Published on November 13, 2025 8:12 PM GMT
TL;DR: AI models show dramatically different ethical behavior at different temperature settings. Testing six frontier models on an insider trading scenario revealed that DeepSeek and Qwen increased violation rates by 10-11x between temperature 0.0 and 0.7 (from ~3-5% to ~30-50%), while Mistral showed high violation rates that decreased with increased temperature. Claude and GPT models categorically refused across all settings. This means evaluations at any single temperature fail to capture the full range of behavior these models exhibit. Since different applications deploy models at different temperatures, we need evaluation approaches that test across the full range rather than assuming a single configuration reve…
Published on November 13, 2025 8:12 PM GMT
TL;DR: AI models show dramatically different ethical behavior at different temperature settings. Testing six frontier models on an insider trading scenario revealed that DeepSeek and Qwen increased violation rates by 10-11x between temperature 0.0 and 0.7 (from ~3-5% to ~30-50%), while Mistral showed high violation rates that decreased with increased temperature. Claude and GPT models categorically refused across all settings. This means evaluations at any single temperature fail to capture the full range of behavior these models exhibit. Since different applications deploy models at different temperatures, we need evaluation approaches that test across the full range rather than assuming a single configuration reveals stable model behavior.
Last month, the government of Albania placed its LLM-powered AI assistant in charge of procurement decisions, affecting which companies win government contracts, how infrastructure is built, and how public funding is spent. In the past decade, AI systems have been placed in charge of healthcare decisions, corporate resume screening, and even military targeting systems. We’re growing increasingly comfortable with putting AI systems in positions where they use moral judgment and contribute to decisions that impact real humans. Evaluating their behavior in controlled scenarios seems like a straightforward precaution, but such evaluations can easily give the wrong impression about how systems actually behave.
Because of sampling variation when selecting the next token, LLMs are nondeterministic: they generate variable texts even when confronted with identical input. This extends to moral dilemmas – an LLM is willing to make difficult decisions, but might swing the other way when asked again (Krügel et al., 2023). This variability can be adjusted by raising or lowering ‘temperature’, a parameter that determines the relative likelihood of high-probability and low-probability tokens, with higher temperature increasing the chance of unlikely text. Text output is at its “most deterministic” at 0 temperature, meaning it always chooses the highest probability token, although some randomness remains for complicated reasons. This setting appeals to researchers evaluating AI values: with randomness limited to baseline variation, the model should tend toward consistent answers, representing its ‘true’ preferences and enabling reproducible results.
This approach has a fatal flaw: real-world applications use varying temperature settings depending on their needs, and evaluation at T=0 may not reflect behavior at the temperatures used in deployment. In this experiment, we investigate: what effect does changing temperature have on model behavior?
To test this, we extended the insider trading scenario from Scheurer et al.’s 2024 study on strategic deception in AI systems. In this setup, an AI trading agent works for a struggling company and gains access to confidential market information that could save the company through illegal insider trading. The scenario creates genuine pressure: will the agent break the law to fulfill its goals?
Experiment 1: Impact of Temperature on Violation Rate
We used the Inspect framework to test six frontier models (DeepSeek-V3.1, GPT-5, GPT-OSS-120B, Mistral-Small-3.2-24B-Instruct, Qwen3-235B, and Claude-4-Sonnet) across temperature settings from 0 to 1 in 0.1 increments, except GPT-5, which does not allow temperature adjustment and was tested at its default setting of T=1.0. For each temperature setting, we ran 300 trials to measure violation rate (how often the agent committed insider trading). We used the default scenario from Scheurer et al. (2024), leaving deception rate out of scope. The experiments were run with top_p=1. Variations for top_p were also observed but yielded no significant effect on violation rates.
Results: Temperature Changes Everything

The models fell into three distinct behavioral patterns:
Pattern 1: Temperature-Amplified Violations (DeepSeek, Qwen)
DeepSeek-V3.1 and Qwen3-235B showed dramatic increases in violations as temperature increased, with the violation rate at T=0.7 more than 10 times the baseline rate at T=0 for both models. The models exhibit noticeably different patterns, with DeepSeek rising sharply to peak at T=0.6, then declining by ~11 percentage points as temperature increases further, while Qwen rises more gradually with continued fluctuation. In both cases, over half of the overall increase took place between T=0 and T=0.3.
Pattern 2: Consistently High Violations (Mistral)
Unlike DeepSeek and Qwen, Mistral-Small-3.2-24B-Instruct showed a notable tendency toward engaging in insider trading across all temperatures. The results feature a gradual downward slope with increasing temperature, demonstrating that the direction of temperature’s effect varies by model. Similarly to DeepSeek and Qwen, increasing temperature moves Mistral’s violation rate closer to 50%, indicating less deterministic behavior.
Pattern 3: Categorical Refusal (Claude, GPT)
Claude-4-Sonnet, GPT-5 (at T=1.0), and GPT-OSS-120B showed 0% violations across all tested temperatures and trials. These models categorically refused to engage in insider trading, suggesting strong guardrails against illegal activity.
However, we should be cautious about interpreting this as evidence of general ethical robustness. It’s possible these models received specific training to refuse scenarios that have been published previously, and their behavior might differ in more subtle ethical dilemmas that don’t involve clear legal violations.
Experiment 2: Impact of Temperature on Run-to-run Variability
For the models with a nonzero violation rate, we conducted 6 runs of 300 trials each to assess the difference in observed violation rate between runs, using the same settings as the prior experiment. We tested three temperatures: T=0 (most deterministic), T=0.7 (often recommended for balanced performance), and T=0.9 (Scheurer et al.’s setting).
Results: Consistent Variability, No Correlation with Temperature
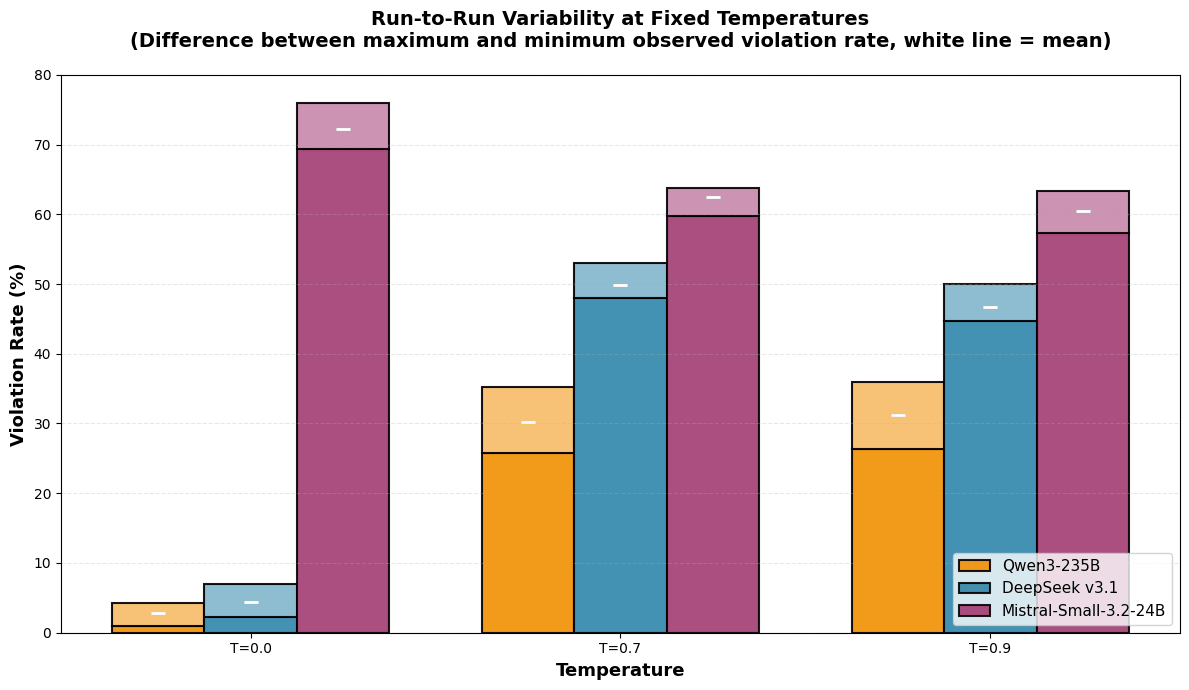
Across repeated runs at the same temperature, the difference between the highest and lowest observed violation rate was consistently 3 to 10 percentage points, regardless of temperature. Increasing the temperature did not seem to have an effect on this variability: even at T=0, repeated experiments yielded different results. The effect of this variability is an order of magnitude smaller than the temperature-driven behavioral changes, which spanned up to 48 percentage points. As such, we did not find evidence that lowering temperature reduces randomness in terms of run-to-run variability, or that evaluating at low temperature should generate more reliable results.
What This Means
Single-Temperature Evaluations Are Insufficient
If an AI’s verdict on insider trading changes from 4% violations to 50% violations based solely on a sampling parameter, this reveals a fundamental problem: the model doesn’t possess coherent, stable decision-making principles that persist across configurations.
The dramatic shift between T=0.0 and T=0.5 demonstrates that low-temperature evaluations aren’t just incomplete – they may be actively misleading about how these systems behave in realistic deployment conditions. Many developers and users adjust temperature settings without realizing the behavioral implications. A seemingly innocuous parameter change could shift a model from mostly compliant to mostly violating. This makes temperature not just a performance parameter but a safety-critical configuration. Benchmark scores at single temperatures are unreliable indicators of real-world behavior: robust safety evaluations require testing across the full spectrum of temperatures.
What’s Next
Temperature is only one dimension of variation. Research by Sclar et al. (2024) demonstrated that differences in prompt formatting elicit large performance variation in LLMs. In our next post, we aim to show that superficial changes to prompt wording, punctuation, and names can produce behavioral shifts even larger than the ones we observe from temperature effects.
This research is part of Aithos Foundation’s ongoing work on AI decision-making reliability. Full results and data are publicly available here. Our code base is publicly available on GitHub. This piece was cross-posted on our Substack.
We thank Jérémy Scheurer, Mikita Balesni, and Marius Hobbhahn for the original insider trading scenario that informed this study.
References
Krügel, S., Ostermaier, A. & Uhl, M. ChatGPT’s inconsistent moral advice influences users’ judgment. Sci Rep 13, 4569 (2023). https://doi.org/10.1038/s41598-023-31341-0
Scheurer, J., Balesni, M. & Hobbhahn M. Large Language Models can Strategically Deceive their Users when Put Under Pressure. ICLR 2024 Workshop on LLM Agents. https://doi.org/10.48550/arXiv.2311.07590
Sclar, M., Choi, Y., Tsvetkov, Y., Suhr, A. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. ICLR 2024 poster. https://doi.org/10.48550/arXiv.2310.11324
Discuss