In recent Strix Halo optimization testing, I found that ROCm 6.4.4 with rocWMMA and AMDVLK Vulkan consistently delivered the fastest prompt processing speeds when running quantized models through llama.cpp. However, a recent development from Valve’s Linux graphics team has changed the landscape for AMD users running local LLMs.
Understanding Mesa and AMD Graphics Drivers
Mesa is an open-source graphics library that implements graphics APIs like OpenGL and Vulkan on Linux systems. For AMD users, Mesa includes RADV, the community-developed Vulkan driver that serves as an alternative to AMD’s official AMDVLK driver. These drivers translate application calls into instructions your GPU can ex…
In recent Strix Halo optimization testing, I found that ROCm 6.4.4 with rocWMMA and AMDVLK Vulkan consistently delivered the fastest prompt processing speeds when running quantized models through llama.cpp. However, a recent development from Valve’s Linux graphics team has changed the landscape for AMD users running local LLMs.
Understanding Mesa and AMD Graphics Drivers
Mesa is an open-source graphics library that implements graphics APIs like OpenGL and Vulkan on Linux systems. For AMD users, Mesa includes RADV, the community-developed Vulkan driver that serves as an alternative to AMD’s official AMDVLK driver. These drivers translate application calls into instructions your GPU can execute. The latest Mesa updates include optimizations that directly benefit compute workloads like LLM inference. Users running standard Linux distributions can access these improvements through their package manager when Mesa 25.3 releases, or by installing Mesa from Git for immediate access.
The RADV Performance Improvement
Valve developer Rhys Perry merged three patches into the RADV driver that improve how the driver handles compute units when local data share (LDS) is utilized. The technical implementation focuses on CU mode optimization, which directly impacts how llama.cpp processes prompts on AMD Radeon hardware.
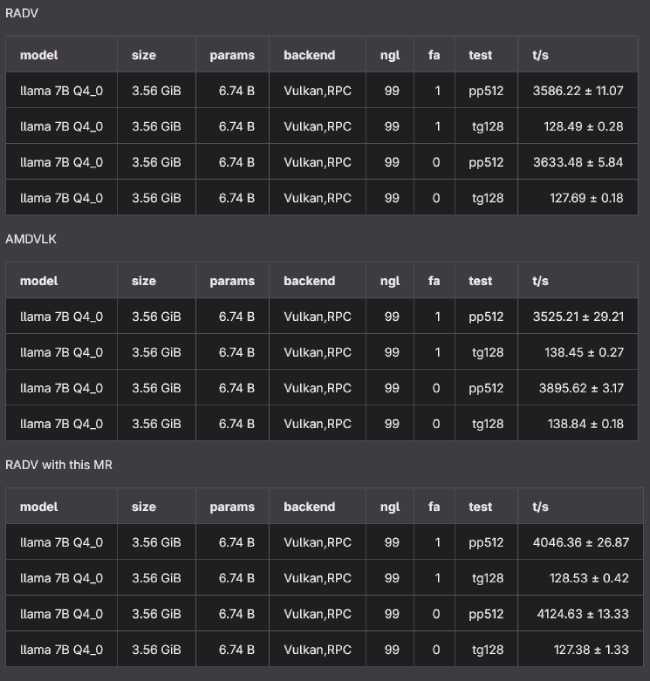
Testing with Llama 2 7B Q4_0 shows the improvement clearly. The benchmark results demonstrate a jump from approximately 3,586 tokens per second to 4,046 tokens per second for 512-token prompt processing. This represents a 13% performance gain for prompt processing workloads.
Benchmark Comparison: Before and After
Previous Strix Halo testing established baseline performance across three driver configurations. ROCm 6.4.4 with rocWMMA typically led in prompt processing, with AMDVLK following, and the previous RADV implementation trailing. Testing the gpt-oss-120b MXFP4 model showed ROCm achieving 788.46 tokens per second, AMDVLK reaching 788.46 tokens per second, and RADV managing 526.13 tokens per second for 512-token prompts.
Fresh benchmarks using the updated Mesa 25.3.0 RC1 demonstrate the impact of the RADV improvements. Testing gpt-oss-120b with various context lengths reveals the following:
| Driver | PP512 (tokens/sec) |
|---|---|
| vulkan_radv (old mesa) | 520.69 ± 3.21 |
| vulkan_radv (new mesa) | 623.88 ± 3.81 |
| rocm | 752.52 ± 7.07 |
| vulkan_amdvlk | 788.46 ± 4.36 |
At standard 512-token prompt processing, the old Mesa version achieved 520.69 tokens per second. The updated Mesa implementation reaches 623.88 tokens per second, while ROCm still leads at 752.52 tokens per second. The gap narrows as context length increases. At 1024 tokens of context, old Mesa delivered 490.68 tokens per second compared to the new Mesa’s 589.18 tokens per second and ROCm’s 728.97 tokens per second.
The pattern continues across longer contexts. At 4096 tokens of context, old Mesa managed 437.23 tokens per second while new Mesa achieves 526.26 tokens per second against ROCm’s 657.79 tokens per second. Even at extended 16384-token contexts, the improvement remains consistent with old Mesa at 298.16 tokens per second, new Mesa at 354.05 tokens per second, and ROCm at 453.83 tokens per second.
Token Generation Performance
Token generation speeds show different characteristics. At 128-token generation with standard context, old Mesa achieved 49.29 tokens per second while new Mesa marginally improved to 49.42 tokens per second. ROCm recorded 46.99 tokens per second in this test. The token generation advantage for Vulkan implementations persists across context lengths, though ROCm maintains its prompt processing lead.
What This Means for Local LLM Users
For users building AMD-based systems for local LLM inference, RADV now presents a more competitive option for prompt processing workloads. The driver functions on consumer AMD Radeon cards without requiring the ROCm stack, which remains officially unsupported on most consumer GPUs. Users can access RADV through standard Mesa installations on Linux distributions.
ROCm with rocWMMA optimization still delivers the fastest prompt processing speeds based on current benchmarks. However, the gap has narrowed substantially. Users who prefer avoiding ROCm complexity or who run hardware where ROCm support requires unofficial modifications now have a stronger alternative.
The token generation characteristics favor Vulkan implementations slightly, meaning RADV provides competitive performance for interactive use cases where generation speed matters more than initial prompt processing. For batch processing or applications that emphasize rapid prompt ingestion, ROCm maintains its advantage.
Practical Implications
The RADV improvements arrive in Mesa 25.3, scheduled for release next month. Users wanting immediate access can build Mesa from Git. The changes apply across AMD’s RDNA architecture, benefiting both discrete GPUs and integrated graphics solutions like the Strix Halo APUs.
For system builders evaluating AMD hardware for local LLM work, the improved RADV performance adds another viable configuration option. Used AMD GPUs with sufficient VRAM become more attractive when considering that competitive performance no longer requires ROCm installation. The broader software compatibility of Vulkan versus ROCm means fewer configuration issues and better support across different model formats and inference engines.
The work from Valve’s graphics team continues demonstrating how gaming-focused optimization efforts benefit computational workloads. As local LLM inference grows in popularity, driver improvements targeting general compute performance directly translate to better tokens per second for quantized model execution.
No comments yet.