of environments for agents to train in, and the corresponding tasks to solve. Several data vendors, such as Mercor and Mechanize, have even published position pieces claiming RL environments, ranging from virtual sandboxes to simulated workspaces, will be built for most knowledge sector work. Suffice it to say, RL is so hot right now.
Environments and tasks
As a refresher, reinforcement learning environments define the world the agent sees, and more specifically:
- The states an agent can visit, such as various webpages on an airline website.
- The actions they can take, such as pressing click on a particular pixel.
- The transition function between states, actions, and the subsequent observed state. For example, successfully clicking the sign out button on the sign out page of a website would navigate to the home page.
The actual tasks that agents solve within an environment are defined by their initial starting state, the intended goal state, and the corresponding reward function for that trajectory. Therefore, it is possible to have many tasks in a given environment. For example, an environment could define how I navigate all aspects of Expedia.com and ten different tasks could be navigating from the home screen to booked flights in ten capital cities, with a scalar reward of 1 or 0 depending on success or failure in each case.
Curriculum design
As these labs begin to scale the number of environments – and consequently tasks to solve – for RL agents, a natural next question to ask is: in what order should these tasks be learned? Humans do not learn in school by picking tasks randomly; they instead attack goals in an organized, staged manner. Intuitively, models may benefit from a similar strategy. For example, it probably makes more sense to teach an agent basic mathematics before making it fix a DCF model in Excel. This is because the former simpler skill can be modularly re-applied to solve components of the latter higher order problem.
In 2009, Yoshua Bengio formalized this problem as curriculum learning. He showed that when training examples are ordered from easy to hard, convergence is faster and the quality of local minima is higher. This is because less time is wasted with noisy, harder to predict examples and training is instead guided towards better regions of parameter space (called basins of attraction). He even performed his experiments with language models, specifically trying to predict the next word given a context of previous words. Talk about being ahead of your time!
Learning at the learnable frontier
Today, frontier labs are already reaping the benefits of curriculum design when performing RL over foundation models. The rationale and performance gains were nicely explained in Kimi-k1.5’s technical report released in June 2025. They noticed that some tasks are already labelled as trickier than others (e.g. International Mathematical Olympiad problems are obviously harder than primary school math) so they can use curriculum sampling to start training on easier tasks then move to harder tasks. A well designed curriculum lets the agent more easily and consistently access reward across a sequence of tasks, and their method improved accuracy by over 5 percentage points across 15 training iterations.
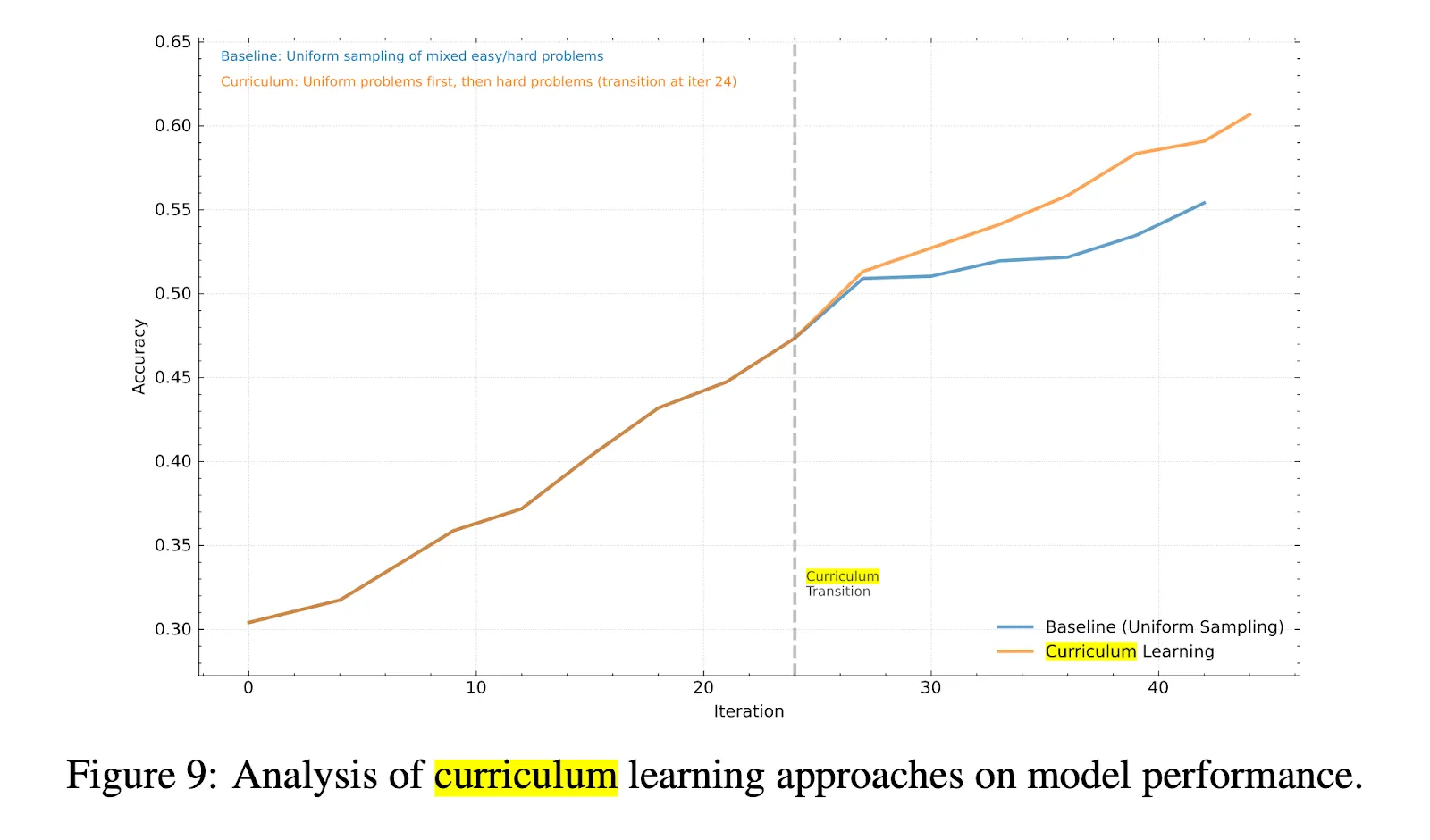
However, soon a problem begins to surface: as models get smarter, the marginal information gain from showing tasks based on what humans find easy or difficult is less than the potential information gain from showing tasks based on what the model finds easy or difficult. Put another way, we need to zero in on what the actual model is ready to learn next based on its own definition of easy or difficult, a region called its learnable frontier. Otherwise we are needlessly wasting compute and being inefficient. Models and humans view the world differently, a fact often lost in our anthropomorphization of neural networks.
In this vein, the Kimi-k1.5 team noted they can track the success rate on each problem during RL training. They use prioritized sampling to adaptively focus compute on problems with lower success rates. Although this method works, research here is still nascent. Techniques such as LILO by Thomas Foster in July 2025 have already replaced success rate as a metric of difficulty with the variance of the success rate as a measure of task learnability. In this work, each training batch samples a percentage of maximally learnable tasks, and randomly samples the rest to ensure new problems are always encountered. Not only did final accuracy improve, but training converged in 3x fewer training steps!
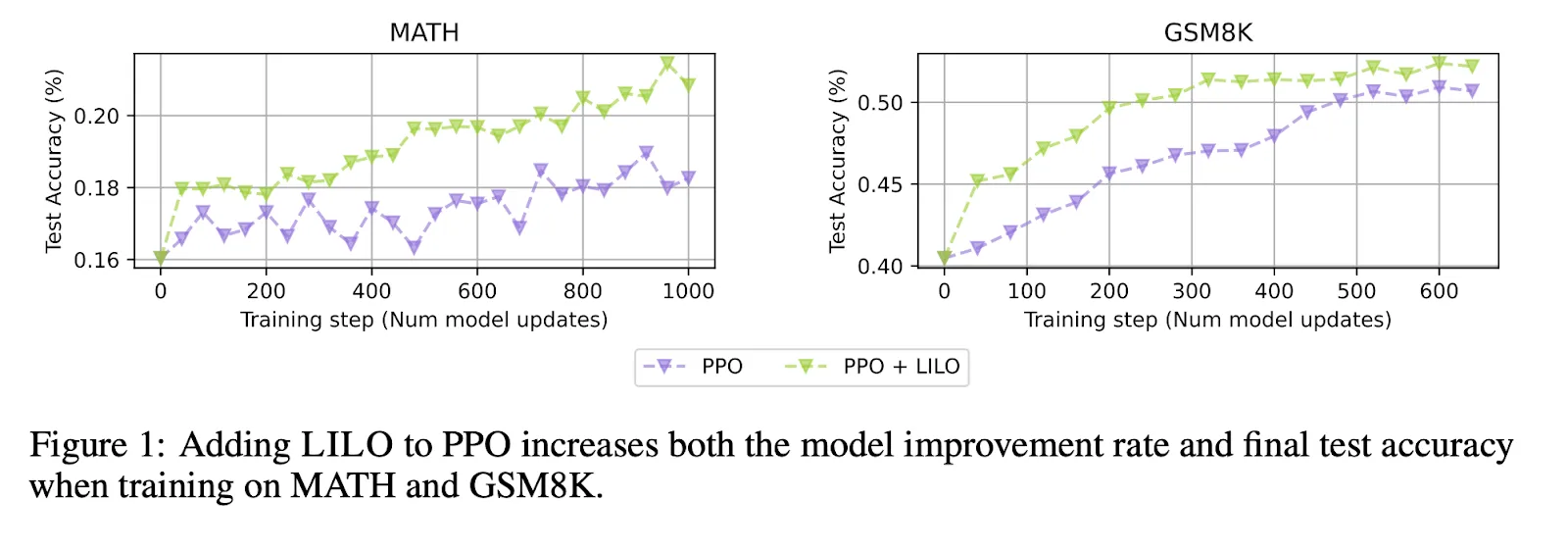
Task generation at the learnable frontier
When the complexity of tasks is low, a combination of clever curriculum design and prioritized sampling is an effective strategy. However, as task complexity increases, the number of intermediate capabilities we need to master first also increases. The bottleneck is no longer maintaining the learnable frontier given a fixed set of tasks, but instead** finding new tasks to feed to the learnable frontier. **
To make this more concrete, consider an agent learning how to be superhuman at mathematics. This is a highly complex subject with an egregious number of fields that build on each other. In each subdiscipline, an agent must learn how to answer a variety of problems to truly grasp concepts and move on to higher order problems. Fidelity with basic mathematical operations opens up algebraic problems. Mastery of differential equations is necessary for mathematical biology. Familiarity with set theory helps to ground category theory. This can explode fast and become ugly in a hurry.
Using humans to design all these task variations and corresponding rewards would be incredibly costly and error-prone – in fact, this is exactly why we already use RLAIF to train reward models instead of (foolishly) trying to scale human labeling to millions of examples. Accordingly, the next best idea is to use a language model to parameterize the distribution of all tasks and then sample from this. In fact, most AI labs already do this by using LLMs to create synthetic questions across code, math and language reasoning problems. However, today this is considered a separate step before training that creates or augments a fixed dataset. It does not continuously and reliably generate tasks throughout training that are maximally learnable, leading to an automatic, emergent curriculum of increasing complexity.
**Teachers, students and absolute zero **
To visualize the problem of task generation and simultaneous agent learning, it’s more fun to think about a teacher and a student.
Imagine there is a teacher model that produces environments and a protagonist student model trying to solve them. The goal is to maximize the student’s performance on any given environment while also making any generated environment tough for the student to solve. The obvious first solution is to formulate a game where the student is always maximizing its score and the teacher is always trying to minimize the student’s score throughout training. But this would mean the teacher only generates extremely tough environments with no learning signal, so the student stagnates. Noam Brown explored this problem in more detail last week:
*“What should the reward for the teacher be in such a game? If it’s 2p0s (two player zero sum) then the teacher is rewarded if the student couldn’t solve the problem, so the teacher will pose impossible problems.” *
Absolute Zero, a paper released last month, weaved past this problem and consequently demonstrated one of the first successful attempts at self-play with language models. They used a single model to both generate and solve mathematical and coding questions, collapsing the student and teacher into a single jointly optimized agent. Most importantly, the teacher was rewarded for producing learnable tasks rather than minimizing the student’s score, and the student was rewarded for solving them. If the student couldn’t solve a problem, the teacher was penalized and if they did, the teacher rewarded inversely proportional to how successful the student was.
Research is moving very quickly here. Just last week, Jason Weston’s team at Meta published SPICE (Self Play In Corpus Environments), which extended the tackled tasks to general reasoning problems and measured student performance with the variance of the success rate – similar to the work in LILO mentioned earlier.
**Unsupervised environment design **
Despite such setups achieving state of the art performance, these formulations could lead to unstable performance at serious scale. The metric of task learnability could easily be hacked by the teacher, leading to tasks that appear solvable but an agent stagnates on them. Noam Brown gave an illustrative example: what if we reward the teacher for the student having a 50% success rate? Then the teacher could just flip a coin and ask the student what side it landed on. Providing the teacher with the right rewards is very difficult indeed.
Though such reward hacking will always be persistent and widespread, a better designed objective could make the teacher’s and student’s updates more smooth to avoid learning collapse. Though I haven’t seen it applied formally in the era of foundation models, I’m very **excited about the opportunity for unsupervised environment design **to solve this problem. This technique was first introduced by Michael Dennis and Natasha Jaques et al. in 2020 for maze navigation and can automatically sample and adapt the task distribution, and even the environment distribution, to the learner during training, but with a special twist.
They introduce a second antagonist student who is allied with the teacher (sneaky!). The teacher now produces environments that are solvable by the antagonist student but tricky for the protagonist. This is achieved by getting the teacher and antagonist to maximize the performance gap between the two students, while the protagonist wants to minimize that gap. More formally, this gap is called regret. This neat trick ensures that generated environments are always solvable by at least one student, the antagonist. If the protagonist (the person we really care about) ever catches up to its counterpart, the teacher will make the game more challenging again, but not so difficult that its ally can’t solve it.
**Evolutionary Environment Design **
While UED offers more stability in the student and teacher’s training signal, there are still significant reward shaping issues that make it tricky to train the teacher in practice. The teacher’s reward depends on future student actions in generated environments, and they have to wait for the student to attempt each environment. This is known as a long horizon, sparse reward problem which is notoriously difficult to solve in reinforcement learning. Moreover, the teacher and students could co-evolve into cycles of narrow skill domains unless there’s external pressure which encourages diversity and interesting tasks. Teaching is a tough job.
For this reason, Jack Parker-Holder and Minqi Jiang et al. identified in “ACCEL” that when applying UED to the simple problem of solving and generating mazes with various walls/layouts, randomly sampled environments with high regret actually produced better empirical results than explicitly generated ones. Interestingly, the authors suggest fixing this by not learning the environments at all. They instead turn to** evolutionary algorithms (EAs) **for generating new and, critically, diverse tasks.
Evolutionary algorithms emerged in the 1960s and, as you can probably guess, were inspired by biological evolution. Instead of just optimizing a single solution against a task metric, early EAs like genetic algorithms maintained a “population” of solutions and borrowed ideas from evolution like mutation to randomly alter candidate solutions. This encouraged diversity and ensured the solution space was fully explored.
In 2018, Kenneth Stanley and Jeff Clune pioneered the use of EAs for designing new environments in their seminal work POET (Paired Open-Ended Trailblazer). In this work, they let a population of agents optimize for success in a set of environments. Once the environment was solved, it was mutated randomly in a non-neural way. The changed environment was then added to the existing population if the agents didn’t find it too easy or hard. This created a diverse set of increasingly challenging environments which outperformed manual curriculum design.
Parker-Holder and Jiang et al. built on this concept in ACCEL and importantly combined it with our teacher, protagonist, antagonist setup from UED. While this yielded incredible performance in the setting of solving mazes, they noted there’s still significant research to be done in applying EAs to environment design for more complex problems, such as in language and vision. The above methods use EAs by making them explicitly manipulate environment variables, which is not inherently scalable as the space and breadth of environments explodes. It’s hard to determine how something should be explicitly manipulated if it’s never been generated before!
**Gradient Based Techniques Meet Non Gradient Heuristics **
Thankfully, we don’t have to perform mutations directly on environment variables. We can instead use LLMs to take a task or environment as input and ask it to mutate it. Recently, DeepMind released AlphaEvolve to solve math questions using this method, refining candidate solutions from the population with LLM mutations to encourage diversity.
This opens a path for evolutionary algorithms to be used in conjunction with learned environment generators to create a diverse set of evolving playgrounds for agents, potentially marrying gradient based and non-gradient based techniques. The former continuously generates new problems at the learnable frontier for the protagonist and antagonist students. In conjunction, the evolutionary algorithm maintains and mutates a population of such environments to avoid local minima and pursue novel tasks. Only time and further research will tell!
To me, the use of UED and EAs in this manner feels eerily reminiscent of the combination of adversarial self-play with Monte Carlo Tree Search (MCTS) to create AlphaGo. The former is a multi-agent setup to design an increasingly difficult curriculum of synthetically generated tasks. The latter is a method which balances exploitation and exploration of existing generations to ensure the solution space is fully explored. Optimistically, this could be history’s way of rhyming and not repeating.
Conclusion
There are many areas that require work beyond UED and evolutionary algorithms to get self-play working with LLMs. Beyond the obvious collection of far more task specific data so that an enormous task distribution can be accurately parametrized and sampled, there are several more technical problems. For example, ensuring that RL objectives themselves are sufficiently diverse and reward interestingness to avoid policy entropy collapse, in order to solve our UED teacher’s long horizon, sparse reward problem. Another key issue is the credit assignment problem, namely how to provide dense feedback to a teacher’s action trajectory so that it can more easily learn which were the most useful environments it made. Countless more exist, but I am far from best placed to enumerate over all of them.
In an age of overexuberance, it’s worth remembering that scaling compute and environments buys you more shots on goal and goalposts to aim at, but, without the right methods, doesn’t buy you more reliability, stability and efficiency. Or as Ross Taylor, the former head of reasoning at Meta, recently stated: “crude RL maximalism is overhyped. The magic comes from the interplay of RL with other things, and the angels are in the details.”
I am incredibly excited to chat with people thinking about the above problems, and to read more research in this field. If that’s you, please reach out (rohan at amplify partners dot com) and I look forward to meeting you!