We started Inception to build the world’s fastest, most efficient AI models. In February 2025, we launched our first model, Mercury, which is the first commercially available diffusion-based LLM (dLLM). Mercury is up to 10X faster and more efficient than today’s LLMs while delivering best-in-class quality.
Today, we are pleased to announce two major milestones. First, we recently closed a $50M financing round, led by Menlo Ventures and joined by several other top venture funds and angels, including Andrew Ng and Andrej Karpathy. These investors share our belief that dLLMs are the future of language models and are betting on our ability to scale this technology and bring it …
We started Inception to build the world’s fastest, most efficient AI models. In February 2025, we launched our first model, Mercury, which is the first commercially available diffusion-based LLM (dLLM). Mercury is up to 10X faster and more efficient than today’s LLMs while delivering best-in-class quality.
Today, we are pleased to announce two major milestones. First, we recently closed a $50M financing round, led by Menlo Ventures and joined by several other top venture funds and angels, including Andrew Ng and Andrej Karpathy. These investors share our belief that dLLMs are the future of language models and are betting on our ability to scale this technology and bring it to every developer and enterprise.
Second, we are releasing a more powerful version of Mercury, our flagship dLLM. This release delivers improvements in coding, instruction following, mathematical problem solving, and knowledge recall.

See footnote for details on methodology.
The diffusion difference
Today’s LLMs are painfully slow and expensive. They use a technique called autoregression to generate tokens, letters, code, and words sequentially. One. At. A. Time. This is a structural and unavoidable bottleneck.
Inception’s Mercury dLLMs use a different approach - diffusion - to generate answers in parallel.
Rather than predicting tokens one at a time, dLLMs generate entire blocks of language in parallel. The output starts as a broad, noisy sketch, then through an iterative “denoising” process rapidly converges on the best answer. Tokens (and letters, words, and code) emerge all at once, not one at a time.
This is a fundamentally better way to generate language: 10X faster and more efficient while maintaining best in class quality.

Developer and enterprise momentum
Developers and enterprises have quickly jumped on the Mercury bandwagon, taking advantage of dLLM’s performance to change what’s possible.
They are building AI assistants that work alongside software engineers as they edit code, with responsive autocomplete, intelligent tab suggestions, and rapid edit applications. Voice agents that help customers quickly get to what they need. And AI co-pilots that work alongside designers, creatives, and analysts, making suggestions and edits, managing workflows, and doing deep research.
All of these solutions operate instantly and in-the-flow. No need to input a query then go pour a cup of coffee while waiting for the response.
What’s new with Mercury
The new version of Mercury features:
Larger models and more data. Increasing parameter count and training on broader, higher-quality datasets to unlock stronger reasoning, coding, and instruction-following capabilities
Key architectural upgrades. Advancing the denoiser architecture to improve efficiency, expressiveness, and overall model capability
Major training and inference improvements. Designing new training objectives, introducing faster and more accurate inference algorithms, building optimized kernels, and launching a brand-new serving engine
These improvements deliver massive gains in quality across knowledge, coding, instruction following, and mathematical benchmarks.
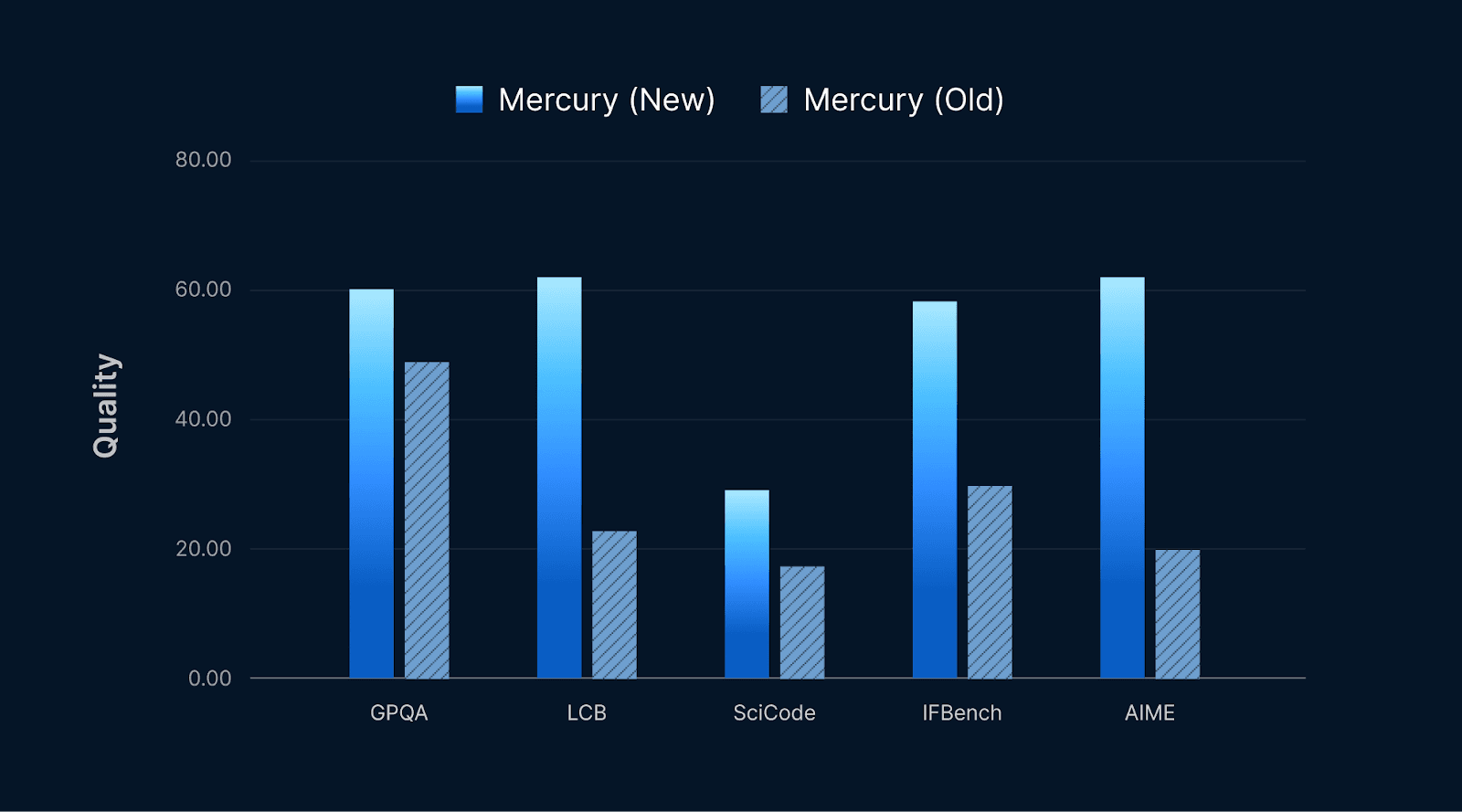
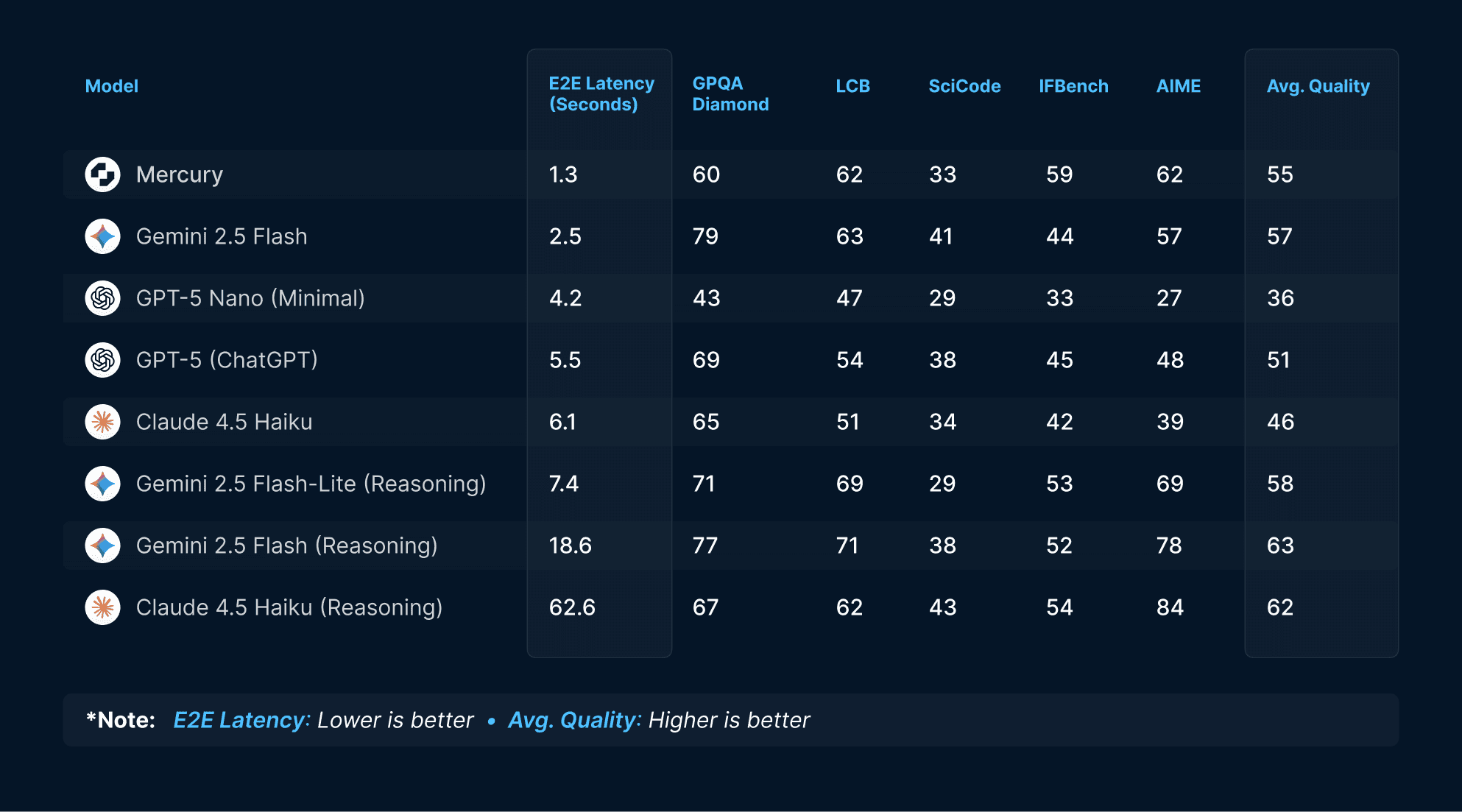
Here are the benchmark results used in the above figures.
Using Mercury
The upgraded Mercury model is available on our API Platform and through our partners, including OpenRouter and Poe.
Want to check it out? New users receive 10 million free tokens. Our API is OpenAI API compatible, so it only takes seconds to integrate.
Mercury’s pricing is unchanged: $0.25 per 1M input tokens and $1.00 per 1M output tokens. Is that a good value? We think so! For example, Mercury provides higher quality than Claude 4.5 Haiku at one-fifth the latency and less than one-quarter the price.
What’s Next?
This upgrade is a big leap, but it is only the beginning. We’re pushing to build new capabilities, integrate new modalities, and deliver speed, speed, speed. If that sounds interesting - if you want to help build the future of diffusion LLMs - let’s talk: sales@inceptionlabs.ai.
See our jobs: https://jobs.gem.com/inception
Access our API Platform: platform.inceptionlabs.ai
Try out Mercury: chat.inceptionlabs.ai
About Inception
Inception creates the world’s fastest, most efficient AI models. Today’s autoregression LLMs generate tokens sequentially, which makes them painfully slow and expensive. Inception’s diffusion-based LLMs (dLLMs) generate answers in parallel. They are 10X faster and more efficient, making it possible for any business to create instant, in-the-flow AI solutions. Inception’s founders helped invent diffusion technology, which is the industry standard for image and video AI, and the company is the first to apply it to language. Based in Palo Alto, CA, Inception is backed by A-list venture capitalists, including Menlo Ventures, Mayfield, M12 (Microsoft’s venture fund), Snowflake Ventures, Databricks Investment, and Innovation Endeavors.
* Note: Quality is the average of GPQA Diamond, LCB, IFBench, AIME 2025, and SciCode. E2E latency is measured using Artificial Analysis’s methodology, described here.