The future of AI evaluation lies not in static evals or manual inspection, but in adaptive critics that continuously assess and validate what agents actually do.
**When static evals go stale **
**Picture this: **You’ve just spent months building the perfect evaluation suite for your agent. Your hallucination detector catches 95% of factual errors. Your internal tool-calling benchmark produces steady 9.2/10 scores. You’re confident; your elaborate eval pipeline is rock solid.
Then you deploy a new model backbone. Or update your system prompts. Or change your agent architecture. Or expand to a new user domain.
**Within hours, everything breaks.**
Your evals are green across the board, the new agent passes everything with flying colors, but production is on fire. U…
The future of AI evaluation lies not in static evals or manual inspection, but in adaptive critics that continuously assess and validate what agents actually do.
**When static evals go stale **
**Picture this: **You’ve just spent months building the perfect evaluation suite for your agent. Your hallucination detector catches 95% of factual errors. Your internal tool-calling benchmark produces steady 9.2/10 scores. You’re confident; your elaborate eval pipeline is rock solid.
Then you deploy a new model backbone. Or update your system prompts. Or change your agent architecture. Or expand to a new user domain.
**Within hours, everything breaks.**
Your evals are green across the board, the new agent passes everything with flying colors, but production is on fire. Users are complaining about completely new problems you’ve never seen. The agent that “aced every test” is making bizarre tool calls, going off-topic in ways that baffle you, or giving technically correct but utterly unhelpful responses.
So you do what every frustrated AI engineer does: you pull up real traces and start manually reviewing them. After several hours of “vibing” through actual agent interactions, you finally spot the pattern. The issue is obvious now that you’re looking at what your agent actually does.
What gives? Why did months of careful evaluation engineering miss what hours of eyeballing traces caught? This frustration is sparking heated debates across the AI community: ‘Evals are broken,’ ‘Just A/B test everything,’ ‘Production monitoring is enough.’
The truth is, there is merit to all of these sentiments, but what they reveal is a deeper issue that goes to the heart of reinforcement learning.
**The real problem: your agent’s behavior shifts, but your evals don’t **
We can understand the problem with static evals through a reinforcement learning (RL) lens. Your agent’s behavior is determined by a policy “π” (composed of models, prompts, architectures, and tools) that encounters states “s” (user queries, coding environments, conversation contexts) and takes actions “a” (responses, tool calls, reasoning steps).
When you evaluate your agent, you’re asking “How well does this agent handle situations it will actually face?” Does it complete the task? Not frustrate the user? Make successful tool calls?
RL tells us there are two fundamentally different ways to answer this question:
Off-policy evaluation (what most eval pipelines do): Test your current agent on pre-collected datasets—situations and scenarios that were encountered by previous versions of the agent (different model, system prompt, architecture).
E.g.: You create an evaluation dataset from old Codex traces that failed on notebook tasks. Your new agent, Claude Code, aces this benchmark because it consistently uses proper notebook-reading tools instead of trying to parse raw JSON like Codex did.
On-policy evaluation: Let your current agent interact with real users and situations, then measure how well it performs on those actual interactions. This captures what your agent really does in the wild.
E.g.: You deploy Claude Code and users are still frustrated. Why? Claude Code reads notebooks perfectly but then edits cells out of order, breaking user workflows. Your eval never captured this failure mode because the old policy never reached these states.
The killer insight: Off-policy evaluation becomes stale the moment your policy changes. When your agent starts taking different actions, it encounters different states that your benchmarks never covered.
Off-policy evaluation is extremely valuable because it scales well: it lets you use massive datasets, benefit from hindsight over others’ mistakes, gain statistical confidence through volume, and safely evaluate in high-stakes domains like healthcare or finance where exploratory mistakes have serious consequences.
However, off-policy evaluation suffers from the staleness problem without proper corrections/constant updates (that many eval pipelines skip). This is why on-policy methods have become so popular and effective for model training [Online RL for Cursor Tab, Why online RL forgets less, Bridging offline and online RL for LLMs]. Even noisy on-policy estimates can be vastly more valuable than precise but stale off-policy ones. We’re now rediscovering this same principle in model evaluation [Dynabench: rethinking benchmarking in NLP].
The best of both worlds?
Your manual “vibing” works because you’re evaluating on-policy–looking at what your current agent actually does! But it doesn’t scale, requiring hours of manual work to build confidence every time something changes. Your automated eval pipelines build confidence through volume and repeated measures. But because they’re off-policy, they easily become stale if you’re not careful. How can we get the best of both worlds? The answer, as astutely pointed out by Hamel Husain and Shreya Shankar, is error analysis.
We’re big believers in error analysis, reflected in the solution we’ve built so you can stay on-policy AND build statistical confidence about recurring patterns without drowning in manual trace review:
1. Stay on-policy: production monitoring
Monitor your agent’s actual traces in production and development. Every real-world interaction is a data point about your current agent’s behavior.
2. Critic monitors everything: dense open-ended annotation
Open-ended LLM critics annotate your agent’s every step, and flag anything anomalous. No pre-defined failure categories, cast the widest possible net. The objectives of such critics are divergent enough from that of the agent to warrant specialized models for e.g. the critic benefits from seeing lots of bad trajectories! We are constantly improving our critics to become expert spotters of failure patterns across a diverse landscape of agent behaviors and domains.
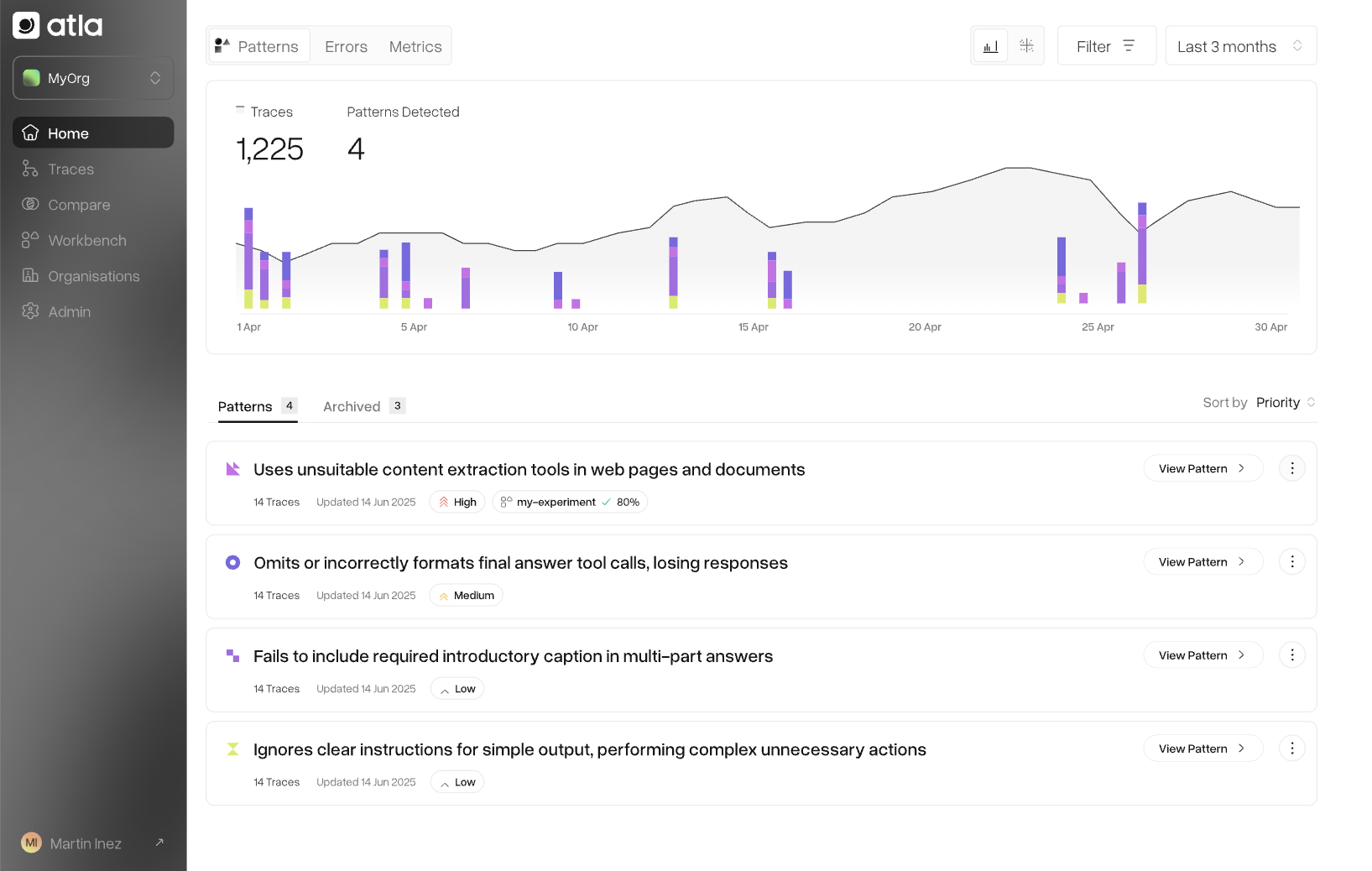
3. Focus on recurring patterns: high confidence clustering
Atla clusters the critic’s annotations across thousands of traces to surface recurrent failure patterns. Patterns that appear frequently indicate high-confidence failure modes, and you can monitor these persistently across time, while also discovering any new ones that emerge.
- Day 1: Critic flags 3 instances of a new cluster, “potential medical advice”
- Day 2: 12 more instances join this cluster
- Day 3: 35 more in the same cluster, while a new cluster emerges of “over-refusal”
- Result: You’re confident about your agent’s propensity to give medical advice in 35/400 traces, but you also have an eye out for new failures as soon as they emerge.
The future of AI evaluation isn’t perfect static tests or endless manual review. It’s adaptive critics that build confidence about what your agent actually does.
Ready to stop playing evaluation whack-a-mole?