Puma 7 is here, and that means your Ruby app is now keep-alive ready. This bug, which existed in Puma for years, caused one out of every 10 requests to take 10x longer by unfairly “cutting in line.” In this post, I’ll cover how web servers work, what caused this bad behavior in Puma, and how it was fixed in Puma 7; specifically an architectural change recommended by MSP-Greg that was needed to address the issue.

For a primer on keep-alive connections: wha…
Puma 7 is here, and that means your Ruby app is now keep-alive ready. This bug, which existed in Puma for years, caused one out of every 10 requests to take 10x longer by unfairly “cutting in line.” In this post, I’ll cover how web servers work, what caused this bad behavior in Puma, and how it was fixed in Puma 7; specifically an architectural change recommended by MSP-Greg that was needed to address the issue.
For a primer on keep-alive connections: what they are and why they are critical for low-latency, performant applications, see our companion post Learn How to Lower Heroku Dyno Latency through Persistent Connections (Keep-alive)
Puma 6 Keepalive bug
When all threads are busy, Puma 6 and prior incorrectly allow a new keep-alive request to “cut the line” like this:

In this image, A is the first request, on a keep-alive connection. After A finishes processing, instead of working on request B, Puma 6 (and prior) incorrectly starts working on C, the next request on the same keep-alive connection. This process repeats until either the keep-alive connection has no more requests or a limit (10) of requests served on a single connection is reached.
That means that C and D both “cut the line” in front of B, just because they came on the same keep-alive connection. In the GitHub issue we described this as “letting one keep-alive connection monopolize a Puma thread.” This is bad behavior, but why did it exist in the first place?
You can read the background of how this was identified, reproduced, and reported in Pumas, Routers & Keepalives—Oh my!. It’s also worth mentioning that this high delay only happens when Puma is “overloaded” with more requests than it has threads. This can happen when the system needs more capacity (when web needs to be scaled), or there is a burst of traffic.
Puma 6 broken Pipe(line) Dreams: The Fast Inline Optimization
Keep-alive line-cutting behavior wasn’t intentionally added to Puma 6; rather, it was an accidental byproduct of an optimization for pipeline connections. This bug wasn’t added recently, either. It’s been part of Puma for a long time. The issue has been independently reported several times over the years, but only recently reproduced in a reliable way. First off, what is HTTP pipelining?
HTTP pipelining is when multiple requests are on the same connection and sent at the same time.

In this image, A, B, C, and D all arrive at the same time. A, B, and C are on the same pipeline connection. The previous case, where one connection “cut in line” in front of another, is not happening here. Either C or D must wait 300ms, and both have an equal chance. That explains pipeline connections, but what was the optimization that led to the keep-alive connection problem?
In Puma, any time spent coordinating the state instead of processing a request is overhead. Normally, when a request is finished, the thread pulls a new request from the queue, which requires housekeeping operations like handling mutexes. To reduce that overhead, a loop was added to handle pipeline connections. With this new code, instead of serving the first request and then sending the remainder back through the regular queue, this loop allowed Puma to process all pipelined requests in order on the same thread.
You can see some of the logic in the Puma 6 code comments:
# As an optimization, try to read the next request from the # socket for a short time before returning to the reactor. fast_check = @status == :run
By default, this “fast inline” behavior was limited to ten requests in a row via a Puma setting max_fast_inline:
# Always pass the client back to the reactor after a reasonable # number of inline requests if there are other requests pending. fast_check = false if requests >= @max_fast_inline &&
@thread_pool.backlog > 0
This optimization for pipelined HTTP requests made sense in isolation. Unfortunately, this codepath was reused for the keep-alive case, where new requests may be sent well after the first one.
While it’s fair to serve the pipeline requests one after another, it’s unfair to treat all keep-alive requests as if they arrived at the same time as the connection.
New goal:
Goal 1: Requests should be processed in the order they’re received, regardless of whether they came from calling accept on a socket or from an existing keep-alive request.
Puma 7 Fixed Pipelines
Instead of letting a pipeline connection monopolize a single thread, Puma 7 now places pipelined connections at the back of the queue as if the next request arrived right after the first. With this new logic, the pipeline request ordering changes to this:

Now, instead of waiting for all the pipelined connections to finish, D is interleaved. One way to think of this is that instead of racing to see which request finishes last, the connections now race to determine which finishes second. This ordering now applies to keep-alive connections in addition to pipeline connections.
Unfortunately, Puma 6 had another optimization called wait_until_not_full that prevents it from accepting more connections than it has threads. That had to be adjusted to accommodate the ability to interleave keep-alive requests with new connections.
Note: Puma 7.0 turned off the keep-alive “fast inline” optimization, but they were reintroduced in Puma 7.1.0. This reintroduction relies on the addition of a new safeguard that ensures an overloaded server will process connections fairly. You can read more about it in the linked Puma issue: Reintroduce keep-alive “fast inline” behavior: 8x faster JRuby performance.
Puma 6 – Not accepting
To understand the wait_until_not_full optimization, you need to understand how a socket works on a web server.
A socket is like a solid door that a process cannot see through. When a web request is sent to a machine, the connection line is outside that door. When the web server is ready, it can choose to open that door and let one connection inside so it can start to process it. This is called the “accept” process or “accepting a connection.”
Puma uses an accept loop that runs in parallel to the main response-serving-threadpool. The accept loop will call “accept” with a timeout in a loop (rather than blocking indefinitely). All Puma processes (workers when running in clustered mode) share the same socket, but they operate in isolation from each other. If all processes tried to claim as many requests as possible, it could lead to a scenario where one process has more work than it can handle, and another is idle. That scenario would look like this:

In this picture, worker 1 boots just slightly faster than worker 2. If it has no limit to the number of requests it accepts, it pulls in A, B, and C right away, even though it only has one thread and can only work on one request. Meanwhile, worker 2 finally boots and finds no requests waiting on the socket.
Note: This unbalanced worker condition is not limited to when workers boot; that’s just the easiest way to visualize the problem. It can also happen due to OS scheduling, request distribution, and GIL/GVL contention for the accept loop (to name a few).
An ideal server with two workers would look like this:
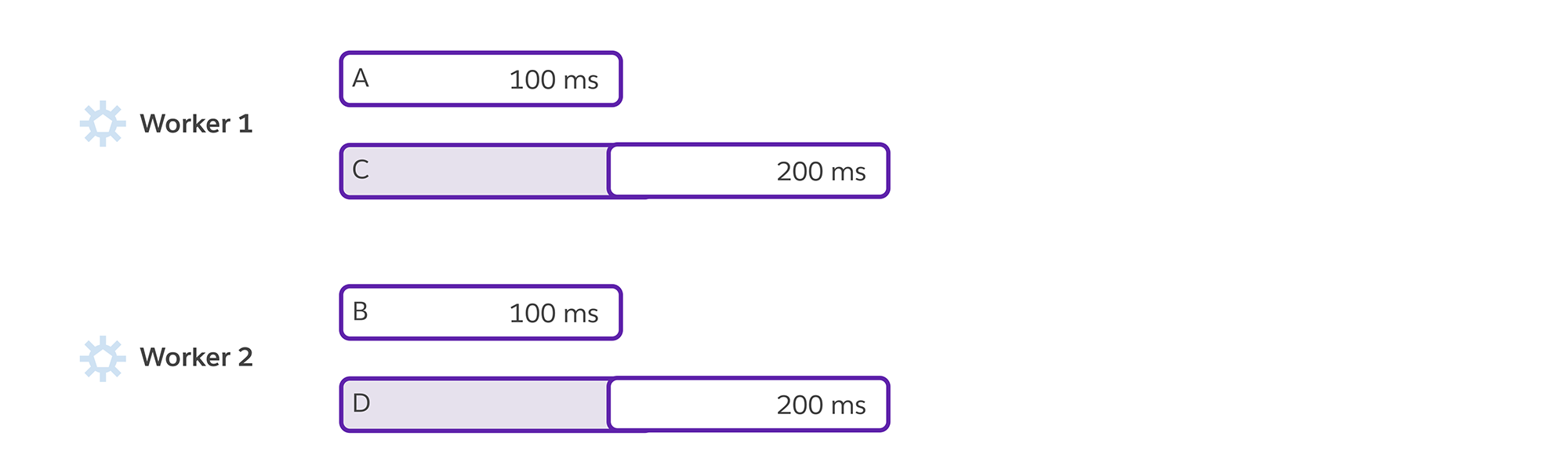
In this picture, requests A, B, C, and D arrive one-after-another. Each process accepts one request and processes it. Because A and B arrived first and there are two processes, they don’t have to wait at all. The Puma 6 wait_until_not_full optimization got us pretty close to this ideal ordering by not accepting a new connection unless it had capacity (free threads) to handle the work:
# Pseudo code
if busy_threads < @max_threads
accept_next_request
else
# Block until a thread becomes idle
@not_full.wait @mutex
end
If you remember the pipeline “interleaved” example with Puma 7, it required that both connections (the pipeline carrying A, B, and C as well as the new connection carrying D) to be in the server at the same time. But wait_until_not_full ensures that it cannot happen since servers were prevented from accepting more connections than threads.
Previously, we introduced this goal:
Goal 1: Requests should be processed in the order they’re received, regardless of whether they came from calling accept on a socket or from an existing keep-alive request.
Now we’ll add:
Goal 2: Requests should be received in the order they’re sent, regardless of whether they came from calling accept on a socket or from an existing keep-alive request.
Puma 7 fixed this problem by never blocking the accept loop. But removing wait_until_not_full reintroduces the worker accept problem behavior: One process might accept more work than it can handle, even if another process has capacity. So we need to add a new goal
Goal 3: Request load should be distributed evenly across all Puma processes (workers) within the server.
Puma 7: Accept more, sleep more
To distribute load evenly across workers, we chose to extend a previously existing sleep-sort strategy, wait_for_less_busy_worker, used in the accept loop. In Puma 6, this strategy prioritized a completely idle worker over one serving a single request. Read more about that strategy in the PR that introduced it.
The new Puma 7 logic does that, and adds a proportional calculation such that a busier process will sleep longer (versus before all busy processes slept the same, fixed amount).
This behavior change also means that the semantics of the wait_for_less_busy_worker DSL have changed. Setting that now corresponds to setting a maximum sleep value.
With all of these fixes in place, the original keep-alive bug is gone. Let’s recap.
Puma keep-alive behavior before and after
Before: Puma 6 (and prior) behaved like this:
One keepalive connection can monopolize one thread for up to ten requests in a row. The accept loop will completely stop when it sees all threads are busy with requests
After: Puma 7 behaves like this:

- The Puma 7 fix ensures fairness: New requests on a keep-alive connection (C, D) must wait their turn behind previously accepted requests (B).
- The accept loop never fully blocks. It now slows down in proportion to the system load.
It’s important to note that Puma 7 does not give your application more request capacity. It still has to do the same amount of work with the same resources. If you overload the Puma 7 server, there will still be some delay in processing requests, but now that delay is evenly and fairly distributed.
Rollout and reception
The effort to find, reproduce, report, investigate, and eventually fix this behavior was massive. It involved many developers for well over a year. When you see it all laid out linearly like this, it might seem that we should have been able to patch this faster, but it involved many overlapping and conflicting pieces that needed to be understood to even begin to work on the problem.
A huge shout-out to Greg, who landed the fix that went out in Puma 7.0.0.pre1. Plenty more changes went into the 7.x release, but this behavior change with keep-alive connections received by far the most amount of maintainer/contributor hours and scrutiny. We let the pre-release (containing only that fix) sit in the wild for several weeks and collected live feedback to gauge the impact. We were fairly cautious and even blocked the release based on what turned out to be a Ruby core bug that was affecting Tech Empower benchmarks.
Once we were happy with the results, I cut a release of 7.0.0 a few hours before the opening keynote of RailsWorld used it live on stage. Neat.
The reception has been overwhelmingly positive. Users of Heroku’s Router 2.0 have reported a massive reduction in response time, though any app that receives keep-alive connections will benefit.
Upgrade and Unlock Lower App Latency
The fix in Puma 7 ensures that your Ruby app is finally capable of realizing the low-latency, high-throughput benefits promised by HTTP/1.1 keep-alives and Heroku Router 2.0.
If you previously experienced unfair latency spikes and disabled keep-alives (in config/puma.rb or via a Heroku lab’s feature), we strongly recommend you upgrade to Puma 7.1.0+.
Follow these steps to upgrade today:
1. Install the latest Puma version
$ gem install puma
2. Upgrade your application
$ bundle update puma
3. Check the results and deploy
$ git add Gemfile.lock
$ git commit -m "Upgrade Puma version"
$ git push heroku
Note:
Your application server won’t hold keep-alive connections if they’re turned off in Puma config, or at the Router level.
You can view the Puma keep-alive settings for your Ruby application by booting your server with PUMA_LOG_CONFIG. For example:
$ PUMA_LOG_CONFIG=1 bundle exec puma -C config/puma.rb
# ...
- enable_keep_alives: true
You can also see the keep-alive router settings on your Heroku app by running:
$ heroku labs -a <my-app> | grep keepalive
#...
[ ] http-disable-keepalive-to-dyno Disable Keepalives to Dynos in Router 2.0.
We recommend all Ruby apps upgrade to Puma 7.1.0+ today!