Published: March 19, 2024
Revised: January 29, 2025 in 1e17751
Tagged: C, Djot, Neovim, Rust, Tree-sitter
Contents
- Our subset
- Simple beginnings
- Missing features
- External scanner
- [Div markers closes open paragraphs ]…
Published: March 19, 2024
Revised: January 29, 2025 in 1e17751
Tagged: C, Djot, Neovim, Rust, Tree-sitter
Contents
- Our subset
- Simple beginnings
- Missing features
- External scanner
- Div markers closes open paragraphs
- Nested blocks
- Div markers
- Handling conflicts
- Some tests
- Using tree-sitter for something useful
- Syntax highlighting
- Language injection
- Using our grammar with Neovim
- Jumping and selecting with textobjects
- Embedding the grammar with Rust
- Within edge-cases lies complexity
One of my favorite features in Neovim is the Tree-sitter integration. It allows for fast syntax highlighting that works well even in an error state (often the case when you’re editing code), and it has additional semantics (you can differentiate between function parameters and local variables).
With nvim-treesitter-textobjects you can also jump between nodes (such as ]c to jump to next class) or target deletion (cif to delete the function body and enter insert mode). An amazing feature as it works across languages, no matter how they look like, as long as they have a Tree-sitter grammar (most do).
But, you might wonder what does a Tree-sitter grammar look like, and how do you create one for a language?
I started thinking about this and before I knew it I was trying to make my own parser for Djot (a markup language similar to Markdown). There are some good tutorials on how to get started, but not on some more advanced things.
I spent quite some time trying to figure it out—while refreshing my 10 year old knowledge of grammars—and decided to document some of my findings.
The post spiraled out of control a little, and it will go through:
- How to use an external scanner
- Using Tree-sitter’s built-in conflicts resolution
- Syntax highlighting with language injection
- Use the grammar from Neovim for syntax highlighting and textobjects
- Embed the grammar into this Blog for syntax highlighting The source code for the complete grammar we’ll develop can be found on GitHub.
Our subset
For the purpose of this blog post, we’ll implement a small subset of Djot, where we’ll support:
- Paragraphs
- Divs
- Code blocks
- Emphasis This will allow us to parse markup like this:
This is a
multiline _paragraph_
:::
This is a paragraph inside a div
:::
```gleam
let x = 2;
\(Yes, the `sdjot` highlight uses our grammar\.\)
At first blush, this seems like it’s too simple to require anything more complex than some simple grammar rules, but later on we’ll see that even these simple rules requires a bit more effort to fully support\.
## [Simple beginnings](#Simple-beginnings)
The point of this post isn’t to go through how the Tree-sitter grammar description in `grammar.js` works\. The [Tree-sitter docs](https://tree-sitter.github.io/tree-sitter/creating-parsers) goes through how to get started\. I named the project `sdjot` and this is the `grammar.js` we’ll start with:
module.exports = grammar({ name: “sdjot”, // Skip carriage returns. // We could skip spaces here as well, but the actual markup language // has significant spaces in some places, so let’s remove them here too. extras: () => [“\r”], rules: { document: ($) => repeat($.block), // All blocks should end with a newline, but we can also parse multiple newlines. block: ($) => choice($.div, $.code_block, $.paragraph, “\n”), // A div contains other blocks. div: ($) => prec.left(seq($.div_marker, “\n”, repeat($.block), $.div_marker, “\n”)), div_marker: () => “:::”, // Code blocks may have a language specifier. code_block: ($) => seq( $.code_block_marker, optional($.language), “\n”, optional($.code), $.code_block_marker, ), code_block_marker: () => “```”, code: () => repeat1(seq(/1*/, “\n”)), language: () => /2+/, // A paragraph contains inline content and is terminated by a blankline // (two newlines in a row). paragraph: ($) => seq(repeat1(seq($._inline, “\n”)), “\n”), // The markup parser could separate block and inline parsing into separate steps, // but we’ll do everything in one parser. _inline: ($) => repeat1(choice($.emphasis, $.text)), emphasis: ($) => prec.left(seq(“”, $.inline, “”)), text: () => /1/, }, });
It recognizes paragraphs with text and emphasis, and it identifies divs and code blocks\.
We can create an `example-file` with these contents:
- ::: A paragraph with emphasis inside a div
- ::
And parse it with the `tree-sitter` cli:
$ tree-sitter parse example-file (document [0, 0] - [5, 0] (div [0, 0] - [4, 0] (div_marker [0, 0] - [0, 3]) (paragraph [1, 0] - [3, 0] (emphasis [1, 12] - [1, 27])) (div_marker [3, 0] - [3, 3])))
Et voilà\!
### [Missing features](#Missing-features)
But I told you it wasn’t supposed to be this easy, and there are features missing from our parser\. Most notably:
1. There can be an arbitrary number of `:`, allowing divs to be nested\.
1. Closing a div should close other open blocks \(divs and paragraphs in our case\)\.
In essence, we need to be able to parse this:
- ::: Top-level div
- ::: A paragraph inside a second div, both closed when the top-level div is closedj
- ::
This is… Complicated\.
Sure, we can work around the varying levels of `:` with something hacky like enumerating the number of colons, using something like this:
div: ($) => choice($._div3, $._div4, $._div5, $._div6, $._div7, $._div8), _div3: ($) => seq(/:{3}/, $._inside_div, /:{3}/, “\n”), _div4: ($) => seq(/:{4}/, $._inside_div, /:{4}/, “\n”), _div5: ($) => seq(/:{5}/, $._inside_div, /:{5}/, “\n”), _div6: ($) => seq(/:{6}/, $._inside_div, /:{6}/, “\n”), _div7: ($) => seq(/:{7}/, $._inside_div, /:{7}/, “\n”), _div8: ($) => seq(/:{8}/, $._inside_div, /:{8}/, “\n”), _inside_div: ($) => prec.left(“\n”, repeat($._block)),
But it’s not *neat*, and automatically closing contained blocks is much harder \(to my brain it seems impossible, but I’m no expert\)\.
With an external scanner we can do this \(and more\)\.
## [External scanner](#External-scanner)
A Tree-sitter parser is actually a C program\. The grammar we’ve seen has been described in JavaScript, but it’s only used as a description to generate the parser in C\. If you’re a masochist, you can take a look at it in `src/parser.c` after running `tree-sitter generate`\.
An external scanner is just some custom C code that’s inserted into the parser, and it allows us to override the parser precedence, keep track of a context state, or whatever else we might need or want to do\.
To get started the [official docs](https://tree-sitter.github.io/tree-sitter/creating-parsers#external-scanners) was pretty good\. Basically you need to:
1. Create a `src/scanner.c` and include it in `binding.gyp` `bindings/rust/build.rs`\.
1. Setup `externals` tokens in `grammar.js` and a matching C enum in `scanner.c`\.
1. Define and implement five C functions\.
Let’s take a look\.
### [Div markers closes open paragraphs](#Div-markers-closes-open-paragraphs)
Let’s start by closing a paragraph early when a `:::` is encountered\. This is simpler because we can solve this without storing any state\.
When parsing `$.paragraph` we’ll give the parser a choice between ending the paragraph on a newline or on our new `$._close_paragraph` token:
paragraph: ($) => seq(repeat1(seq($._inline, “\n”)), choice(“\n”, $._close_paragraph)),
`$._close_paragraph` is handled by the external scanner, which is specified using the `externals` field:
externals: ($) => [$._close_paragraph],
Now let’s turn our attention to `src/scanner.c`\. The tokens in `externals` gets assigned an incremented number, starting from 0… Just like an enum in C\!
// We only have a single element right now, but keep in mind that the order
// must match the externals array in grammar.js.
typedef enum { CLOSE_PARAGRAPH } TokenType;
The five functions we need to implement are these:
// You should replace sdjot with whatever project name you chose.
bool tree_sitter_sdjot_external_scanner_scan(void *payload, TSLexer *lexer,
const bool *valid_symbols) {
// All the scanning goes here.
return false;
}
// If we need to allocate/deallocate state, we do it in these functions.
void *tree_sitter_sdjot_external_scanner_create() { return NULL; }
void tree_sitter_sdjot_external_scanner_destroy(void *payload) {}
// If we have state, we should load and save it in these functions.
unsigned tree_sitter_sdjot_external_scanner_serialize(void *payload,
char *buffer) {
return 0;
}
void tree_sitter_sdjot_external_scanner_deserialize(void *payload, char *buffer,
unsigned length) {}
Because we won’t use any state, we’ll only have to update the `scan` function\.
What you’re supposed to do is check `valid_symbols` for the tokens we can return at any point in time, and return `true` if any was found:
bool tree_sitter_sdjot_external_scanner_scan(void *payload, TSLexer *lexer, const bool *valid_symbols) { if (valid_symbols[CLOSE_PARAGRAPH] && parse_close_paragraph(lexer)) { return true; } return false; }
To decide if we’re going to close the paragraph early, we’ll look ahead for any `:::`, and if so we’ll close it without consuming any characters\. This might not be the most efficient solution because we’ll have to parse the `:::` again, but it gets the job done\.
The matched token should be stored in `lexer->result_symbol`:
static bool parse_close_paragraph(TSLexer *lexer) { // Mark the end before advancing so that the CLOSE_PARAGRAPH token doesn’t // consume any characters. lexer->mark_end(lexer); uint8_t colons = consume_chars(lexer, ‘:’); if (colons >= 3) { lexer->result_symbol = CLOSE_PARAGRAPH; return true; } else { return false; } }
Note that the resulting token will mark any symbol we advance over as owned by that token\. So `:::` would be marked as `_close_paragraph` \(which will be ignored by the output since it begins with an underscore\), instead of `div_marker`\. To prevent this, we turn `_close_paragraph` into a zero-width token by marking the end before advancing the lexer\.
How do we advance the lexer? We call `lexer->advance`:
static uint8_t consume_chars(TSLexer *lexer, char c) { uint8_t count = 0; while (lexer->lookahead == c) { lexer->advance(lexer, false); ++count; } return count; }
This is almost all we can do with the lexer\. We only process one character at a time, cannot look behind, and our only tool to look ahead is to `mark_end` at the correct place\. \(We can also query the current column position\.\)
With this we have a working external scanner and div tags now close paragraphs:
- ::: A paragraph inside a div
- ::
$ tree-sitter parse example-file (document [0, 0] - [4, 0] (div [0, 0] - [3, 0] (div_marker [0, 0] - [0, 3]) (paragraph [1, 0] - [2, 0]) (div_marker [2, 0] - [2, 3])))
### [Nested blocks](#Nested-blocks)
To automatically close other open blocks we need to add some context to our parser, which means we’ll need state management\.
The small subset we’re implementing is only concerned with closing divs—because it would be a terribly long post otherwise—but I’ll try to implement this in a general manner, to be more indicative of a real-world parser\.
Our strategy is this:
1.
A div can have a varying number of `:` that must match\.
Therefore we’ll parse colons in an external scanner and store it on a stack\.
1.
When we find a div marker, we’ll need to decide if it should start a new div, or close an existing one\.
We’ll look at the stack of open blocks and see if we find a match\.
1.
If we have need to close a nested div, that is if we want to close a div further down the stack, we need to close the nested div\(s\) first\.
Thus we’ll introduce a `block_close` marker that ends a div, and leave the ending div marker as optional\.
First we’ll ask the grammar to let the external scanner manage the begin and end tokens\. We’ll use a `_block_close` marker to end the div, and leave the end marker optional\. \(You could probably use a `choice()` between the two, but this made more sense to me when I was implementing it\.\)
div: ($) => prec.left( seq( // A rule starting with “_” will be hidden in the output, // and we can use “alias” to rename rules. alias($._div_marker_begin, $.div_marker), “\n”, repeat($._block), $._block_close, optional(alias($._div_marker_end, $.div_marker)) ) ), externals: ($) => [ $._close_paragraph, $._block_close, $._div_marker_begin, $._div_marker_end, // This is used in the scanner internally, // but shouldn’t be used by the grammar. $._ignored, ],
And remember to update the list of external tokens in the scanner \(order matters\):
typedef enum { CLOSE_PARAGRAPH, BLOCK_CLOSE, DIV_MARKER_BEGIN, DIV_MARKER_END, IGNORED } TokenType;
Then to our stack of blocks\.
I used a `Block` type to keep track of the type and number of colons:
// In a real implementation we’ll have more block types. typedef enum { DIV } BlockType; typedef struct { BlockType type; uint8_t level; } Block;
I know that `level` isn’t the best name, but I couldn’t find a very good general name for the number of colons, indentation level, etc\. With sum types you could model it in a clearer way, like this:
enum Block { Div { colons: u32 }, Footnote { indent: u32 }, // etc }
> I will, in fact, claim that the difference between a bad programmer and a good one is whether he considers his code or his data structures more important\. Bad programmers worry about the code\. Good programmers worry about data structures and their relationships\.
But I digress, I’ll go with `level` like a bad programmer\.
Another joy of programming C is that you’ll get to re-implement standard data structures such as a growable stack\. It’s not truly difficult, but it’s annoying and bug-prone\.
Luckily, during the time I’m writing this blog post, [tree-sitter 0\.22\.1](https://github.com/tree-sitter/tree-sitter/releases/tag/v0.22.1) was released with an array implementation\. So now I don’t have to show you my shoddy stack implementation, and we can use their array for our stack instead\.
We’ll shove our `Array` of `Block*` into a `Scanner` struct, because we’ll need to track more data later:
#include “tree_sitter/array.h” typedef struct { Array(Block *) * open_blocks; } Scanner;
When you manage state in tree-sitter, you need to do some data management in the `tree_sitter_` functions we defined earlier\.
Allocations are managed in the `_create` and `_destroy` functions\. Also new for 0\.22\.1 is the recommendation to use `ts_` functions for allocations, to allow consumers to override the default allocator:
#include “tree_sitter/alloc.h”
void *tree_sitter_sdjot_external_scanner_create() {
Scanner *s = (Scanner *)ts_malloc(sizeof(Scanner));
// This is how you create an empty array
s->open_blocks = ts_malloc(sizeof(Array(Block *)));
array_init(s->open_blocks);
return s;
}
void tree_sitter_sdjot_external_scanner_destroy(void *payload) {
Scanner *s = (Scanner *)payload;
// I haven’t shown the allocation of the blocks yet,
// but keep in mind that array_delete does not deallocate any memory
// you store in the array itself.
for (size_t i = 0; i < s->open_blocks->size; ++i) {
// I use array_get even though you can index the contents directly.
ts_free(array_get(s->open_blocks, i));
}
// The array is a growable one, array_delete ensures that the
// memory is deleted.
array_delete(s->open_blocks);
ts_free(s);
}
I allocate the blocks in a `push_block` helper:
static void push_block(Scanner *s, BlockType type, uint8_t level) { Block *b = ts_malloc(sizeof(Block)); b->type = type; b->level = level; // Grows the stack automatically. array_push(s->open_blocks, b); }
You also need to define the serialize functions\. These store and retrieve the managed state, to allow tree-sitter to backtrack\.
unsigned tree_sitter_sdjot_external_scanner_serialize(void *payload, char *buffer) { Scanner *s = (Scanner *)payload; unsigned size = 0; for (size_t i = 0; i < s->open_blocks->size; ++i) { Block *b = *array_get(s->open_blocks, i); buffer[size++] = (char)b->type; buffer[size++] = (char)b->level; } return size; } void tree_sitter_sdjot_external_scanner_deserialize(void *payload, char *buffer, unsigned length) { Scanner *s = (Scanner *)payload; array_init(s->open_blocks); size_t size = 0; while (size < length) { BlockType type = (BlockType)buffer[size++]; uint8_t level = (uint8_t)buffer[size++]; push_block(s, type, level); } }
And that’s the \(initial\) state management taken care of\!
### [Div markers](#Div-markers)
Of course, we haven’t used our state yet\. Let’s change that\.
First, let’s add the `parse_div` entry point to our scan function:
bool tree_sitter_sdjot_external_scanner_scan(void *payload, TSLexer *lexer,
const bool *valid_symbols) {
Scanner *s = (Scanner *)payload;
// Paragraph needs to be closed before we try to close divs.
if (valid_symbols[CLOSE_PARAGRAPH] && parse_close_paragraph(lexer)) {
return true;
}
// Check valid_symbols inside parse_div because of multiple valid symbols.
if (parse_div(s, lexer, valid_symbols)) {
return true;
}
return false;
}
Because advancing the lexer is primitive, and we cannot “go back a char”, it’s important to only advance it if we really need to\. Therefore we always need to check `valid_symbols` before we continue:
static bool parse_div(Scanner *s, TSLexer *lexer, const bool *valid_symbols) { if (!valid_symbols[DIV_MARKER_BEGIN] && !valid_symbols[DIV_MARKER_END]) { return false; } // … }
Next we’ll need to consume all colons we’re at, and only continue if we see at least three:
static uint8_t consume_chars(TSLexer *lexer, char c) { uint8_t count = 0; while (lexer->lookahead == c) { lexer->advance(lexer, false); ++count; } return count; } static bool parse_div(Scanner *s, TSLexer *lexer, const bool *valid_symbols) { // … uint8_t colons = consume_chars(lexer, ‘:’); if (colons < 3) { return false; } // … }
Opening a new div is simple; we push the block and register the number of colons:
push_block(s, DIV, colons); lexer->result_symbol = DIV_MARKER_BEGIN; return true;
But to the decide if we should open or close a div, we need a way to search through the stack\. This function does that, while also returning how many blocks deep into the stack we found the div \(which we’ll use shortly\):
// How many blocks from the top of the stack can we find a matching block? // If it’s directly on the top, returns 1. // If it cannot be found, returns 0. static size_t number_of_blocks_from_top(Scanner *s, BlockType type, uint8_t level) { for (int i = s->open_blocks->size - 1; i >= 0; –i) { Block *b = *array_get(s->open_blocks, i); if (b->type == type && b->level == level) { return s->open_blocks->size - i; } } return 0; } static bool parse_div(Scanner *s, TSLexer *lexer, const bool *valid_symbols) { // … size_t from_top = number_of_blocks_from_top(s, DIV, colons); // We could check if either DIV_MARKER_BEGIN or DIV_MARKER_END are valid here, // but as the grammar is set up they’re both always valid at the same time. if (from_top > 0) { // Close the current div, and all blocks above. } else { // No matching div to close, let’s open one. lexer->mark_end(lexer); push_block(s, DIV, colons); lexer->result_symbol = DIV_MARKER_BEGIN; return true; } }
But we have a problem: when we want to close the div, we want to be able to output multiple tokens\.
For example, with this type of input:
- :::
- ::::
- :::::: text
- ::
We’ll have a stack of 3 divs when we see the closing `:::` marker:
7 (top) 5 3 (the one we want to close)
In the code above, `from_top` will be `3` and we need to output 4 tokens: 3 `BLOCK_CLOSE` \(one for each div\) and 1 `DIV_MARKER_END` \(for the last `:::`\)\. But the scanner can only output a single token at a time\.
The way I solved this is by introducing more state to the Scanner\. Specifically, I introduced a `blocks_to_close` variable that we’ll use to output `BLOCK_CLOSE`, and some variables to output \(and consume\) the `DIV_MARKER_END`\.
typedef struct { Array(Block *) * open_blocks; // How many BLOCK_CLOSE we should output right now? uint8_t blocks_to_close; // Delayed output of a token. TokenType delayed_token; // Allows us to consume the width of a delayed token. uint8_t delayed_token_width; } Scanner;
We need to remember to update the create and serialize functions too\.
Serialize:
buffer[size++] = (char)s->blocks_to_close; buffer[size++] = (char)s->delayed_token; buffer[size++] = (char)s->delayed_token_width;
Deserialize:
s->blocks_to_close = (uint8_t)buffer[size++]; s->delayed_token = (TokenType)buffer[size++]; s->delayed_token_width = (uint8_t)buffer[size++];
We’ll use `IGNORED` as the unused token, so we’ll need to reset it when we create the scanner:
s->blocks_to_close = 0; s->delayed_token = IGNORED;
Now when we scan we should first check `blocks_to_close` and then `delayed_token`, before we scan other things:
bool tree_sitter_sdjot_external_scanner_scan(void *payload, TSLexer *lexer, const bool *valid_symbols) { Scanner *s = (Scanner *)payload; if (valid_symbols[BLOCK_CLOSE] && handle_blocks_to_close(s, lexer)) { return true; } if (output_delayed_token(s, lexer, valid_symbols)) { return true; } // Scan the other stuff }
When we see `blocks_to_close > 0`, we should output a `BLOCK_CLOSE` and remove the top block \(with some sanity checks for good measure\):
static void remove_block(Scanner *s) { if (s->open_blocks->size > 0) { ts_free(array_pop(s->open_blocks)); if (s->blocks_to_close > 0) { –s->blocks_to_close; } } } static bool handle_blocks_to_close(Scanner *s, TSLexer *lexer) { if (s->open_blocks->size == 0) { return false; } // If we reach eof with open blocks, we should close them all. if (lexer->eof(lexer) || s->blocks_to_close > 0) { lexer->result_symbol = BLOCK_CLOSE; remove_block(s); return true; } return false; }
With this we can output multiple `BLOCK_CLOSE`, and now to handle delayed tokens:
static bool output_delayed_token(Scanner *s, TSLexer *lexer,
const bool *valid_symbols) {
if (s->delayed_token == IGNORED || !valid_symbols[s->delayed_token]) {
return false;
}
lexer->result_symbol = s->delayed_token;
s->delayed_token = IGNORED;
// With delayed_token_width we can consume the ending :::, for example.
while (s->delayed_token_width–) {
lexer->advance(lexer, false);
}
lexer->mark_end(lexer);
return true;
}
Another way to design this is to have a stack of delayed tokens and then just pop that\. It’s certainly more powerful, I just happened to choose this way when I was playing around with it because it’s more explicit and it felt a little easier to follow what was happening\.
Either way, we can now implement the div end handling\. In `parse_div`:
size_t from_top = number_of_blocks_from_top(s, DIV, colons); if (from_top > 0) { // Found a div we should close. close_blocks_with_final_token(s, lexer, from_top, DIV_MARKER_END, colons); return true; } else { lexer->mark_end(lexer); push_block(s, DIV, colons); lexer->result_symbol = DIV_MARKER_BEGIN; return true; }
`close_blocks_with_final_token` is a general helper that sets up the number of blocks to close and the final token:
static void close_blocks_with_final_token(Scanner *s, TSLexer *lexer, size_t count, TokenType final, uint8_t final_token_width) { remove_block(s); s->blocks_to_close = s->blocks_to_close + count - 1; lexer->result_symbol = BLOCK_CLOSE; s->delayed_token = final; s->delayed_token_width = final_token_width; }
Now we can finally try to close divs:
- :::::
- ::
- :::::: Divception
- ::
$ tree-sitter parse example-file (document [0, 0] - [6, 0] (div [0, 0] - [6, 0] (div_marker [0, 0] - [0, 5]) (div [1, 0] - [4, 3] (div_marker [1, 0] - [1, 3]) (div [2, 0] - [4, 0] (div_marker [2, 0] - [2, 7]) (paragraph [3, 0] - [4, 0])) (div_marker [4, 0] - [4, 3]))))
We can see that it parses without error, the last marker closes the *second* div correctly, and the last marker captures the final `:::`\.
While I’m jumping to a working implementation directly in this post, when I first did this that was of course not the case\. I found the `-d` argument useful to see what characters are consumed and what token is output in each step\.
Here’s a part of the output \(when scanning the final `:::`\), with some comments to point out some interesting things:
$ tree-sitter parse example-file -d
…
process version:0, version_count:1, state:34, row:4, col:0
lex_external state:4, row:4, column:0
consume character:‘:’ // Scan :::
consume character:‘:’
consume character:‘:’
lexed_lookahead sym:_close_paragraph, size:0 // Output _close_paragraph
reduce sym:paragraph_repeat1, child_count:2
shift state:17
process version:0, version_count:1, state:17, row:4, col:0
lex_external state:3, row:4, column:0 // Still on first :
consume character:‘:’ // Scan ::: again
consume character:‘:’
consume character:‘:’
lexed_lookahead sym:_block_close, size:0 // Close div with _block_close
reduce sym:paragraph, child_count:2
shift state:12
process version:0, version_count:1, state:12, row:4, col:0
lex_external state:5, row:4, column:0 // Still on first :
lexed_lookahead sym:_block_close, size:0 // Close second div with _block_close
reduce sym:div, child_count:4
shift state:12
process version:0, version_count:1, state:12, row:4, col:0
lex_external state:5, row:4, column:0 // Still on first :
consume character:‘:’ // Consume :::
consume character:‘:’
consume character:‘:’
lexed_lookahead sym:div_marker, size:3 // div_marker is size 3, marks :::
shift state:23
While the output seems confusing, when you know what to look for it’s very useful\. I’ve found that a deliberate process, where I look at a single character at a time, helps me get through the problems I’ve encountered so far\.
## [Handling conflicts](#Handling-conflicts)
Our grammar works pretty well, but there are issues you might want to fix\. One issue, that took much longer to figure out than I care to admit, is adding a fallback to text when a markup rule doesn’t match\.
A simple example for our grammar is a single underscore in a paragraph:
a_b
I’d assume this would produce a paragraph with text, but instead we get an error:
$ tree-sitter parse example-file (document [0, 0] - [2, 0] (ERROR [0, 0] - [0, 3]))
This is weird, because one of the main selling points of Tree-sitter is the GLR algorithm, which should explore the different interpretations to find something that succeeds\. But for some reason, it doesn’t trigger for us\.
Let’s take a look\. These are the relevant lines from the grammar:
_inline: ($) => repeat1(choice($.emphasis, $.text)), emphasis: ($) => prec.left(seq(“”, $.inline, “”)), text: () => /1/,
When we try to match a `_` then the grammar can match either `emphasis` or `_text` because `_` matches both `"_"` and `/[^\n]/`\. The issue seems to be that Tree-sitter doesn’t recognize this as a conflict\.
If we instead add a fallback with a `_` string then Tree-sitter will treat it as a conflict:
_inline: ($) => repeat1(choice($.emphasis, $.text, $.fallback)), emphasis: ($) => prec.left(seq(“”, $.inline, “”)), // prec.dynamic() is used during conflict resolution to choose which // branch to choose if multiple succeed. fallback: () => prec.dynamic(-100, “”), text: () => /1/,
And when we call `tree-sitter generate` we’re made aware of the conflict:
$ tree-sitter generate
Unresolved conflict for symbol sequence:
‘’ • ‘’ …
Possible interpretations:
1: (fallback ‘’) • ‘’ …
2: (emphasis ‘’ • inline ‘’) (precedence: 0, associativity: Left)
Possible resolutions:
1: Specify a higher precedence in emphasis than in the other rules.
2: Specify a higher precedence in _fallback than in the other rules.
3: Specify a left or right associativity in _fallback
4: Add a conflict for these rules: emphasis, _fallback
What we want to do is mark them as a conflict that’s supposed to exist in the grammar using the `conflicts` field:
conflicts: ($) => [[$.emphasis, $._fallback]],
And now we can parse paragraphs containing only a single `_` without errors\.
So it seems like Tree-Sitter doesn’t recognize a conflict between a string and a regex\. Another gotcha is that it doesn’t seem like you can trigger the GLR algorithm with a token returned by an external scanner, because the external scanner overrules Tree-sitter’s lexing behavior\.
## [Some tests](#Some-tests)
Using `tree-sitter parse example-file` \(with or without the `-d` or `-D` flags, try them if you haven’t\) is fine for experimental tests, but we really should add the different test cases as proper unit tests\. Tree-sitter has a built-in test harness for this purpose\.
Let’s add the very first test case to `test/corpus/syntax.txt`:
=============================================================================== Parsing goal
- This is a multiline paragraph
- :: This is a paragraph inside a div
- ::
let x = 2;
(document (paragraph (emphasis)) (div (div_marker) (paragraph) (div_marker)) (code_block (code_block_marker) (language) (code) (code_block_marker)))
And run it:
$ tree-sitter test syntax: ✓ Parsing goal
Yay\!
We should add \(a lot\) more tests here, but I won’t bother writing them out in this already too long blog post\.
## [Using tree-sitter for something useful](#Using-tree-sitter-for-something-useful)
I like a theoretical excursion as much as the next nerd, but I started looking at Tree-sitter because I wanted to *do* something with the Grammar, not just play around with it all day\. Let’s end the post by seeing some things we can use it for\.
### [Syntax highlighting](#Syntax-highlighting)
Syntax highlighting is made using queries from the `highlights.scm` file\. It’s common to have it placed in the `src` directory in the same repository as the grammar, but it’s not required\.
Here’s an example `src/highlights.scm` file that highlights the different elements of our markup:
(div_marker) @punctuation.delimiter (code_block_marker) @punctuation.delimiter (emphasis “_” @punctuation.delimiter) @markup.italic (language) @tag.attribute (code_block) @markup.raw (paragraph) @markup
What colors to choose is a bit arbitrary, these works well enough I suppose\.
See the [documentation](https://tree-sitter.github.io/tree-sitter/syntax-highlighting) for more details on how the queries and highlighting works\.
### [Language injection](#Language-injection)
One big question I had when starting writing my grammar was how to mix multiple parsers in the same document, to for example highlight code blocks using the specified language:
let x = 2;
Turns out, this is quite straightforward\.
With the initial grammar, the code block parses into:
(code_block (code_block_marker) (language) (code) (code_block_marker)))
Which we’ll use in `src/injections.scm` to specify that we want to parse `(code)` using the grammar specified in `(language)`:
(code_block (language) @injection.language (code) @injection.content)
When we’ll embed the grammar into a program with highlighting support, it will delegate the text inside the code block to the injected language\.
### [Using our grammar with Neovim](#Using-our-grammar-with-Neovim)
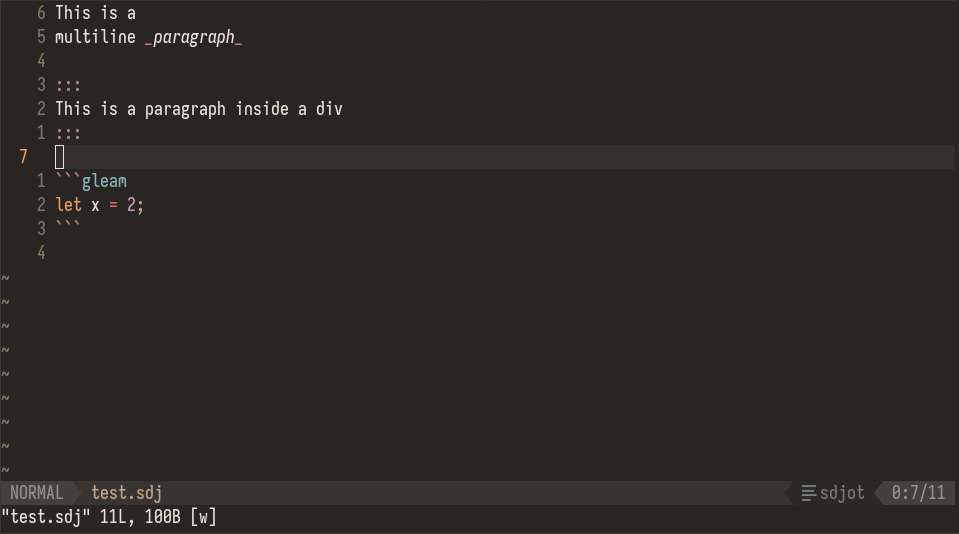
I typically install Tree-sitter grammars in Neovim using `:TSInstall` provided by [nvim-treesitter](https://github.com/nvim-treesitter/nvim-treesitter)\. But you can [install local Tree-sitter grammars](https://github.com/nvim-treesitter/nvim-treesitter#adding-parsers) as well:
local parser_config = require(“nvim-treesitter.parsers”).get_parser_configs() parser_config.sdjot = { install_info = { – Change this url to your grammar url = “~/code/tree-sitter-sdjot”, – If you use an external scanner it needs to be included here files = { “src/parser.c”, “src/scanner.c” }, generate_reqires_npm = false, requires_generate_from_grammar = false, }, – The filetype you want it registered as filetype = “sdjot”, }
Just make sure you have a `"tree-sitter"` section in the grammar’s `package.json`:
“tree-sitter”: [ { “scope”: “source.sdjot”, “file-types”: [ “sdj” ], “injection-regex”: “sdjot”, “highlights”: [ “queries/highlights.scm” ] } ],
With this you can do `:TSInstall sjdot` and `:TSUpdate sdjot` when you make changes\.
`:TSInstall` doesn’t install queries automatically though\. What I did was symlink the queries directory into Neovims config directory:
ln -s ~/code/tree-sitter-sdjot/queries ~/.config/nvim/queries/sdjot
`:TSPlaygroundToggle` is very useful for debugging the grammar, and `:Inspect` shows you the highlight groups under your cursor\. It might be good to check out `:help treesitter-highlight-groups` if you want to play with your theme, as the theme needs to support the highlight groups we use for coloring to appear\.
You also need to have the Tree-sitter grammar for the injected language installed, if you want to highlight the contents of code blocks\.
### [Jumping and selecting with textobjects](#Jumping-and-selecting-with-textobjects)
I mentioned [nvim-treesitter-textobjects](https://github.com/nvim-treesitter/nvim-treesitter-textobjects) as a good example of why Tree-sitter is about more than syntax highlighting\.
To make use of our grammar we can add some capture groups to `src/textobjects.scm`\. For example we can register our code blocks as “functions”:
(code_block (code) @function.inner) @function.outer
The objects are arbitrary, but `@function` is one of the standard objects so I guess it might make sense\.
With the symlink ready, you need to register keymaps with [nvim-treesitter-textobjects](https://github.com/nvim-treesitter/nvim-treesitter-textobjects) and you’re good to go\. I have it setup so I can jump between `@function.outer` with `[f` and `]f`, and selections with `af` and `if`\.
This means that with the above textobject definition I can for example jump to the next code block with `]f` and then remove all the code inside with `cif` to end up in insert mode, ready to replace it with some new code\.
Although this example is a bit arbitrary, this general functionality is ***extremely*** useful for programming languages\. For a markup language like [Djot](https://djot.net/), jumping between headings might be a more relevant use-case\.
### [Embedding the grammar with Rust](#Embedding-the-grammar-with-Rust)
One of the selling points of Tree-sitter is that you should be able to embed it in any application\. Such as this blog\!
I’ve been wanting to add Tree-sitter powered highlighting to my blog for a while, and now I have an excuse to do just that\.
This blog is a static site generator written in Rust, and [tree-sitter-highlight](https://docs.rs/tree-sitter-highlight/latest/tree_sitter_highlight/) looks like a suitable library to try\. Let’s add it to our `Cargo.toml`:
[dependencies] tree-sitter-highlight = “^0.20.0” tree-sitter-sdjot = { git = “https://github.com/treeman/tree-sitter-sdjot.git” }
I use a slightly older version because some other grammars I want depend on the older version, and it’s a big pain but they all need to use a matching version\. Bleh\.
[According to the docs](https://docs.rs/tree-sitter-highlight/latest/tree_sitter_highlight/) we first need to setup a `HighlightConfiguration`\. I used `lazy_static!` to create a global map with configurations to be used by any parallel rendering on the blog\. It’s not the most beautiful code I’ve written, but it gets the job done:
// All highlights needs to be listed explicitly. static HIGHLIGHT_NAMES: &[&str] = &[ // I have +100 entries here, this is for sdjot. “markup”, “markup.italic”, “markup.raw”, “punctuation.delimiter”, “tag.attribute”, ]; lazy_static! { static ref CONFIGS: HashMap<String, HighlightConfiguration> = init_configurations(); } fn init_configurations() -> HashMap<String, HighlightConfiguration> { [ // I have more languages here ( “sdjot”, HighlightConfiguration::new( tree_sitter_sdjot::language(), tree_sitter_sdjot::HIGHLIGHTS_QUERY, tree_sitter_sdjot::INJECTIONS_QUERY, “”, ) .unwrap(), ), ] .into_iter() .map(|(name, mut config)| { config.configure(&HIGHLIGHT_NAMES); (name.to_string(), config) }) .collect() }
Notice how all highlight names we’re interested in have to be explicitly specified\. This is a big pain, especially if you’re going to include many larger grammars\.
The names can be filtered for with [ripgrep](https://github.com/BurntSushi/ripgrep) with something like this:
rg “@[\w.]+” -INo –trim highlights.scm | sort | uniq
I already have syntax highlighting via [syntect](https://github.com/trishume/syntect), so I wrap the highlighters in their own types:
enum HighlighterType<’a> {
Syntect(SyntectHighlighter<’a>),
Treesitter(TreesitterHighlighter<’a>),
}
pub struct TreesitterHighlighter<’a> {
config: &’a HighlightConfiguration,
}
impl<’a> TreesitterHighlighter<’a> {
pub fn find(lang_id: &str) -> Option
The interesting part is of course the `highlight` method, that takes a string of code and applies syntax highlighting on it:
impl<’a> TreesitterHighlighter<’a> {
pub fn highlight(&self, code: &str) -> ResultHighlightConfiguration.
let res = CONFIGS.get(lang);
if !res.is_some() {
warn!(“Couldn’t find treesitter grammar for {lang} to inject”);
}
res
})?;
let mut renderer = HtmlRenderer::new();
renderer.render(highlights, code.as_bytes(), &|attr| {
// This should return a &'a [u8] with the same lifetime as code.
})?;
let res = renderer.lines().join(“”);
Ok(res)
}
}
I want to point out the API in `HtmlRenderer`, where we stumble upon a very annoying problem: what should we return from the callback, and how should we do that?
What the callback does is inject the return value into the `span` element, like this:
highlight
So we’d like to return something like `"class=\"markup italic\""`, using `attr` which is only a `usize` into `HIGHLIGHT_NAMES`:
renderer.render(highlights, code.as_bytes(), &|attr| { format!(r#“class=”{}“”#, HIGHLIGHT_NAMES[attr.0].replace(“.”, “ “)).as_bytes() })?;
Because we return a slice of bytes into a string that’s created inside the callback, of course the Rust compiler will be mad at us:
error[E0515]: cannot return value referencing temporary value –> src/markup/syntax_highlight/treesitter_highlighter.rs:33:13 | 33 | format!(r#“class=”{}“”#, HIGHLIGHT_NAMES[attr.0].replace(“.”, “ “)).as_bytes() | —————————————————————––^^^^^^^^^^^ | | | returns a value referencing data owned by the current function | temporary value created here
How to dynamically create a string from inside the callback… That outlives the callback itself?
Not easily I tell you\.
It would be so much easier if the callback would return a `Cow<str>` or something\. I wonder how the designers of the API expects it to be used? This surely isn’t a very unique requirement, to wrap the attribute in a `class`?
Oh well\. One way to solve this is to store the generated strings in a container that outlives the callback, and reference that \(yeah it’s a `Fn` callback, but there are hacky ways around that\)\. Or you could, you know, write your own `HtmlRenderer`\.
Or you could pre-generate the classes and reference them:
lazy_static! {
static ref CLASSES: Vec
renderer.render(highlights, code.as_bytes(), &|attr| { CLASSES[attr.0].as_bytes() })?;
This should be the fastest option and is the one I currently use… But speed isn’t a bottleneck here and I’d rather just return a `String` with `format!` and be done with it\.
---
With this I’ve integrated Tree-sitter based syntax highlighting into my blog\!
With great powers comes great responsibility
I could start moving the various languages over from Syntect to Tree-sitter… But I won’t\.
There are some issues:
1.
You need a compatible version of `tree-sitter` for all grammars\.
The more grammars you add the more painful the upgrade path becomes\.
1.
Syntect gives better highlighting for some languages \(like Rust and C\)\.
Neovim has their own highlighter implementation and has made tweaks to certain grammars and gets much nicer highlighting than I got out of the box\.
Integrating that code into my site generator is probably possible, but not a rabbit hole I want to jump into right now\.
1.
The highlighter library feels a bit immature\.
A newer version broke the highlight groups I got from some grammars and I don’t see any support for how to add a language specific class to `span` for injected languages\.
Because of these issues I’ll evaluate what highlighter to use on a case-by-case basis, with Syntect as the default choice\.
## [Within edge-cases lies complexity](#Within-edge-cases-lies-complexity)
If you’ve read the post to the end, congratulations\. You made it\!
I don’t claim to be an expert at grammars or Tree-sitter, and I’m sure there are plenty of things that can be improved with the way the grammar is made\. But I hope it can be helpful as a starting point if you’re curious on how to write a Tree-sitter grammar of your own\.
See the [tree-sitter-djot repo](https://github.com/treeman/tree-sitter-djot) for how I developed the grammar further to support the full [Djot specification](https://htmlpreview.github.io/?https://github.com/jgm/djot/blob/master/doc/syntax.html) \(but remember, I’m not an expert\)\.
Just one word of advice before you go\. Writing a grammar for simple rules is pretty easy, but in the real world things can get messy quickly\. This is especially true if you need to juggle multiple conflicting rules in the external scanner—keeping a sane structure is challenging\.
\(Even in our simple grammar there are bugs, but I don’t care to fix them\.\)
> The night is dark and full of terrors