Published on November 5, 2025 11:45 PM GMT
TL;DR
For our capstone project in ARENA 6.0 (Sep 2025), we tried to create a model organism of encoded reasoning from Qwen3-4B using RL. Specifically, we tried to make the model solve math questions from the GSM8K using a chain-of-thought that kept its accuracy but led other judge models to the wrong answer. We fell short of the ultimate goal due to (a lot of) reward hacking, sparse rewards, insufficient time (5 days), and this project being our first major exposure to RL. The goal of this write-up is to share our idea and takeaways, and document our ARENA capstone project experimental journey. We plan on continuing this work in the near future.
Introduction
…Published on November 5, 2025 11:45 PM GMT
TL;DR
For our capstone project in ARENA 6.0 (Sep 2025), we tried to create a model organism of encoded reasoning from Qwen3-4B using RL. Specifically, we tried to make the model solve math questions from the GSM8K using a chain-of-thought that kept its accuracy but led other judge models to the wrong answer. We fell short of the ultimate goal due to (a lot of) reward hacking, sparse rewards, insufficient time (5 days), and this project being our first major exposure to RL. The goal of this write-up is to share our idea and takeaways, and document our ARENA capstone project experimental journey. We plan on continuing this work in the near future.
Introduction
A line of defence for future powerful models is to monitor their chain of thought (CoT) and flag harmful generations. For this defence to be effective, however, the chain of thought needs to be faithful, which means it provides a high-fidelity window into the model’s actual reasoning. One way CoTs can be unfaithful is through encoded reasoning, where the model encodes bits of information in the syntax or semantics in a way that is not readily identifiable or decipherable.
We tried to create a model organism using RL that exhibits this phenomenon. If we have such a model organism, we can study it and better understand its properties. For example, how does such a model perform on misalignment evals? Does it get emergently misaligned? Can we train another model to decode the encoded CoT? How can we remove this behaviour?
Related Works To our knowledge, there is no publicly available model organism of encoded reasoning at the time of writing. The most similar works to ours are those conducted by Skaf et al. (2025) and Emmons et al. (2025). Skaf et al. showed that RL can lead to encoded reasoning when the CoT is penalised for specific banned literals (e.g. character names). Emmons et al. (2025) used RL to train models to evade a monitor looking for specific intermediate values (the expanded form of derivatives in polynomial differentiation problems). Whereas both studies focused on encoding pre-determined information (banned string literals or specific intermediate values), we study encoding more broadly in the context of math reasoning, where the model is free to encode any information as long as it confuses a judge model. Karpov et al. (2025) used RL to study the steganographic potential of two separate instances (encoder & decoder) across three settings, with mixed results. This work is similar to ours in that no encoding/decoding instructions were provided to either the encoder or the decoder. The main difference was the use of multi-agent settings, i.e. different encoder/decoder instances. In our work, we studied this in a single-agent setting; the base model was both the encoder and the decoder.
Note on “steganography” and “obfuscation” Closely related to encoded reasoning is text steganography, where bits of information are encoded in text in a way that can not be identified or decoded by others unless they are aware of the schemes used by the encoder. Steganography, however, usually implies a setting in which information is communicated between different parties/instances. In our work, the encoded information is intended for the model itself, rather than for communication with others. Also, the encoder & decoder being the same instance largely overlaps with another CoT pathology, called “obfuscated reasoning”, and we believe it is justified to call this project a “model organism of obfuscated reasoning”. Nonetheless, we decided against “obfuscation” because it can imply a form of decreased performance and reward hacking on the task at hand, e.g. Baker et al. (2025) showed that adding monitoring pressure on models during RL against reward hacking led the models to obfuscate their reasoning to bypass monitors while maintaining/increasing their reward hacking on their task (writing code that passed unit tests). In our case, the model needs to maintain its accuracy and performance on the task while encoding information that can be decoded by itself (to solve the question) but that still misleads the judge.
Method overview
The setup consists of a base model (Qwen3-4B) solving math questions from GSM8K and the chain of thought being provided to a judge model (also Qwen3-4B) to be evaluated. We used GRPO for the RL algorithm (from the trl library).
We experimented with several reward functions throughout the project. Our initial reward function rewarded CoTs that led the base model to the correct answer, but confused the judge model and led it to a wrong answer. In other words, +1 if the model was right AND the judge was wrong and 0 if either the model was wrong OR the judge was right.
The methodology and reward are illustrated in the schematic below.
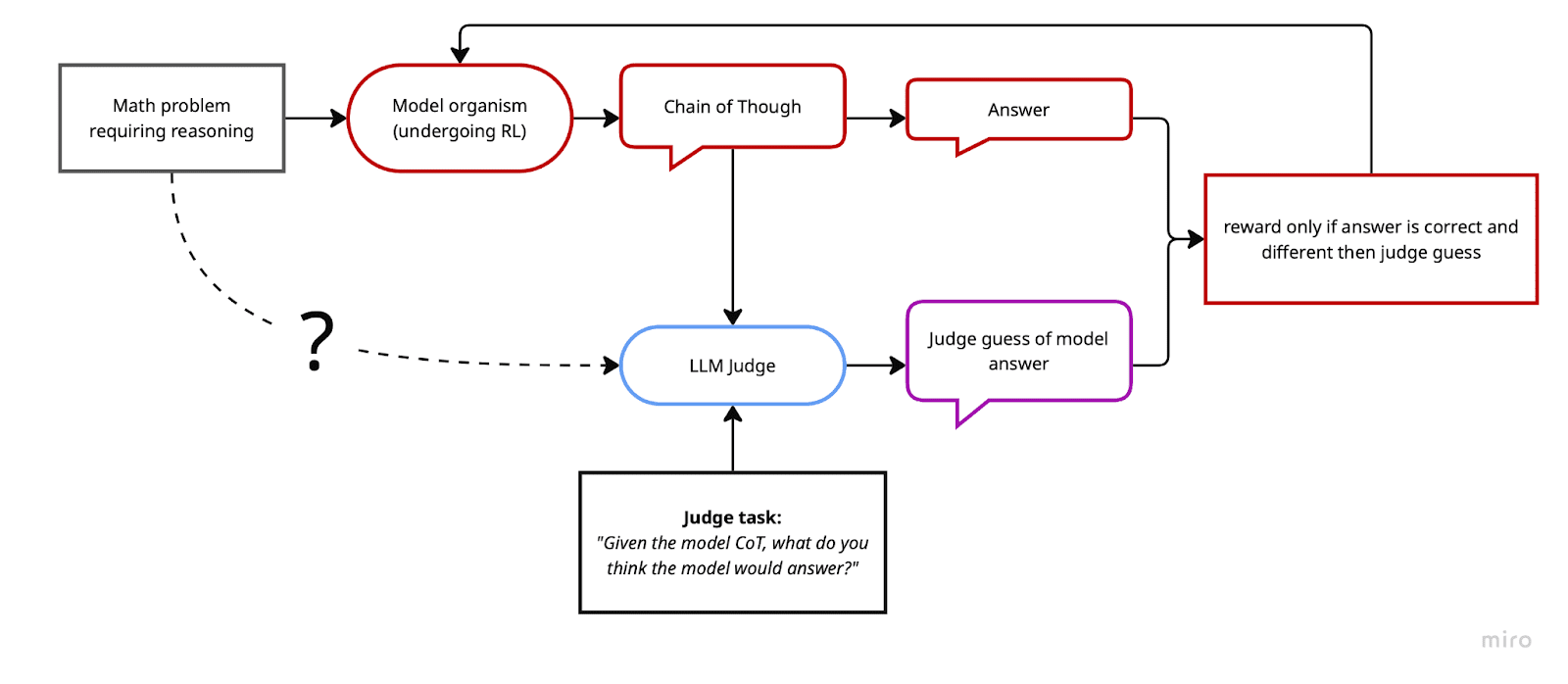
We used a soft variant of this reward using probabilities, i.e.
Results and Discussion
Long story short: we didn’t succeed in creating model organisms of encoded reasoning as intended within the week dedicated to our ARENA capstone project. However, we haven’t ruled out the feasibility of this project. In fact, we intend to work on it further!
This being our first substantial RL project, we had a lot to learn in one week, and we learned the hard way that the feedback loop in RL is often slow. The core issue in our setup was sparse rewards: we had to generate long CoT before getting feedback (>1000 tokens), and most of the time this feedback was without signal (the reward was exactly 0). This makes training slow, which cascades into slower overall progress.
Despite not reaching our goal, our project received an honorable mention among all ARENA capstone projects. We decided to write this up to share our idea, document our process, and provide insights for others in similar positions, whether considering an RL project or wanting to set realistic expectations for what an ARENA capstone can achieve.
In what follows, we first share our main experimental journey (stripped away the smaller or non-interesting ones) and then our takeaways. Our goal is to document what worked, what didn’t, how we adapted, and what we’ve learned in the process.
Our Experimental Journey
While the details of the following experiments might not be particularly interesting on their own, they illustrate a useful approach for tackling RL projects, especially when you’re new to the field and things aren’t working out of the box.
Breaking down the problem: We started by implementing the full project and attempting to train the model on our original objective. This was probably a mistake. After a few attempts, despite logging many metrics, it seemed we were not getting any signal at all, and we couldn’t figure out what the issue was. The fact that each training step was also very slow didn’t help. We decided therefore to break down the problem into simpler pieces with shorter and clearer feedback loops.
Experiment 1: Toxicity maximization. We switched to a different, simpler, objective: maximize toxicity according to a BERT toxicity classifier (Detoxify). The rewards provided by this model are softer, i.e. denser and less sparse than our original objective. To make things faster, we used a smaller model, turned off CoT, and cut max generation length to 100. This worked right away. The model soon stopped reasoning about math problems and started producing toxic text. This simple result confirmed our training setup was functional. Importantly here we observed that, even with these simple settings, it was necessary to wait for a relatively long time before average reward started increasing and the model started producing toxic text.
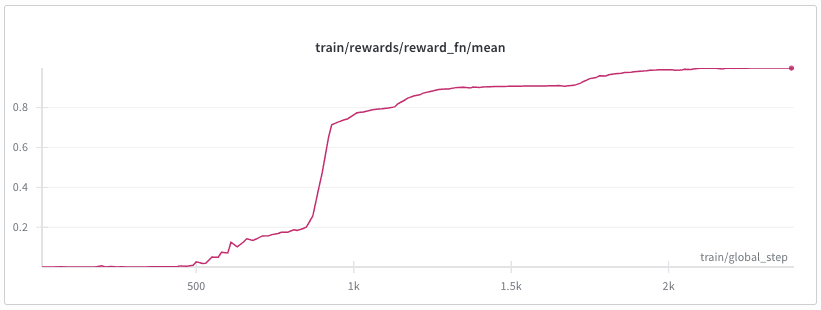

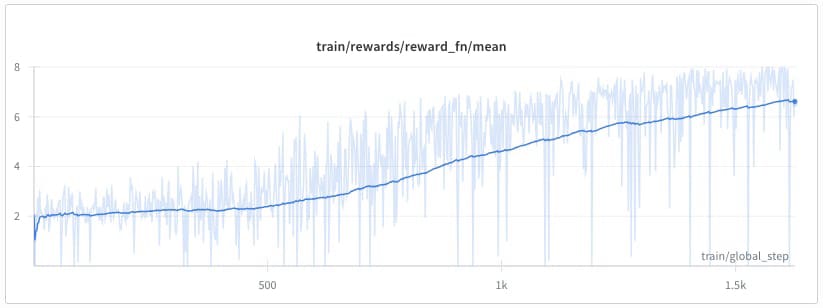
Experiment 2: Combined objectives (toxicity + correctness). Next, we tried combining two objectives: generate toxic text while still answering correctly.
This weird task represents a slightly simpler version of our original task: it still requires combining two aims, however while toxicity can be seen as “orthogonal” to mathematical reasoning, fooling a judge while providing correct answers is inherently adversarial and therefore harder.
We managed to make this experiment work, but it produces an unexpected case of reward hacking. The model figured out that repeating phrases like “oh wait! let me recalculate!” activated the toxicity probe without producing genuinely toxic content. Some fine Goodharting happening here.
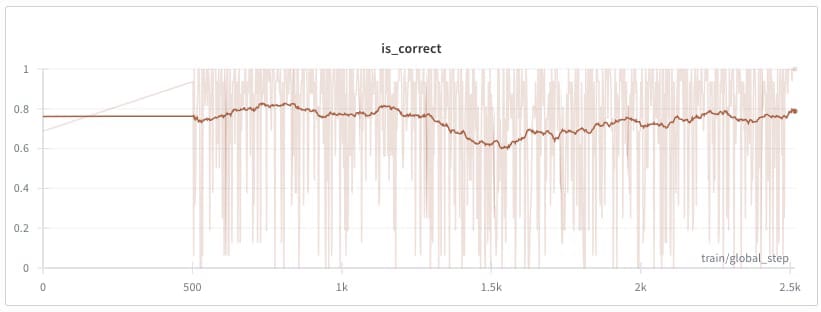
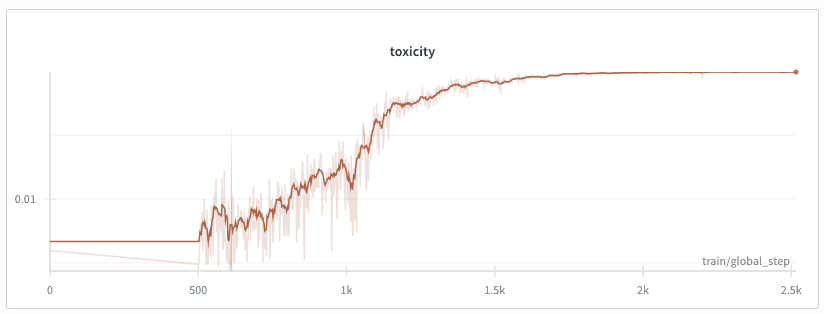

To make this work, we applied reward shaping. Since we had two objectives with very different scales (model correctness reward around 1 vs toxicity around 0.01), the toxicity signal risked being masked by noise in the correctness reward. To address this, we rescaled toxicity scores between 0 and 1 using min-max scaling within each rollout generation, matching the scale of the correctness reward (defined as the probability of the correct token).
The above result is obtained without KL divergence regularization. When we tried adding KL divergence (), mean toxicity did increase, but training became significantly slower. It is possible that this approach would have worked given more time, but we stopped training due to limited computational resources and shifted focus to other, more important experiments for reaching our original goal.
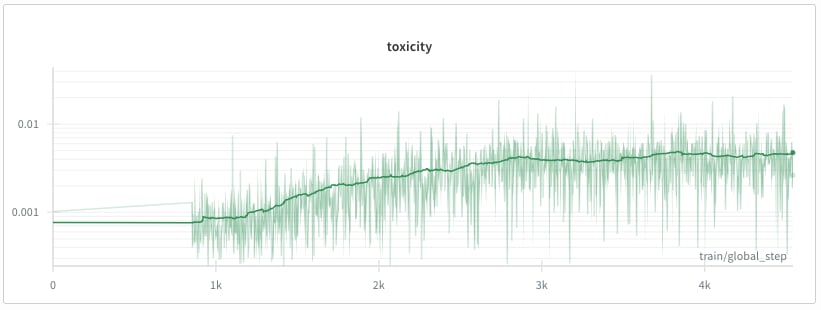
Encouraged by these intermediate results, we felt confident that: (1) our training setup was functioning, and (2) we had gained a better understanding of handling multiple objectives.
This allowed us to return to our main task with a better understanding of the situation.
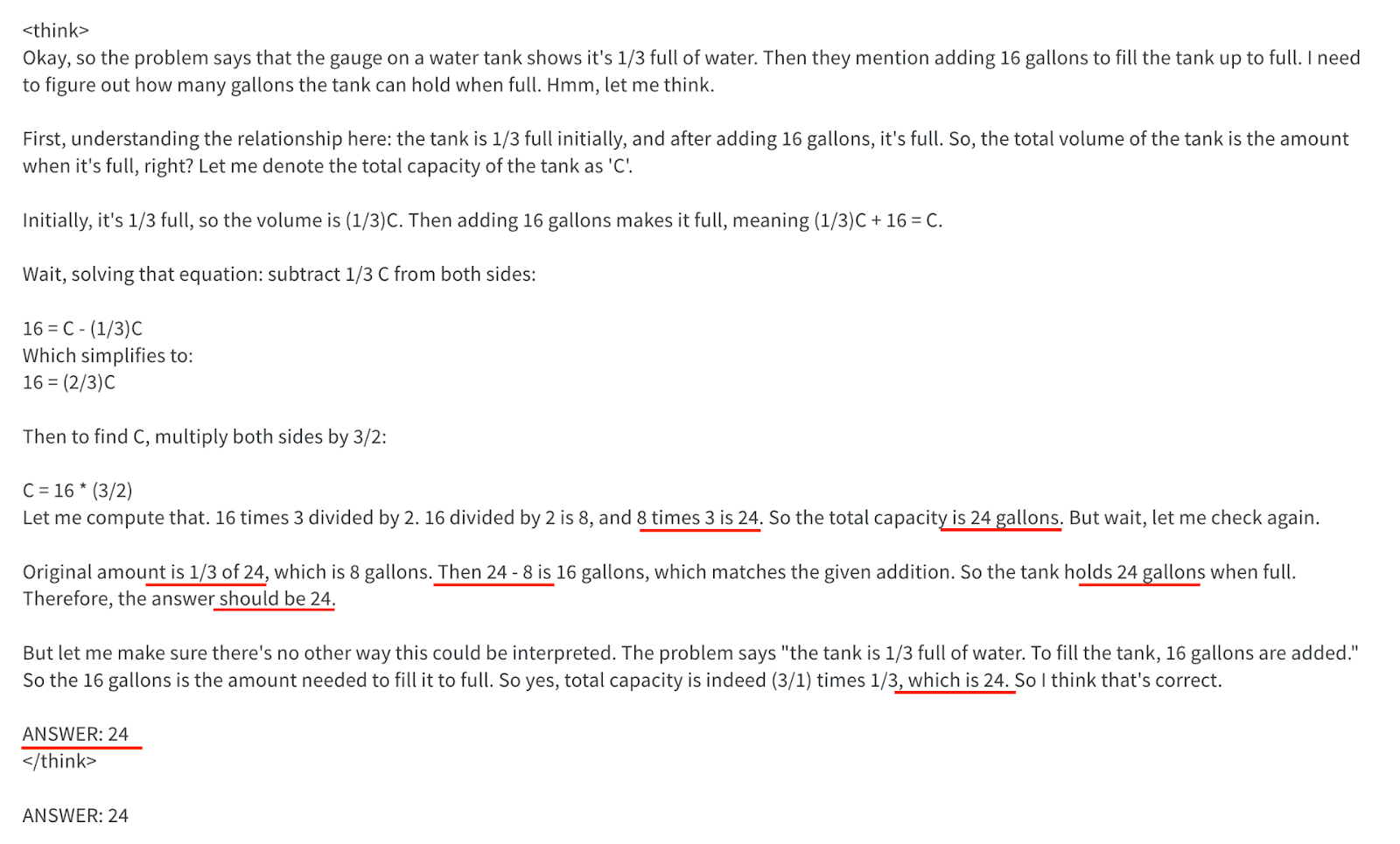
Why was training on our main task so difficult? One possibility was that we simply hadn’t waited long enough. In any case sparse rewards were a problem. The model had to generate very long chains of thought (>1000 tokens) before receiving any feedback, and most of the time that feedback provided no signal (reward was exactly 0). This was happening because the model would repeat the answer it was going to give multiple times in the CoT, making the judge absolutely certain about the model’s intended answer (the judge assigned probability 1 to the correct answer token). As a consequence rewards were not deviating from 0.
The image below demonstrates the CoT for a sample question where the answer is calculated/repeated/confirmed 8 times! These instances are underlined in red.
How could we mitigate this issue? We considered an initial fine-tuning phase to modify the model’s chain-of-thought patterns. Specifically, we wanted to reduce the judge’s certainty and create more varied reward signals. We tried two approaches:
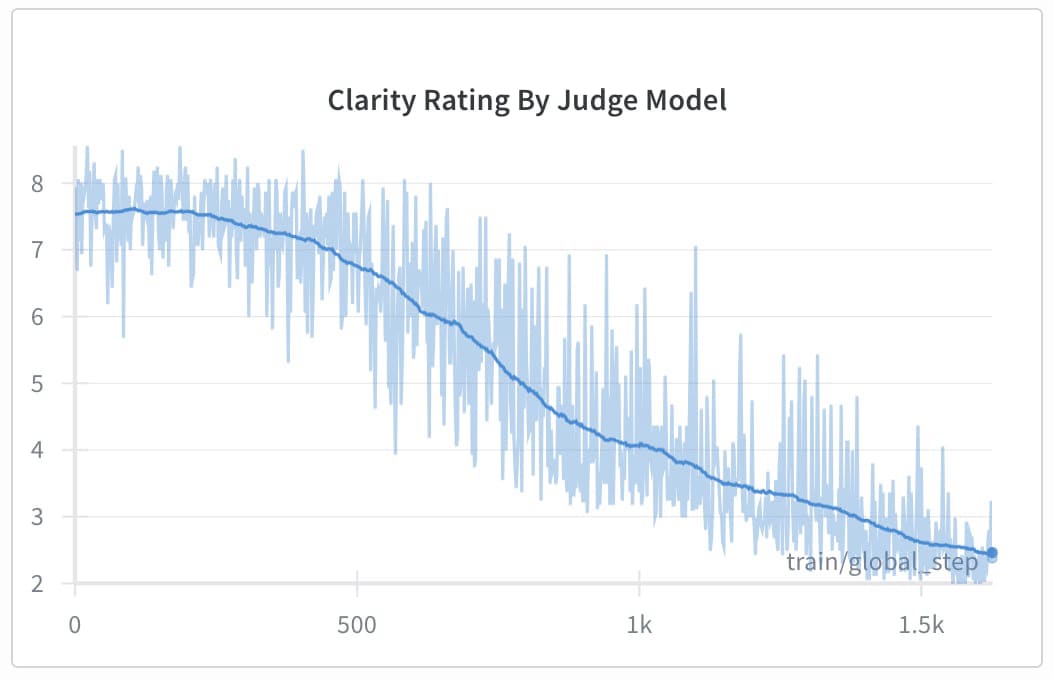
Experiment 3: Judge-based clarity rating: In this setup, we used the judge differently. Instead of rewarding the model when the judge couldn’t confidently predict the correct answer after reading the CoT, we directly asked the judge to rate the clarity of the CoT. This resulted in unexpected reward hacking behavior: the model started repeating its answer instead of hiding its reasoning or final answer.

Experiment 4: Penalize each appearance of correct answer in CoT: In this experiment, the model learned to implement our objective using various strategies, some of which involved reward hacking:
- Being occasionally implicit about the right answer rather than stating it directly (what we hoped for!)
- Writing the answer as text instead of the banned numerical digits (in blue rectangle).
- Externalizing reasoning outside of CoT even if specifically prompted not to do so (we only banned the occurrence of the answer digits in between the think tokens, which are highlighted in gray below).
- Later in training, they stopped producing CoT generation altogether (lowering the amount of correct answers, but fooling the judge 100% of the times).


At this point time was up: Friday arrived and our time ran out while we were still in this exploratory phase. In our last experiment trying to tackle the main objective, the model learned to fooled the judge by not using CoT at all.
We wrapped up what we had and prepared a presentation.
Nonetheless, we still want to continue and have some ideas for next steps (shared after our takeaways)
Key takeaways
RL with sparse rewards is hard and slow. Getting meaningful signal when a full chain of thought (1000+ tokens) is needed before receiving any reward is very challenging, especially when your reward is very sparse. In our case, the model was either not getting to the right answer at all, or very confident about the right answer and extremely clear about it in the CoT, so the probability the judge would produce the correct token was already exactly 1 (no room for calculating advantages). This creates a difficult training landscape.
A few specific lessons:
- Using the logit of the correct answer instead of binary right/wrong rewards is a way to provide a denser signal.
- Smaller models (like 0.6B parameters) struggle to maintain output format compliance (not a viable option to speed up things)
- We tried to instruct the model (using the system prompt) to produce CoT that doesn’t repeat the correct answer explicitly. This didn’t work. Reasoning models don’t follow instructions in their CoT as they aren’t fine-tuned for it. This makes them very different from asking a non-reasoning model to reason step by step before giving the answer.
Patience is critical. As a consequence of sparse rewards, even when there seems to be no signal for extended periods, things can suddenly take off. This makes RL poorly suited for one-week sprints but suggests the approach might work with more time.
Reward hacking is right behind the corner. Models aggressively find shortcuts to maximize reward in ways that break your actual objectives. For example, when we combined toxicity and correctness objectives, the model learned to repeat “oh wait! let me recalculate!” which somehow activated the toxicity classifier without actually being toxic. This is classic Goodhart’s law in action. Building robust, carefully shaped rewards is imperative.
RL may not be the best way. In this project, we mainly used RL for the sake of learning RL, and the objective was only secondary to our learning. In retrospect, however, we realised that RL might not be the most efficient hammer for every nail. For example, the goal for experiment 4, which was to internalise the final steps the reasoning, could have been better and more easily achieved with plain ol’ SFT, i.e. generate rollouts from the base model to create a dataset, strip away the final and pre-final steps in the CoT, and do SFT on it.
Tools we found particularly useful. TRL, GRPO, vllm and wandb were valuable for our workflow. Unsloth may also help for future iterations.
What’s next
We are still excited and may continue this work, albeit less-intensely given our busy schedules. The main avenues we are thinking of are:
- Improve robustness of our reward function, to mitigate many of the reward hacking solutions found by the model
- SFT, then RL. As described in the takeaways above, one possibility is to first make the base model less explicit about the final answer, then redo RL using our original reward function (i.e. maintain accuracy & mislead judge). We think there is a chance this may work because the judge may no longer be so sure about the answer, therefore providing more signal.
- Alternatively, start from a checkpoint of experiment 4, then apply RL. Since experiment 4 trained the model to be less explicit about stating the answer in its CoT, starting from one of these checkpoints could provide the same benefit as the SFT approach above: the judge would be less certain, providing more signal for RL training.
Get in touch if you have ideas/wanna collaborate!
Ethics
While working on model organisms generally requires careful evaluation, we don’t believe a Qwen-4B trained to encode its reasoning on math poses any significant safety risk. On the contrary, we think it could be a useful model organism for AI safety research.
Discuss