Inference Engine 2.0 is GMI Cloud’s next-generation multimodal platform that unites text, image, audio, and video creation in one seamless system with faster performance and higher throughput. Built for both creators and builders, it transforms AI development into a fluid, frictionless process where creativity scales as fast as inspiration.
“Imagination is too often limited by the realities of execution.”
So let’s change that. Imagination shouldn’t stop at the limits of compute. Today, we’re launching Inference Engine 2.0 — GMI Cloud’s next-generation platform built for the multimodal era.
Every breakthrough in AI pushes the boundaries of what’s possible, but too often the people with the biggest ideas hit the hardest walls. The tools that power AI are still too complex…
Inference Engine 2.0 is GMI Cloud’s next-generation multimodal platform that unites text, image, audio, and video creation in one seamless system with faster performance and higher throughput. Built for both creators and builders, it transforms AI development into a fluid, frictionless process where creativity scales as fast as inspiration.
“Imagination is too often limited by the realities of execution.”
So let’s change that. Imagination shouldn’t stop at the limits of compute. Today, we’re launching Inference Engine 2.0 — GMI Cloud’s next-generation platform built for the multimodal era.
Every breakthrough in AI pushes the boundaries of what’s possible, but too often the people with the biggest ideas hit the hardest walls. The tools that power AI are still too complex, too slow, and too fragmented for the creators and builders trying to shape what comes next. Render queues. GPU waitlists. Platforms that feel like they were built for engineers, not artists.
The people with the biggest ideas have been held back by the smallest bottlenecks. Engineers are often designing for other engineers, but the tools we’re building are at their best when accessible to everyone.
Inference Engine 2.0 tears down the wall between imagination and execution. Instead of being just another backend tool, it will become the bridge between your creative spark and the power to realize it instantly.
Every prompt, every clip, every sketch should flow straight into production. That’s the world IE 2.0 makes possible.
- ⚡ Up to 1.46× faster response times and 25–49 percent higher throughput on live workloads.
- 🎨 Fully multimodal — text, image, audio, and video in one unified system.
- 🌐 Elastic global scaling, zero setup, and a new console built for both creators and builders.
When building becomes frictionless, people become more productive and create more.
For Creators: Creation Without Compromise
**You shouldn’t need to understand orchestration queues or model routing just to make something beautiful. **If you’re a visual artist, filmmaker, or creative studio, you should be able to generate, edit, and publish faster than ever without fighting technical bottlenecks.
With Inference Engine 2.0, you can go from concept to output in one continuous flow — generate, edit, and publish faster than ever, all without touching a terminal. It’s designed from day one to be multimodal-native — text, image, audio, and video co-exist in the same workspace.
- 🎬 Native video model support: Veo 3.1, Sora 2 Pro, Pixverse, Hailuo 2.3
- 🖼 End-to-end image generation: Seedream, Flux-kontext-pro, Seededit
- 🎙 Expressive voice synthesis: Minimax TTS, ElevenLabs TTS
Imagine this:
- You drop in a sketch and the workflow turns into a storyboard.
- Add dialogue and it becomes a scene.
- One click later, it’s voiced, color-graded, and ready to share.
- That’s what creation feels like when the UI/UX bottleneck disappears.
Through our end-to-end multimodal workflow, you can run creative processes directly on GMI Cloud without code rewrites or setup overhead. Behind the scenes, IE 2.0’s real-time GPU pipeline keeps everything running fluidly, even during peak traffic.
Every millisecond saved goes back where it belongs — into your next idea.
We’re here to clear the bottleneck between vision and delivery. Teams can move from prototype to publish in hours instead of days, access advanced models without added cost, and rely on the stability that lets experimentation thrive. Every improvement to inference translates to more time creating and less time waiting.
No more compromise between quality, speed, and cost.
With Inference Engine 2.0, creativity finally scales as fast as inspiration.
For Builders: Under the Hood of IE 2.0
If you build, deploy, or scale models, you already know the pain: latency spikes, fragmented pipelines, constant optimization debt.
Inference Engine 2.0 fixes that throughout the stack, from infrastructure to API. It’s a reimagining of what an inference engine should do for the multimodal age.
Here’s what’s new under the hood:
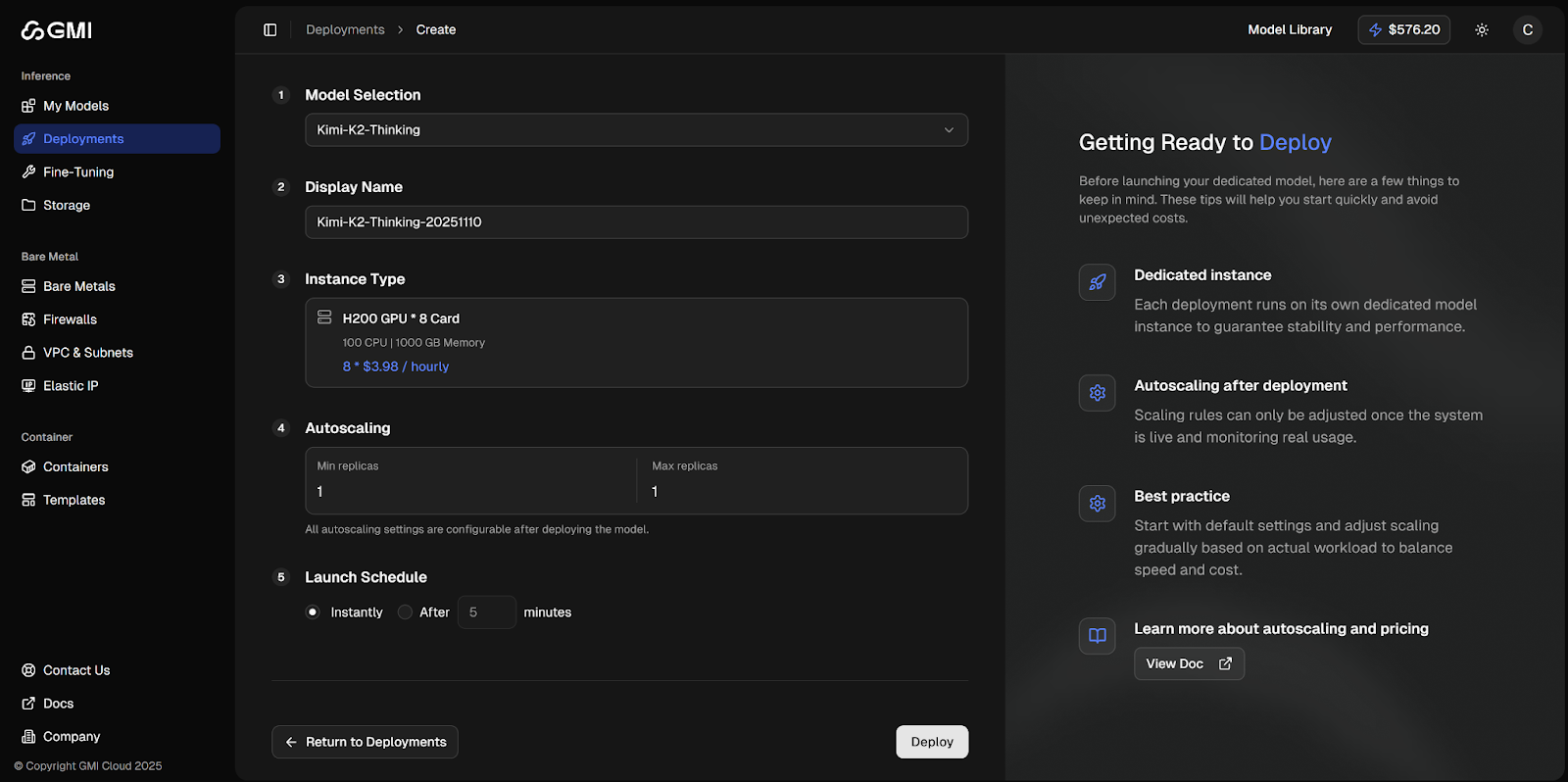
**1. Smart Memory System IE 2.0 remembers what your model has already processed. When multiple users hit the same data, shared segments stored in a hierarchical KV cache pool are reused instead of being recomputed. When you can expect up to 49% higher throughput and 30% lower inference cost, **your workloads accelerate as they grow instead of dragging behind them.
**2. Elastic Scaling and Provisioning **Traffic surges? IE 2.0 provisions GPUs automatically from our own datacenters worldwide — zero manual ops, minimal downtime. With **8.2× less API downtime, 2.34× faster GPU allocation, **your next viral launch doesn’t have to melt your backend.
**3. Precision Without Compromise **No “fast mode.” No hidden quantization. Every token, frame, and pixel outputs exactly as intended — from prototype to scale. Your production inference should look identical to your local dev run.
**4. Multimodal-Native Architecture **One pipeline handles text, image, audio, and video — each intelligently routed to the most efficient compute path. You can optimize for cost, performance, or fidelity, all without rewriting a line of code.
**For Builders, IE 2.0 is infrastructure that finally adapts to you. **Run your workloads, not your cluster scripts. Build faster, scale cleaner, and trust that performance isn’t a trade-off at GMI Cloud, where it’s the baseline.
A Unified Console for Every Builder and Creator
The new Inference Engine 2.0 Console is your command center for everything AI creation. Open it and you’ll see everything — your models, endpoints, usage metrics, and multimodal workflows — unified in one place.
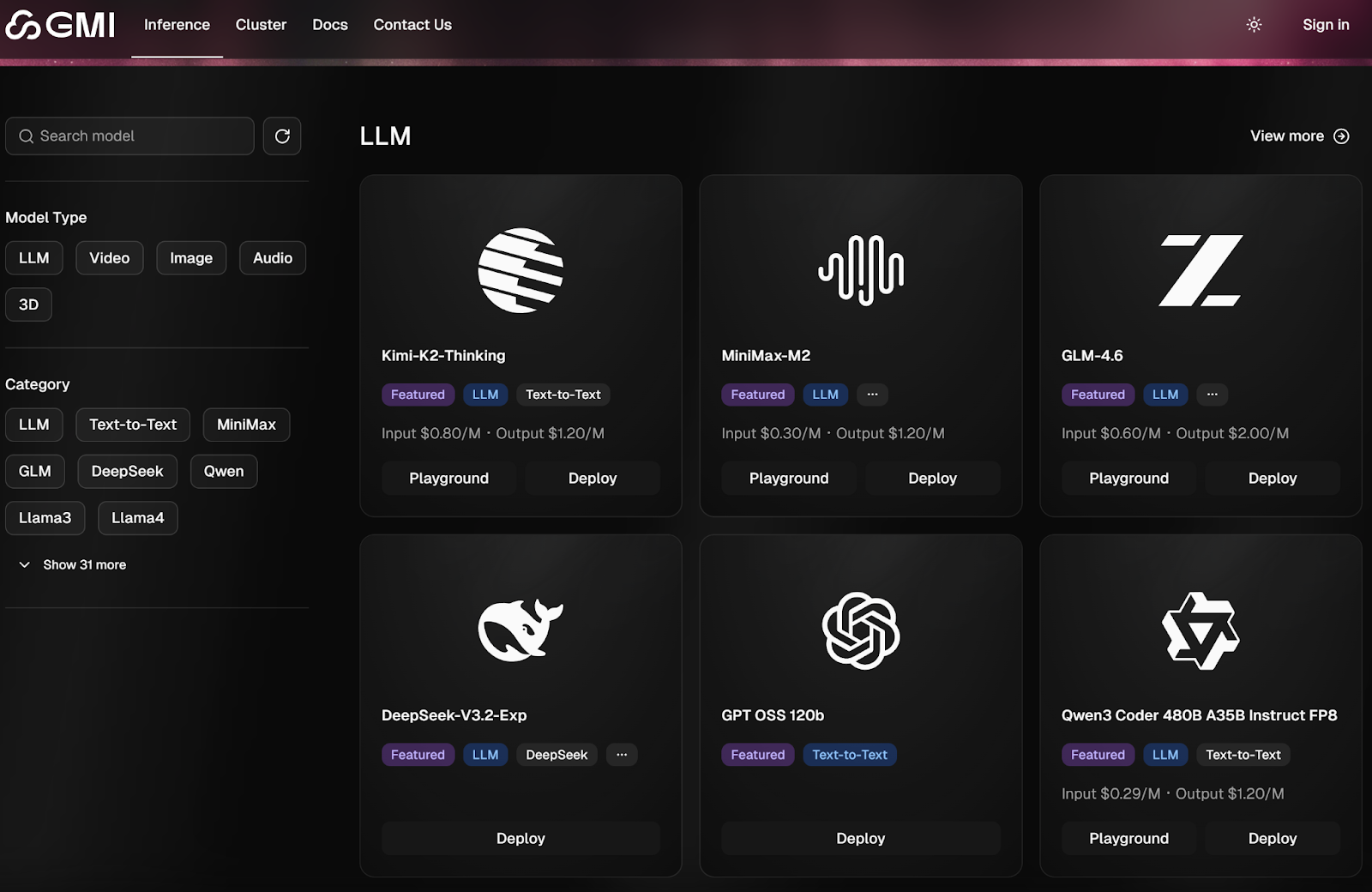
- **🚀 One-Click Deployments **Spin up a serverless playground or launch dedicated endpoints instantly. No YAMLs, no provisioning — just “Run.”
- **🔍 Seamless Model Discovery **Search, filter, and deploy top models directly. From Minimax and Hailuo to Veo and Flux, everything is pre-configured for GMI’s infrastructure.
- **🎨 Built for Focus **Light and dark themes for long sessions. Responsive surfaces tuned for both creatives and engineers. Every detail was designed to make infrastructure feel invisible.
We intend for the platform to feel less like configuration hell and more like the front door to an entire AI studio.
Build the Future With Us
We built Inference Engine 2.0 to make AI something anyone can build with, not just those who understand the backend. If you’re building a copilot, generating a video pipeline, or launching a multimodal product, this is your canvas.
We can’t wait to see what you unleash!
👉 Try Inference Engine 2.0 today at console.gmicloud.ai💬 Join our Discord to share feedback and help shape what comes next.
Imagination Meets Intelligence.