I spent some time playing around with ClickHouse to understand how it scales and what it takes to operate it. I wanted to distill what I learned, so here’s my brain dump.
Disclaimer: These are my notes from some unscientific tests, docs, and content put out by others on their experiences running ClickHouse. Please correct me where I got things wrong!
Why I did this
ClickHouse is all the rage now. It’s being used in a lot of observability use cases, and Tesla even built a PromQL compatibility layer on top. I wanted to get a feel for running ClickHouse clusters—not to test performance (everyone raves about it anyway, so I…
I spent some time playing around with ClickHouse to understand how it scales and what it takes to operate it. I wanted to distill what I learned, so here’s my brain dump.
Disclaimer: These are my notes from some unscientific tests, docs, and content put out by others on their experiences running ClickHouse. Please correct me where I got things wrong!
Why I did this
ClickHouse is all the rage now. It’s being used in a lot of observability use cases, and Tesla even built a PromQL compatibility layer on top. I wanted to get a feel for running ClickHouse clusters—not to test performance (everyone raves about it anyway, so I’m assuming it’s performant out of the box), but to understand the architecture and operational reality of scaling it:
-
What does it require to run ClickHouse at scale?
-
How do you add nodes?
-
What about cluster upgrades?
-
I haven’t looked into upgrades yet—there’s a ClickHouse operator that promises to handle them, but I don’t know how good it is.
I went step-by-step: single node → replication → sharding → S3 storage. All of this is in the repo: https://github.com/gouthamve/clickhouse-experiments. I don’t know if it’ll work for you, but if you are interested, open an issue, and I’ll clean things up.
Single Node: The Starting Point
A single node ClickHouse cluster is dead simple. You:
- Run ClickHouse
- Give it a disk
- Write to it
- Query from it.
- Done.
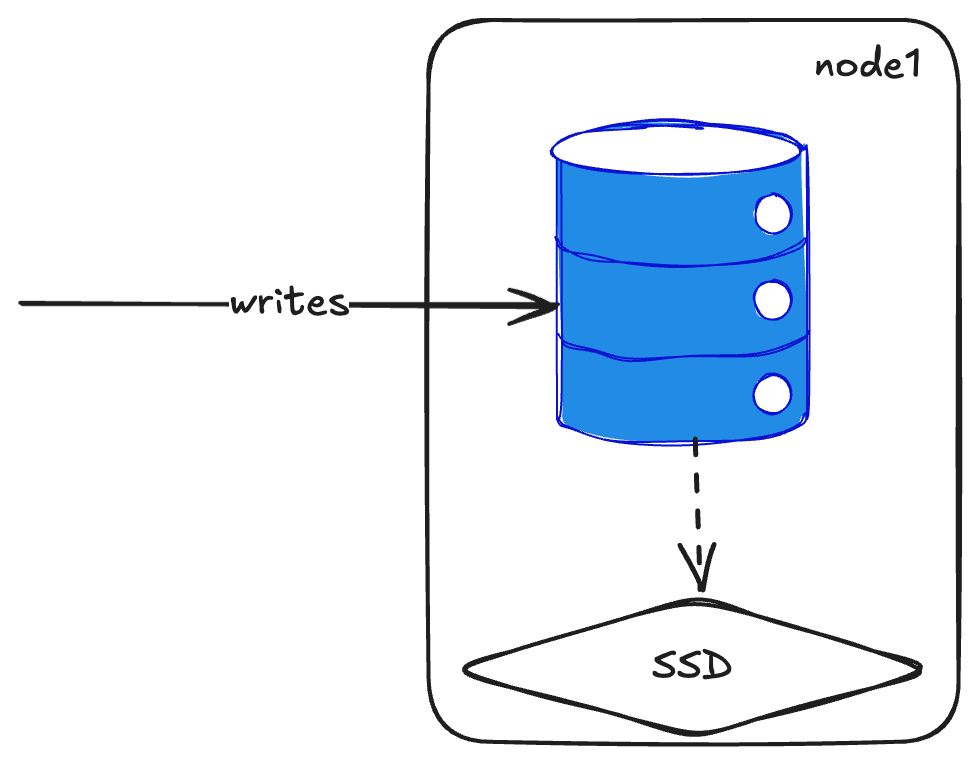
And honestly, they’ve spent a lot of time making this work really well—you can get far with vertical scaling. Just throw more resources at it.
This reminds me of how Prometheus was built, and I appreciate that philosophy.
Clustering
Once you want more than one node, you need a coordination layer. ClickHouse uses either Zookeeper or ClickHouse Keeper (their implementation, since Zookeeper is in Java and challenging to operate).
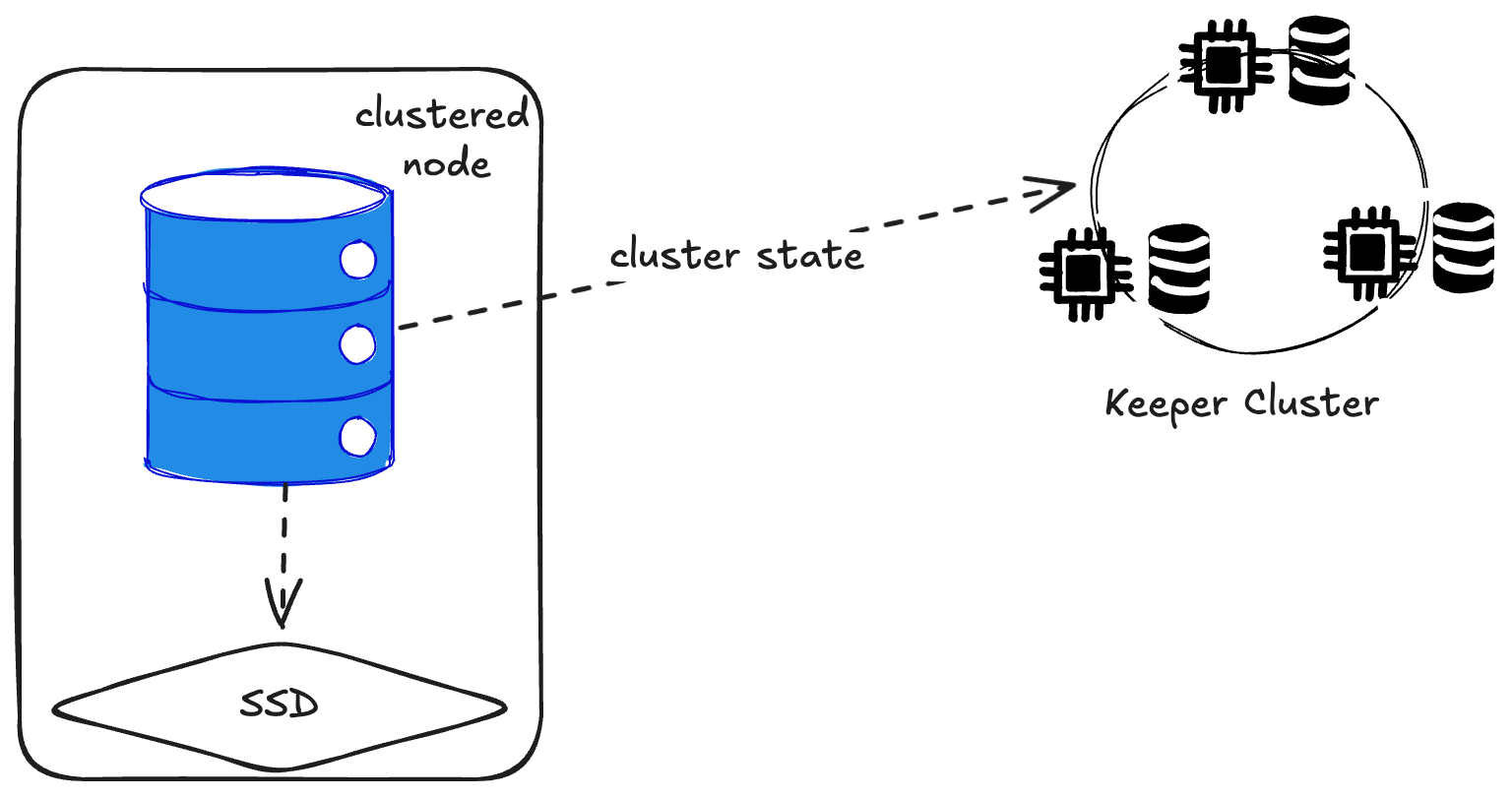
Let’s just call it Keeper. Any time you see more than one ClickHouse node, you require a Keeper cluster. If Keeper goes down, ClickHouse doesn’t know what data is where, so it can’t query or replicate correctly. A list of all the data stored in Keeper is listed here.
You’ll want to run three (maybe five) Keeper nodes on dedicated hardware. I am going to not show the Keeper Cluster from now on, but it’s still part of the architecture
Adding Replication
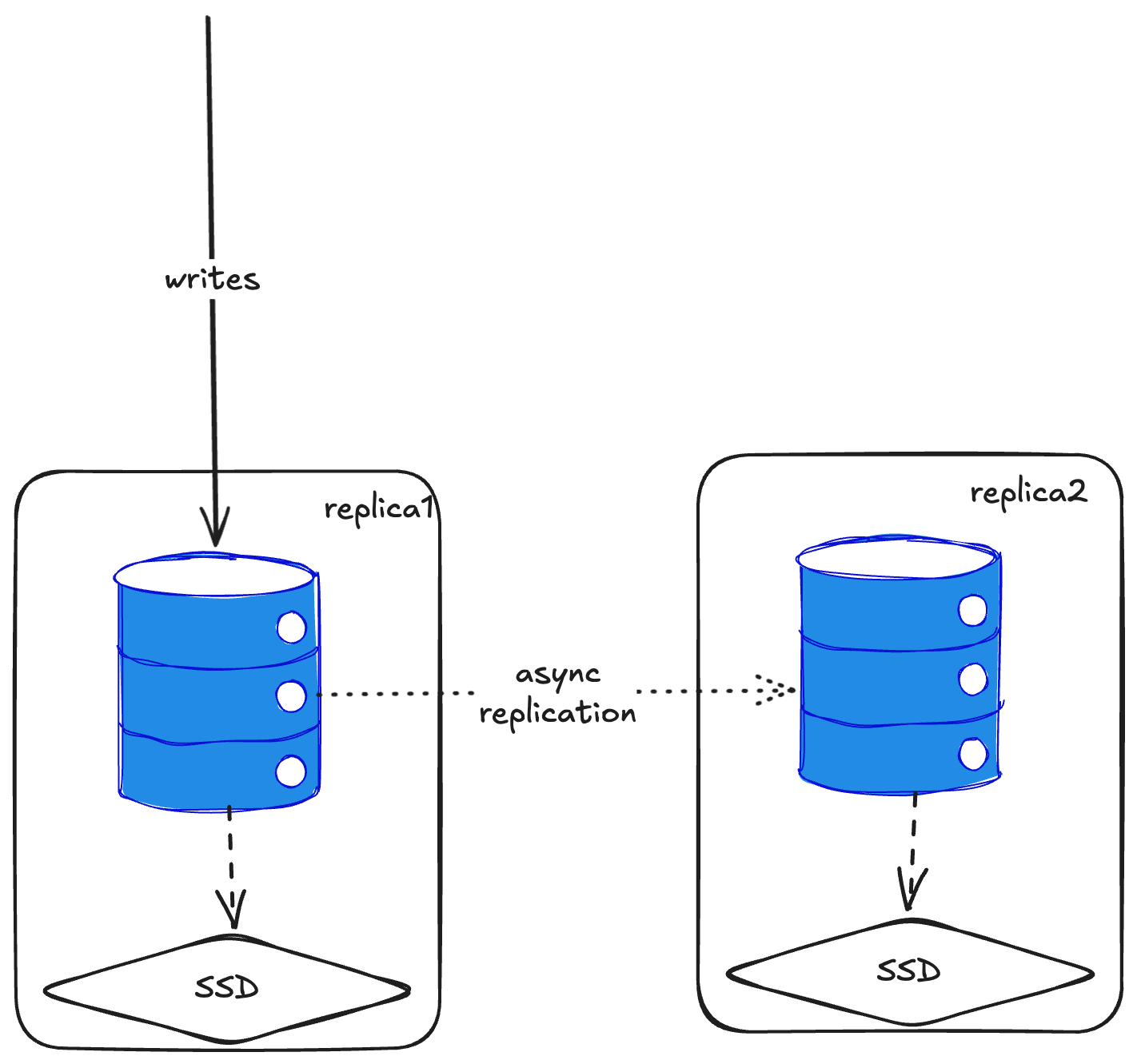
Here’s how replication works: you tell ClickHouse about the replicas, and whenever you write to one node, it asynchronously replicates to all replicas. You can also write to multiple replicas simultaneously, and they’ll sync between themselves.
To add replication, you drop a config file into ClickHouse that says “you belong to shard one, you’re replica one” and list all the replicas in the cluster. Then you enable distributed querying. When creating tables, instead of using MergeTree, you use ReplicatedMergeTree.
<?xml version="1.0"?>
<clickhouse>
<!-- Macros for replica identification -->
<macros>
<replica>replica1</replica>
<shard>01</shard>
</macros>
<!-- ClickHouse Keeper configuration -->
<zookeeper>
<node>
<host>clickhouse-keeper</host>
<port>9181</port>
</node>
</zookeeper>
<!-- Cluster definition -->
<remote_servers>
<replica_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>clickhouse1</host>
<port>9000</port>
</replica>
<replica>
<host>clickhouse2</host>
<port>9000</port>
</replica>
</shard>
</replica_cluster>
</remote_servers>
<!-- Enable distributed DDL -->
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
</clickhouse>
CREATE TABLE IF NOT EXISTS trips (
trip_id UInt64,
...
pickup_location_id UInt16,
dropoff_location_id UInt16
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/trips', '{replica}')
PARTITION BY toYear(pickup_datetime) * 100 + toWeek(pickup_datetime)
ORDER BY (pickup_location_id, pickup_datetime)
SETTINGS index_granularity = 8192;
Adding a replica mid-way will sync all the existing data as well.
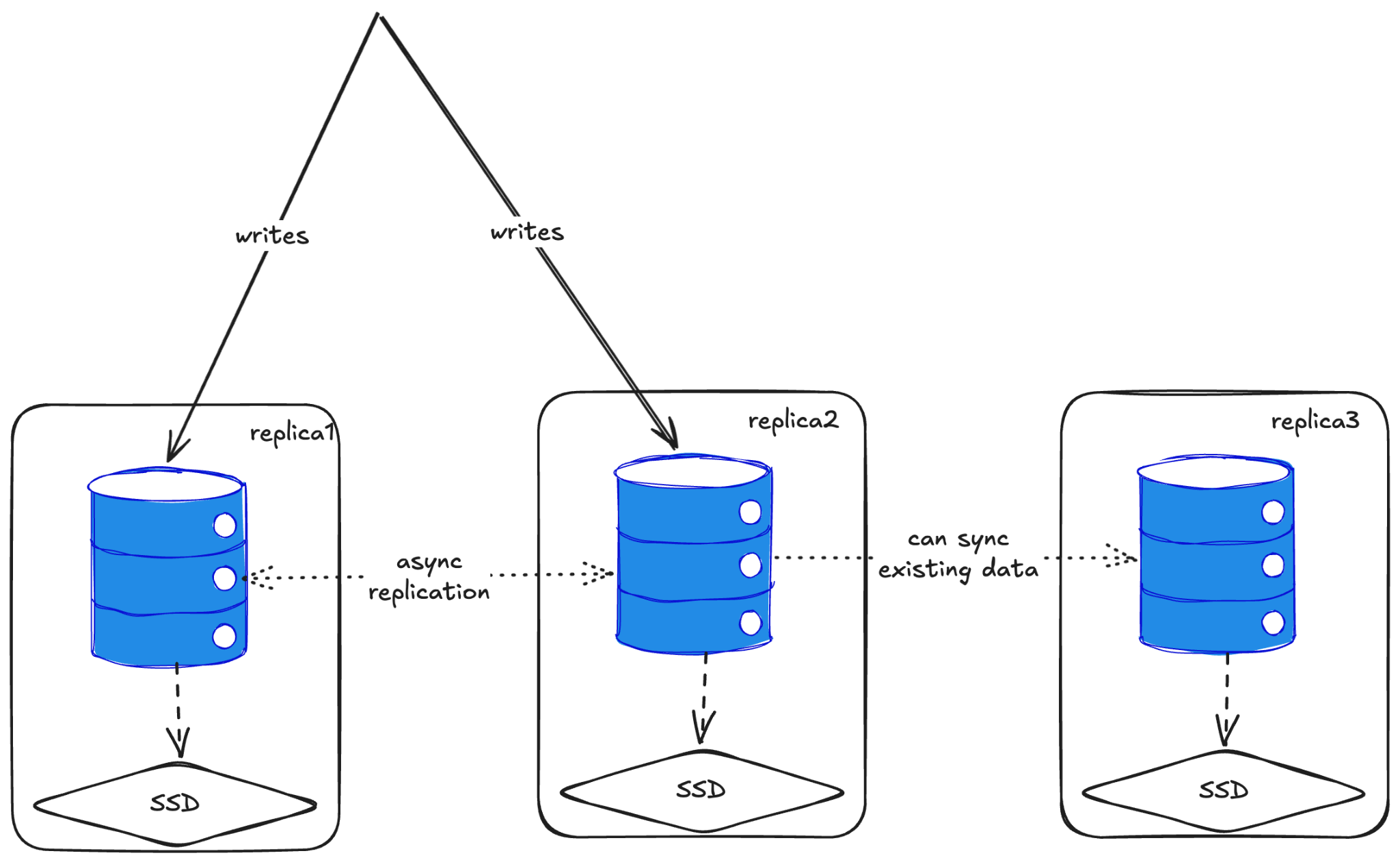
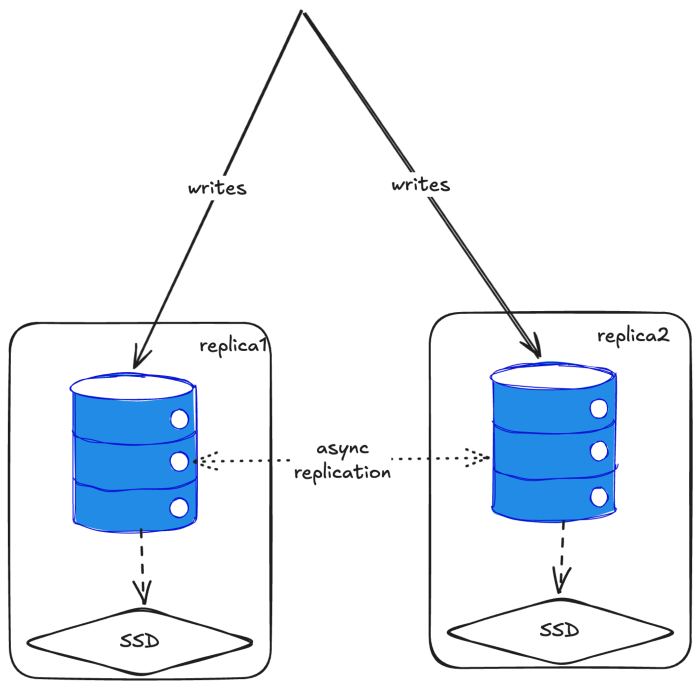
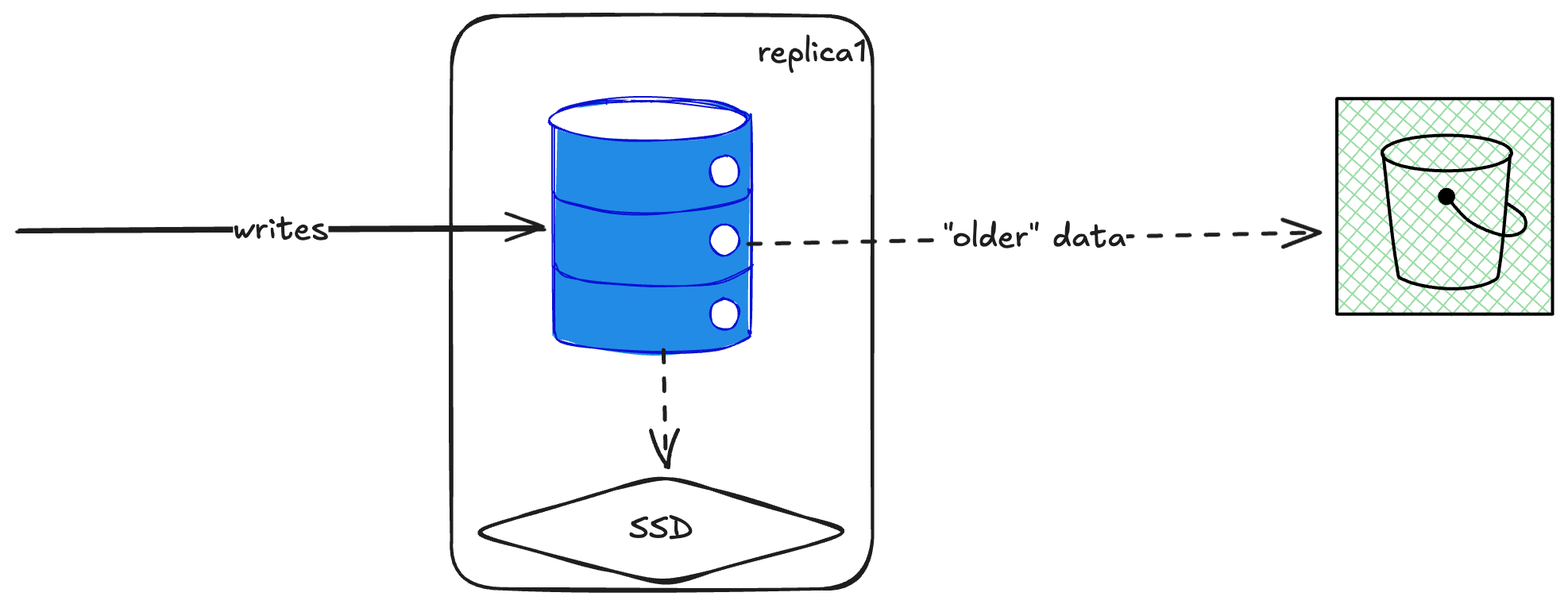
A common pattern (recommended by Tinybird, another ClickHouse company) is to have separate replicas for writes and reads. This gives you compute-compute separation. Even if your write path gets overwhelmed, you can still query older data from the read replicas.
Important caveat: There’s no concept of a unique key or primary key. If you write two different rows with the same primary key to different replicas, you’ll end up with two rows. No uniqueness constraints. You can collapse them later asynchronously (via aggregation or replacement), but by default, they coexist.
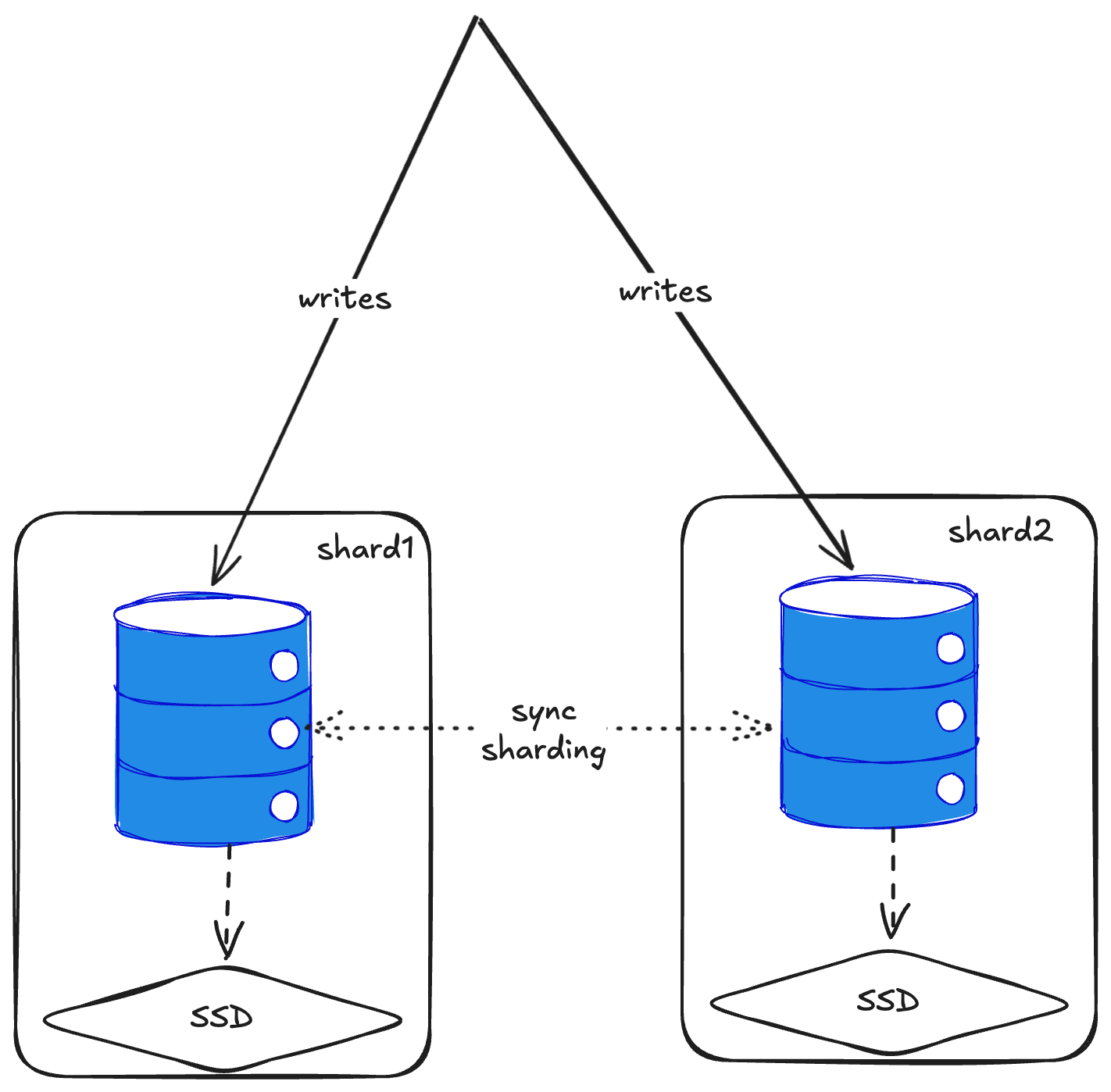
Adding Sharding
Sharding is simple, but interesting. Each shard is actually just an isolated ClickHouse node that doesn’t really know about the others. The magic happens through a DistributedTable abstraction on top.
<?xml version="1.0"?>
<clickhouse>
<!-- Macros for shard identification -->
<macros>
<shard>01</shard>
<replica>replica1</replica>
</macros>
<!-- ClickHouse Keeper configuration -->
<zookeeper>
<node>
<host>clickhouse-keeper</host>
<port>9181</port>
</node>
</zookeeper>
<!-- Cluster definition with 2 shards (no replication) -->
<remote_servers>
<shard_cluster>
<!-- Shard 1 -->
<shard>
<internal_replication>false</internal_replication>
<replica>
<host>clickhouse-shard1</host>
<port>9000</port>
<user>default</user>
<password>clickhouse</password>
</replica>
</shard>
<!-- Shard 2 -->
<shard>
<internal_replication>false</internal_replication>
<replica>
<host>clickhouse-shard2</host>
<port>9000</port>
<user>default</user>
<password>clickhouse</password>
</replica>
</shard>
</shard_cluster>
</remote_servers>
<!-- Enable distributed DDL -->
<distributed_ddl>
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
</clickhouse>
-- Create LOCAL table on each shard
-- This table stores the actual data on this specific shard
CREATE TABLE IF NOT EXISTS trips_local (
trip_id UInt64,
vendor_id UInt8,
....
pickup_location_id UInt16,
dropoff_location_id UInt16
)
ENGINE = MergeTree()
PARTITION BY toYear(pickup_datetime) * 100 + toWeek(pickup_datetime)
ORDER BY (pickup_location_id, pickup_datetime)
SETTINGS index_granularity = 8192;
-- Create DISTRIBUTED table that routes to all shards
-- This is a "virtual" table that distributes writes and reads across shards
CREATE TABLE IF NOT EXISTS trips_distributed AS trips_local
ENGINE = Distributed(
'shard_cluster', -- Cluster name from config
'default', -- Database name
'trips_local', -- Local table name on each shard
cityHash64(pickup_location_id) -- Sharding key: distributes by pickup location
);
You create a local table on each shard, then create a distributed table with a sharding key. The distributed table handles routing data to the right shard. For example, you might do hash(pickup_location_id) % 2 for two shards—hash the pickup location ID, mod by the number of shards, and route accordingly.
Here’s the gotcha: there’s no automatic re-sharding. If you add a third shard later, only new data goes to it. All existing data stays where it is. You can work around this by biasing the sharding distribution (write 50% more to the new shard) or manually moving partitions. But it’s not automatic.
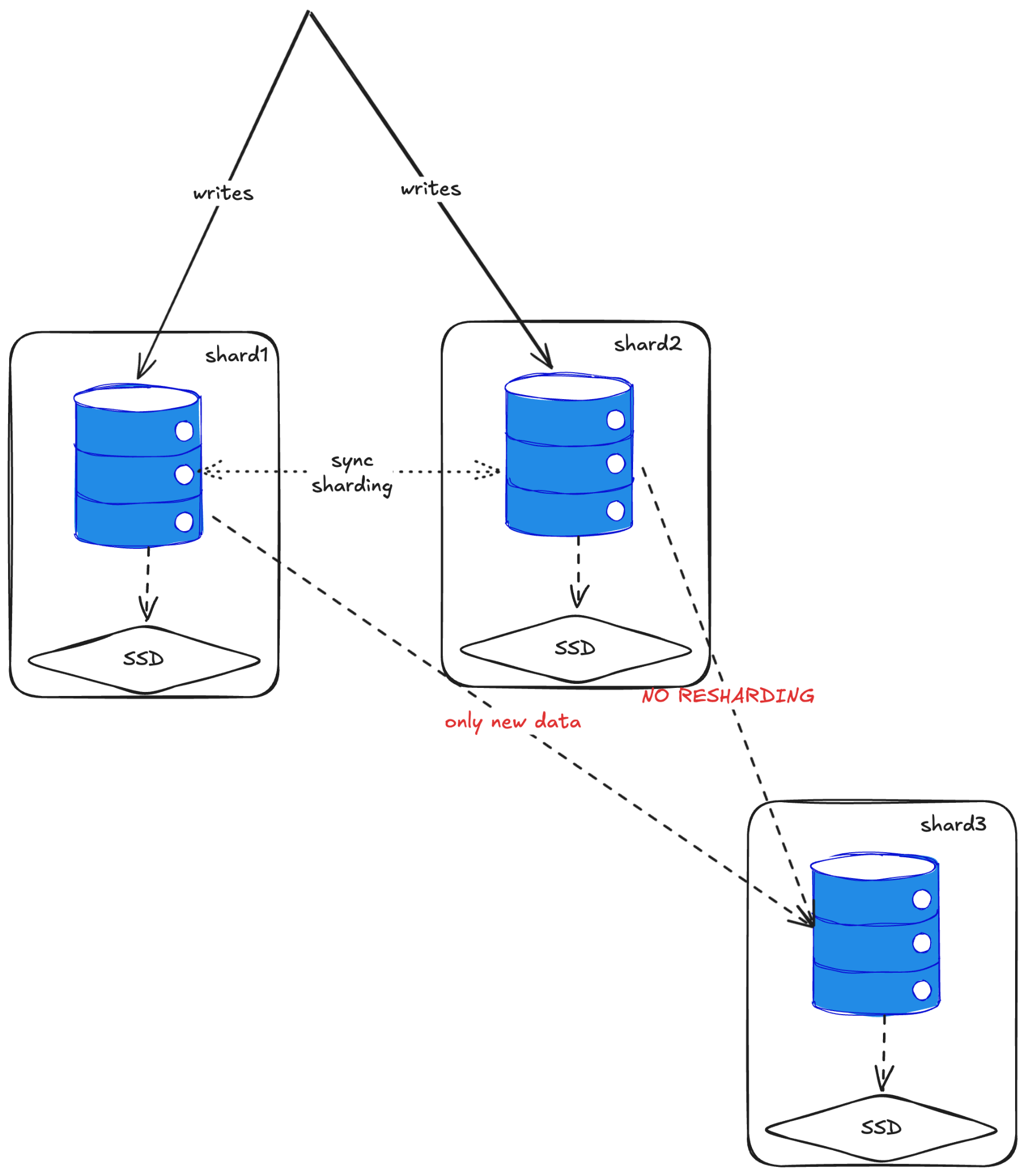
I wouldn’t be too worried about this for small retentions (one month or so), adding new shards means things will equalize within a few weeks. But if you’re doing multi-month or year-long retention, new nodes will be extremely imbalanced, and that’s concerning.
S3 Storage: So Close, Yet So Far
ClickHouse lets you create storage policies with multiple disks—SSD, HDD, S3, or just different locations, etc. You can set up tiered policies: keep data on SSD for 7 days, then move it to S3. Or use TTL-based policies tied to specific fields. I tested this with New York taxi trip data—half ended up on S3, half stayed local. Pretty cool.
This got me really excited because it’s similar to Mimir’s architecture. In Mimir, we have ingesters that store 2-3 hours of recent data in memory, then flush to S3. We have separate store gateways that query S3 for older data. When a query comes in, the querier looks at the time range and routes to ingesters (recent data) or store gateways (older data), or both. It works great because rebalancing only affects a few hours of data.
I thought we could do the same with ClickHouse! Have an ingester layer storing 1-2 days of data on disk, flush old data to S3, and have a separate querier layer that queries both. You can scale them independently.
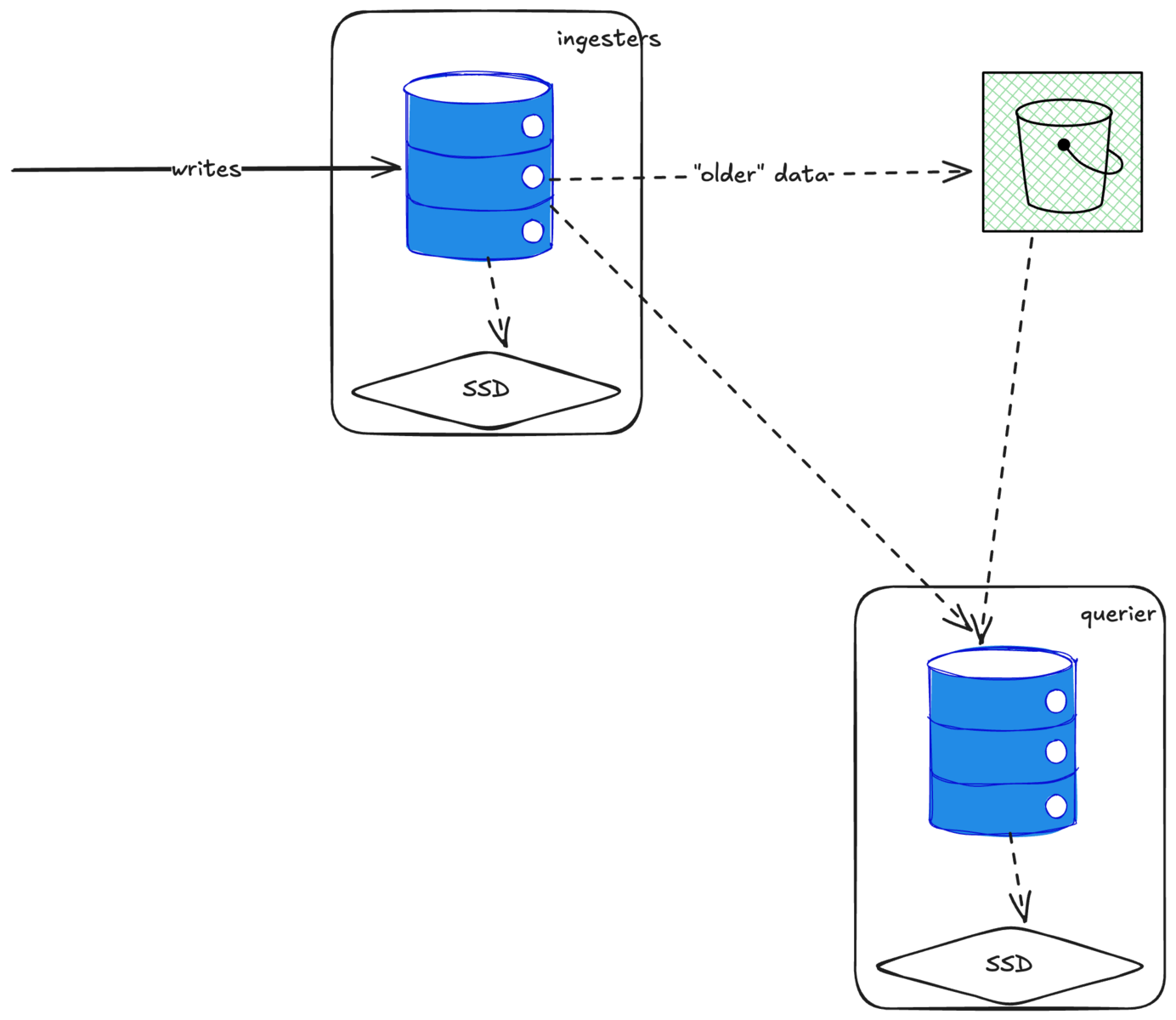
But life isn’t that easy.
The S3 Problem
ClickHouse treats S3 as just another disk. It writes to it like a file system, which means many small files and operations—this drives up S3 costs. Worse, it’s not actually stateless. You can’t just point a new ClickHouse node at an S3 bucket and query the data because the indexes are stored locally on the original shard.
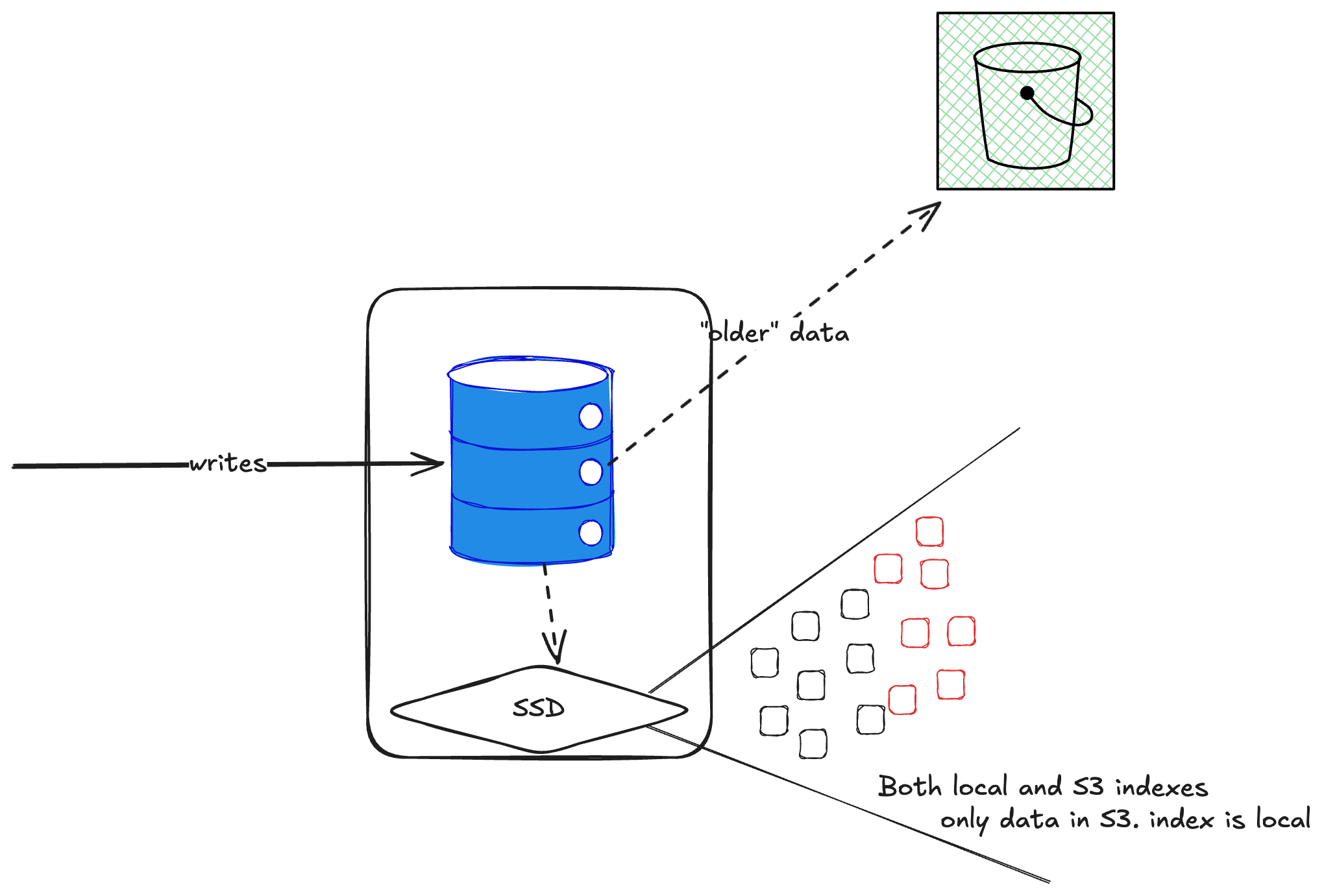
Fine, I thought, just add a replica. But that doesn’t work either—when you add a replica, it downloads all the data and writes its copy to S3. With five replicas, you’d have five copies in S3. Not great.
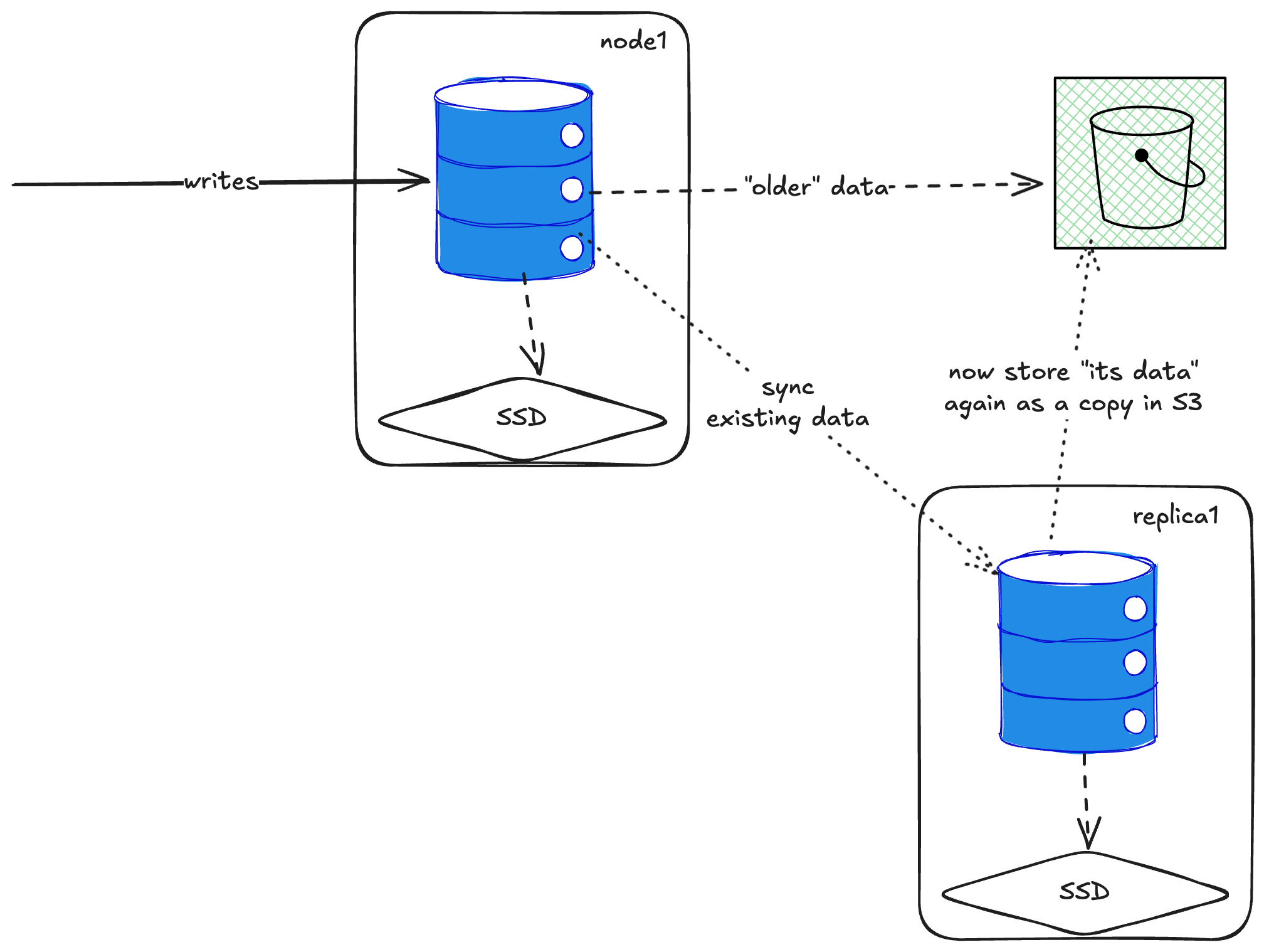
There’s something called “[zero-copy replication](https://altinity.com/blog/clickhouse-mergetree-on-s3-intro-and-architecture?ref=gouthamve.dev#::text=of%20fetching%20parts.-,Zero%2Dcopy%20Replication,-Alert%20readers%20(and)” that’s supposed to fix this, but both ClickHouse and other operators call it unstable and prone to data loss. Tinybird uses a [private fork of it](https://www.tinybird.co/blog/what-i-learned-operating-clickhouse?ref=gouthamve.dev#::text=we%20use%20a%20modified%20zero%2Dcopy%20feature%20(available%20in%20our%20private%20fork) with trade-offs I don’t fully understand.
ClickHouse Cloud actually built a `SharedMergeTree` table that’s native to object storage and properly stateless. But it’s closed source. We can’t use it.
There are alternatives—ByteDance has something that runs mainly against object storage, and Altinity has a fork that compacts data into Iceberg tables before writing to S3—but none of them are the elegant solution I was hoping for.
The TL;DR
My take: basic replication and sharding is good enough for most people. If you’re not hyper-focused on TCO and can run clusters at 50-60% capacity with aggressive rate limiting, you can make this work.
But only for the following assumptions:
- Running ClickHouse + Keeper is straightforward
- The data stays small
- Retention stays small (I’d be very hesitant to run 6+ months of retention)
Further reading:
Sharding and Resharding Strategies in ClickHouseIn this article, we delve into how ClickHouse supports sharding via a distributed via distributed table engineChistaDATA Inc.I’ve operated petabyte-scale ClickHouse® clusters for 5 yearsI’ve been operating large ClickHouse clusters for years. Here’s what I’ve learned about architecture, storage, upgrades, config, testing, costs, and ingestion.TinybirdJavi Santana
All this got me interested in columnar DBs. I expect to dive into DataFusion, IceBerg and the ecosystem soon.