Published on November 3, 2025 5:32 PM GMT
In the previous article in this series, I described how AI could contribute to the development of cheap weapons of mass destruction, the proliferation of which would be strategically destabilizing. This article will take a look at how the cost to build the AI systems themselves might fall.
Key Points
- Even though the costs to build frontier models is increasing, the cost to reach a fixed level of capability is falling. While making GPT-4 was initially expensive, the cost to build a GPT-4 equivalent keeps tumbling down.
- This is likely to be as true of weapons-capable AI systems as any other.
- A decline in the price of build…
Published on November 3, 2025 5:32 PM GMT
In the previous article in this series, I described how AI could contribute to the development of cheap weapons of mass destruction, the proliferation of which would be strategically destabilizing. This article will take a look at how the cost to build the AI systems themselves might fall.
Key Points
- Even though the costs to build frontier models is increasing, the cost to reach a fixed level of capability is falling. While making GPT-4 was initially expensive, the cost to build a GPT-4 equivalent keeps tumbling down.
- This is likely to be as true of weapons-capable AI systems as any other.
- A decline in the price of building an AI model is not the only way that the cost to acquire one might decrease. If it’s possible to buy or steal frontier models, the high costs of development can be circumvented.
- Because of these factors, powerful AI systems (and their associated weapons capabilities) will eventually become widely accessible without preemptive measures.
- Fortunately, the high cost to develop frontier models means that the strongest capabilities will be temporarily monopolized at their inception, giving us a window to evaluate and limit the distribution of models when needed.
Lessons From Cryptography
Although the offensive capabilities of future AI systems usually invite comparisons to nuclear weapons (for their offense-dominance, the analogy of compute to enriched uranium, or their strategic importance) I often find that a better point of comparison is to cryptography—another software based technology with huge strategic value.
While cryptography might feel benign today, a great part of its historical heritage is as an instrument of war: a way for Caesar to pass secret messages to his generals, or for the Spartans to disguise field campaigns. The origins of modern cryptography were similarly militaristic: Nazi commanders using cipher devices to hide their communications in plain sight while Allied codebreakers raced to decrypt Enigma and put an end to the war.
Even in the decades following the collapse of the Axis powers, the impression of cryptography as a military-first technology remained. Little research on cryptographic algorithms happened publicly. What did took place under the purview of the NSA, a new organization which had been created with the express purpose of protecting the U.S’s intelligence interests during the Cold War. The only people that got to read America’s defense plans were going to be the DoD and God, and only if He could be bothered to factor the product of arbitrarily large primes.
It wasn’t until the late 70s that the government’s hold over the discipline began to crack, as institutional researchers developed new techniques like public key exchange and RSA encryption. The governments of the U.S and Britain were not pleased. The very same algorithms that they had secretly developed just a few years prior had been rediscovered by a handful of stubborn researchers out of MIT—and it was all the worse that those researchers were committed to publishing their ideas for anyone to use. So began two decades’ worth of increasingly inventive lawfare between the U.S and independent cryptography researchers, whose commitment to open-sourcing their ideas continually frustrated the government’s attempts to monopolize the technology.
A quick look at any piece of modern software will tell you who won that fight. Cryptography underlies almost every legal application you can imagine, and just as many illegal ones—the modern internet, financial system, and drug market would be unrecognizable without it. The more compelling question is why the government lost. After all, they’d been able to maintain a near-monopoly on encryption for over thirty years prior to the late 70s. What made controlling the use and development of cryptographic technology so much more challenging in the 80s and 90s that the government was forced to give up on the prospect?
The simple answer is that it got much cheaper to do cryptographic research and run personal encryption. Before the 1970s, cryptography required either specialized hardware (the US Navy paid $50,000 per Bombe in 1943, or about $1 million today) or general-purpose mainframes costing millions of dollars, barriers which allowed the government to enforce a monopoly over distribution. As one of the few institutional actors capable of creating, testing, and running encryption techniques, organizations like the NSA could control the level of information security major companies and individuals had access to. As the personal computer revolution took off, however, so too did the ability of smaller research teams to develop new algorithms and of individuals to test them personally.

Despite the algorithm behind RSA being open sourced in the late 70s, for instance, it wasn’t until the early 90s that consumers had access to enough personal computing power to actually run the algorithm—a fact which almost bankrupted the company developing it commercially, RSA Security. But as the power of computer hardware kept doubling, it became cheap, and then trivial, for computers to quickly perform the necessary calculations. As new algorithms like PGP and AES were created to take advantage of this windfall of processing power, and as the internet allowed algorithmic secrets to easily evade military export controls, the government’s ability to enforce non-proliferation crumbled completely by the turn of the millenium.
This is remembered as a victory for proponents of freedom and personal privacy. And it was, but only because cryptography proved to be a broadly defense-dominant technology: one that secured institutions and citizens from attack rather than enabling new forms of aggression. The government monopoly over the technology was unjustified because it was withholding protection for the sake of increasing its own influence.
Had cryptography been an offense-dominant technology, however, this would be a story of an incredible national security failure instead of a libertarian triumph. Imagine an alternative world where as personal computing power kept growing, the ability to break encryption began to outpace efforts to make it stronger. The financial system, government secrets, and personal privacy would be under constant threat of attack, with cryptographic protections becoming more and more vulnerable every year. In this world, the government would be entirely justified in trying to control the distribution of the algorithmic secrets behind cryptanalysis, and would have been tragically, not heroically, undermined by researchers recklessly open sourcing their insights and the growth in personal computing power.
This is an essay about AI, not cryptography. But the technologies are remarkably similar. Like cryptography, AI systems are software based technologies with huge strategic implications. Like cryptography, AI systems are expensive to design but trivial to copy. Like cryptography, AI capabilities that were once gated by price become more accessible as computing power got cheaper. And like cryptography, the combination of AI’s commercial value, ideological proponents of open-sourcing, and the borderless nature of the internet makes export controls and government monopolies difficult to maintain over time. The only difference is one of outcome: cryptography, a technology used to enhance our collective security and privacy, and AI, a dual-use tool that has as many applications for the design of weapons of mass destruction as it does for medical, economic, and scientific progress.
Just as the Japanese population collapse provided the world with an early warning of the developed demographic crisis decades before it happened, the proliferation of cryptography gives us a glimpse into the future challenges of trying to control the spread of offensive AI technology. Whether AI follows the same path depends on whether its cost of development will continue to fall, and whether we have the foresight to preempt the proliferation of the most dangerous dual-use models before it becomes irreversible.
The previous article in this series described how AI systems could become strategically relevant by enabling the production of cheap yet powerful weapons. An AI model capable of expertly assisting with gain of function research, for example, could make it much easier for non-state actors to develop lethal bioweapons, while a general artificial superintelligence (ASI) could provide the state that controls it with a scalable army of digital workers and unmatched strategic dominance over its non ASI competitors.
One hope for controlling the distribution of these offensive capabilities is that the AI systems that enable them will remain extremely expensive to produce. Just as the high cost of nuclear enrichment has allowed a handful of nuclear states to (mostly) monopolize production, the high cost of AI development could be used to restrict proliferation through means like export controls on compute.
Unfortunately, the cost to acquire a powerful AI system will probably not remain high. In practice, algorithmic improvements and the ease of transferring software will put pressure on enforcement controls, expanding the range of actors that become capable of building or acquiring AI models.
Specifically, there are two major problems:
- First, the cost to build an AI system is falling. Once a frontier benchmark it met, it gets cheaper and cheaper for each successive generation to reach that same level of performance. As a result, formerly expensive offensive capabilities will quickly become cheaper to acquire.
- Second, the cost to take an AI system is extraordinarily low compared to other weapons technologies. AI models are ultimately just software files, which makes them uniquely vulnerable to theft.
Because of these dynamics, proliferation of strategically relevant AI systems is the default outcome. The goal of this article is to look at how these costs are falling, in order to lay the groundwork for future work on the strategic implications of distributed AI systems and policy solutions to avoid proliferation of offensive capabilities.
Cost of Fixed Capabilities
The first concern, and the most detrimental for long-term global stability, is that the cost to build a powerful AI system will collapse in price. As these systems become widely available for any actor with the modest compute budget required to train them, their associated weapons capabilities will follow, leading to an explosion of weapons proliferation. These offensive capabilities would diffuse strategic power into the hands of rogue governments and non-state actors, empowering them to, at best, raise the stakes of mutually assured destruction, and at worst, end the world through the intentional or accidental release of powerful superweapons like mirror life or misaligned artificial superintelligences.
Empirically, we can already see a similar price dynamic in the performance and development of contemporary AI models.[1] While it’s becoming increasingly expensive to build new frontier models (as a consequence of scaling hardware for training runs), the cost to train an AI capable of a given, or “fixed” level of capability is steadily decreasing.

The primary driver of this effect is improvements to algorithmic efficiency, which reduce the amount of computation (or compute) that AI models need during training. This has two distinct but complementary effects on AI development.
- First, all of your existing compute becomes more valuable. Because your training process is now more compute efficient, any leftover compute can be reinvested into increasing the size or the duration of the model’s training run, which naturally pushes up performance.[2] Despite having the same number of GPUs to start with, you have more “effective” compute relative to the previous training runs, which lets you acquire new capabilities that were previously bounded by scale.
The transition from LSTMs to transformer architectures, for instance, made it massively more efficient to train large models. LSTMs process text sequentially, moving through sentences one word at a time, with each step depending on the previous one.You might own thousands of powerful processors, but the sequential nature of the architecture meant that most of them wait around underutilized while the algorithm processes each word in order.[3]
Transformers changed this by introducing attention mechanisms that could process all positions in a sequence simultaneously. Instead of reading “The cat sat on the mat” one word at a time, transformers could analyze relationships between all six words in parallel.[4] This meant that research labs with fixed GPU budgets could suddenly train much larger and more capable models than before, simply because they were no longer bottlenecked by sequential processing. Even at their unoptimized introduction in 2017, transformers were so much more efficient that likely increased effective compute by more than sevenfold compared to the previous best architectures.
- Second, it becomes cheaper for anyone to train a model to a previously available, or fixed, level of performance. Since the price floor for performance is lower, capabilities that were previously only accessible with large compute investments become widely distributed.
- At the time GPT-4o was released (May 2024), the prevailing sentiment of American policymakers and tech writers was that the U.S was comfortably ahead of AI competition with China, given the U.S’s massive lead in compute and export controls on high-end chips. By December, however, Chinese competitor Deepseek had leapt to match the performance of OpenAIs newest reasoning models with an infamously small training run of $5.6 million.
The upshot of this dynamic for weapons proliferation is that dangerous capabilities will initially be concentrated among actors with the largest compute budgets. From there, however, formerly frontier capabilities will quickly collapse in price, allowing rogue actors to cheaply access them.
One of the most salient capability concerns for future AI systems is their ability to contribute to the development of biological weapons. As I pointed out in a previous piece, rogue actors who sought to acquire biological weapons in the past have often been frustrated not by a lack of resources, but by a lack of understanding of the weapons they were working with. Aum Shinrikyo may have invested millions of dollars into mass production of anthrax, but were foiled by simply failing to realize that anthrax cultivated from a vaccine strain would be harmless to humans.[5]
The production of future bioweapons, especially a virulent pandemic, is likewise constrained by the limited supply of expert advice. Virologists already know how to make bioweapons: which organisms are best to weaponize, which abilities would be most dangerous, how to engineer new abilities, optimal strategies for dispersal, or which regulatory gaps could be exploited. But because so few of these experts have the motive to contribute to their development, non-state actors are forced to stumble over otherwise obvious technical barriers.
To help model the cost dynamics we described earlier, a good place to start would be with an AI that can substitute for this intellectual labor. How much might it cost to train an AI capable of giving expert level scientific advice, and how long would it take before it starts to become widely accessible for non-frontier actors to do the same?
While I provide a much more detailed account of how these costs can be calculated below, the basic principle is that expanding the amount of compute used to train a model can (inefficiently) increase the model’s final performance. By using scaling laws to predict how much compute is required for a given level of performance, you can set a soft ceiling on the amount of investment it would require for a given capability. Barnett and Besiroglu (2023), for example, estimate that you could train an AI that would be capable of matching human scientific reasoning with 10^35 FLOPs of compute, or the equivalent of training a version of ChatGPT-4 at roughly ten billion times the size.[6] The result of this training process would be an AI that can provide professional human advice across all scientific disciplines, a subset of which are the skills relevant to the development of biological weapons.
Concretely, we can imagine these skills being tailored to the cultivation of an infectious disease like avian influenza (bird flu). For example, the AI’s advice might include circumventing screening for suspicious orders by self-synthesizing the disease. Just as polio was recreated using only its publicly available genome in the early 2000s, influenza could be acquired without ever needing an original sample. From there, the virus could be bootstrapped with gain of function techniques, making it dramatically more infectious and lethal.[7] With some basic strategy in spreading the resulting disease over a wide geographic area, it would be possible to trigger an uncontrollable pandemic. Depending on the level of lethality and rate of spread (both of which could be engineered to be optimally high), normal response systems like quarantines and vaccine production could be completely overwhelmed.[8]
At ten billion times the size of GPT-4, such an AI would be prohibitively expensive to train today. But with even conservative increases in algorithmic efficiency and AI hardware improvements, the cost of getting enough effective compute will rapidly decline. When compared to the growing financial resources of the major AI companies, a frontier lab could afford the single-run budget to train our AI scientist by the early 2030s.[9] By the end of the next decade, the cost to train a comparable system will likely collapse into the single digit millions.

Calculation Context
This graph was built using the median approaches and assumptions outlined in The Direct Approach. All I did was normalize the results to the price of a fixed amount of effective compute, in order to better illustrate how accessible the tech might become. The longer explanation below is just to give more context to some of the important assumptions, as well as to highlight some of the ways in which those assumptions might be conservative. Details on the specific formulas used can be found in the appendix here.
To begin with: how do you measure how much compute it would take to train an AI to give reliable scientific advice when no one’s done it before?
One way is to measure distinguishability: if your AI produces outputs that aren’t discernably different from those of an expert human, then for all intents and purposes, it’s just as good at completing the relevant tasks (even if the internal reasoning is very different).
For example, you might compare a scientific paper written by a human biologist with one written by an AI. The worse the AI is at biology than its human counterpart, the easier it would be for an external verifier to tell which paper it’s responsible for: maybe its writing is unprofessional, it makes factual errors, or its data gets presented deceptively. Conversely, the closer the AI is in performance, the harder it gets to tell them apart—the verifier needs to examine the papers more and more deeply for evidence to distinguish them. Once the outputs are equal, no amount of evidence can tell them apart, so you can conclude that the skills of both are equal.
In other words, the verifier needing lots of evidence -> higher likelihood of equal skill.

Currently, AIs like ChatGPT 5 cannot reliably pass this test. However, there are still two potential paths to making them smart enough to do so in the future.
- The first path would be for an AI architecture that learns more efficiently than transformers. One major difference between “training” the performance of a human compared to an AI is that people are vastly more sample efficient. While it might take reading hundreds of articles for a human to begin writing ones of comparable quality, it might take the AI millions of examples before it even produces something legible. This inefficiency is very taxing on the AI’s training budget, because it requires you to find orders of magnitude more data and parameters to sort through all of that extra information. If we had an algorithm that better mimicked the human learning process, we could train the AI in the same hundred or so examples it takes a normal researcher and save on all that compute. But this is hard! It’s much easier (intellectually) to make small optimizations to existing architectures and training setups than it is to find entirely new architectures that are fundamentally more efficient.
- The alternative is simple but expensive. We know from model scaling laws that you can logarithmically improve performance by putting in more compute with each iteration. Although each new order of magnitude of compute is subject to diminishing returns, it’s possible to scale the underlying transformer algorithm to the point that it can predict tokens at a very high level of precision over large contexts. These relationships are described in scaling laws like the ones below, where N and D are reflections of the amount of compute you add.
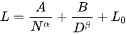
Because this second method is so straightforward, it lets us approximate how much “evidence” the judge needs to decide between the human and the AI. You can calculate a “loss” (L in the equation above) for a given amount of compute, and measuring how close it is to the theoretical irreducible loss of the true distribution. By finding a model size where the amount of evidence you need to be confid