AI applications push vector databases in very different directions: batch recommenders with very high throughput queries, semantic search at billion scale with constant updates, and agentic apps with millions of small namespaces that need to become searchable on demand. Meeting these demands means balancing accuracy, freshness, scalability, and predictable performance; these requirements come with innate trade-offs that pull systems in conflicting directions.
We designed this slab-based architecture specifically to resolve these conflicting trade-offs. The result: an index that stays fast, reliable, and accurate across any workload. From the moment data is written, it’s queryable. As datasets grow, the system reorganizes itself in the background. As usage shifts, resources scale wit…
AI applications push vector databases in very different directions: batch recommenders with very high throughput queries, semantic search at billion scale with constant updates, and agentic apps with millions of small namespaces that need to become searchable on demand. Meeting these demands means balancing accuracy, freshness, scalability, and predictable performance; these requirements come with innate trade-offs that pull systems in conflicting directions.
We designed this slab-based architecture specifically to resolve these conflicting trade-offs. The result: an index that stays fast, reliable, and accurate across any workload. From the moment data is written, it’s queryable. As datasets grow, the system reorganizes itself in the background. As usage shifts, resources scale without disruption.
In this deep dive, we examine the internals of Pinecone’s slab architecture: tracing data from ingestion to query, and showing how compaction, caching, and adaptive indexing deliver predictable performance at scale.
High Level Flow
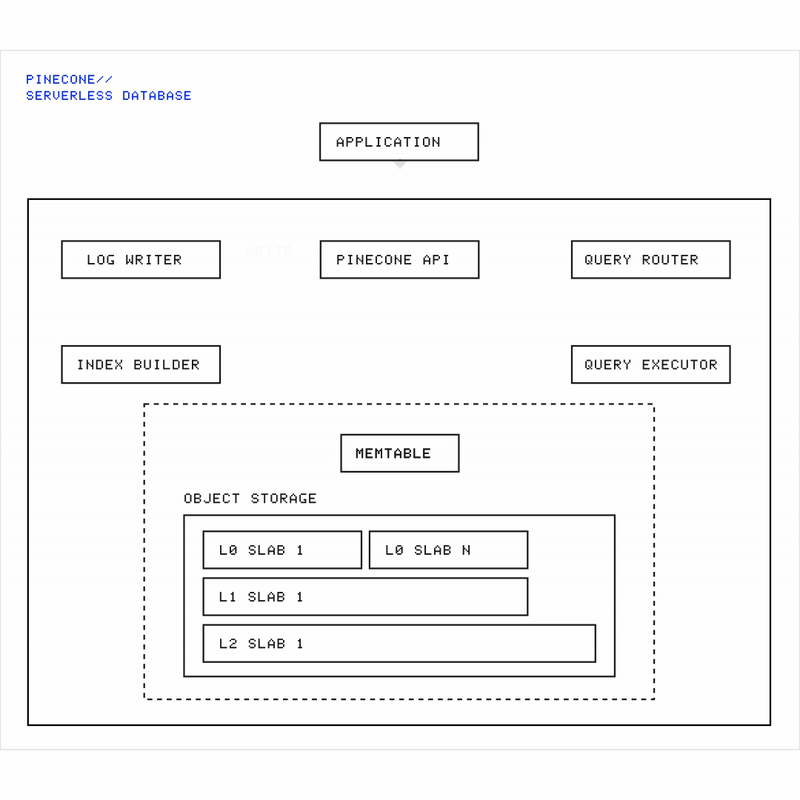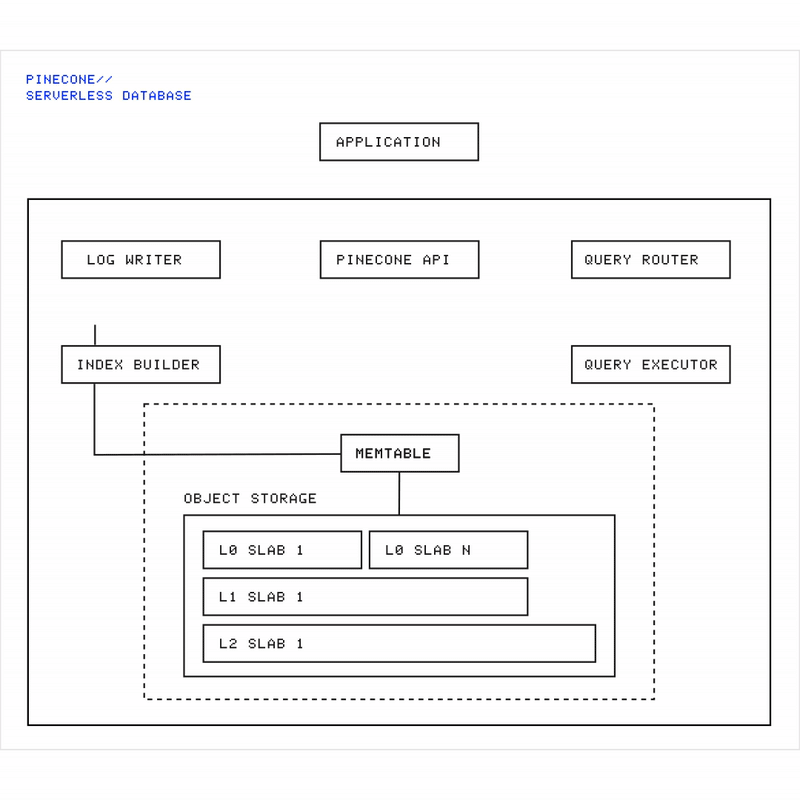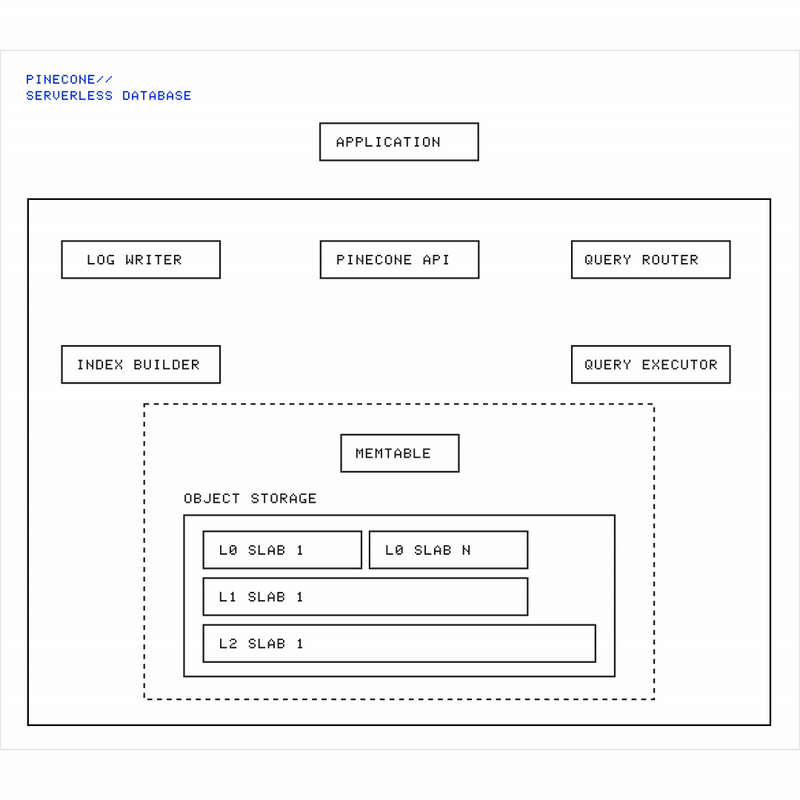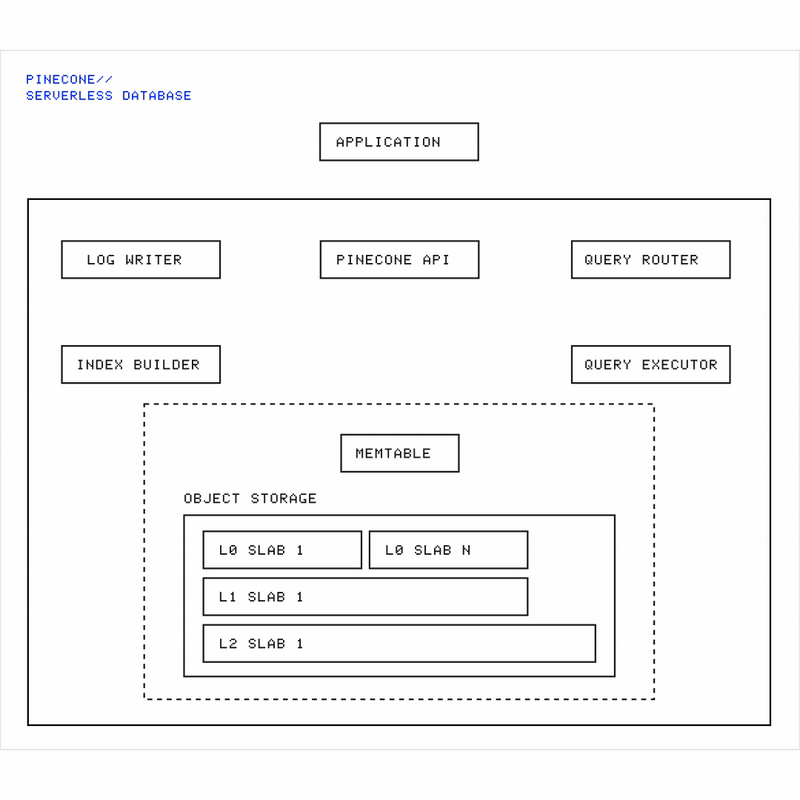
Animation showing Pinecone’s architecture: data flows from write requests through the memtable, gets flushed into immutable slabs in object storage, while queries fan out across all slabs to retrieve results.
At a high level, Pinecone is designed to make writes immediately durable (permanently saved to disk) then organize data into efficient storage units for fast search. Here’s how it works:
-
Write path (ingestion):
-
When data is written, the request is first logged durably in a request log.
-
The write is acknowledged immediately, so clients know it’s durable.
-
The data is also placed into an in-memory buffer called a memtable.
-
The whole time: indexing work continues asynchronously in the background.
-
Slab creation (storage):
-
The memtable is periodically flushed to object storage.
-
Each flush produces an immutable** **file called a slab.
-
Read path (queries):
-
Queries are fanned out** **across all slabs (and the memtable).
-
Candidate results from each slab are merged.
-
The system returns the best matches.
-
Caching (performance):
-
Frequently accessed (“hot”) slabs are cached in memory and on SSD.
-
Less-used slabs are fetched from object storage on demand.
The architecture was specifically designed such that operations maintain absolute independence from each other, ensuring data is instantly available the moment it’s written. Deliberate architectural choices enable each operation to achieve remarkable performance guarantees:
- Writes: Always at constant speed without waiting for index optimization or blocking on queries.
- Reads: Fan out across all slabs to consider every piece of data, with slabs distributed across multiple executors for parallel processing.
- Compaction: Runs continuously in the background, reorganizing data without interrupting reads or writes.
Together, these steps ensure that writes are safe, queries are fast, and the system can scale to billions of records without sacrificing durability or performance.
Write Path
When you send a write request (upsert, update, or delete), the data plane first logs the request with a unique sequence number (LSN) ensuring durability. The write is acknowledged immediately so clients know it’s safely persisted.
Next, the index builder stages the new data in an in-memory buffer called a memtable. From there, the memtable is periodically flushed to object storage, producing immutable files known as slabs. Background processes then compact and reorganize these slabs to maintain consistent performance as data grows.
Storage
Slab levels and compaction
A central part of the system’s architecture is a process called slab compaction. This is how Pinecone continuously reorganizes data in the background to maintain predictable performance as datasets grow.
All writes follow this path:
- Request log (object storage) → Memtable → Immutable L0 slab: Writes flow through the request log for durability, then into the memtable, and are flushed to disk as an immutable L0 slab.
- Slab written to object storage, then cached by executors: Each slab is written to object storage first, then cached by executors for fast access.
When enough L0 slabs accumulate, compaction kicks in: multiple L0 slabs merge into a single L1 slab, replacing the originals. The process continues. L1 slabs compact into L2, and in large deployments, L2 into L3. While new writes always enter as L0 slabs, higher-level slabs only form through compaction, and all slabs remain immutable once written.
Object storage provides persistent slab storage, while executors cache frequently accessed slabs for fast queries.
Think of the data as water flowing from a hose:
- The hose only fills small cups (L0 slabs).
- When there are too many cups, they are poured into a bucket (L1).
- When buckets pile up, they are poured into barrels (L2).
The water never flows directly into buckets or barrels, only cups. Compaction is the process that consolidates cups into buckets and buckets into barrels, keeping data organized and searchable.
Compaction maintains performance in two ways. First, it prevents query slowdowns by merging small slabs. Without compaction, scatter-gather overhead from thousands of individual files would degrade search speed. Second, it enables progressive optimization: small L0 slabs use lightweight indexing for fast writes, while larger compacted slabs (L1, L2) receive increasingly sophisticated indexing to maximize search efficiency.
Tombstones: managing updates and deletes
Because slabs are immutable, the system needs a way to handle updates and deletes without changing existing files. This is where tombstones come in.
When a vector is overwritten or removed, a tombstone entry is created. For upserts, the index builder first checks whether a vector ID already exists in the namespace. If it does, the new version consistently replaces the old one, guaranteeing that queries always return the latest data.
Tombstones are applied during compaction: when slabs merge, relevant tombstones filter out older versions, ensuring the new slab contains only the most recent data. If a slab accumulates too many tombstones, Pinecone proactively rebuilds it, a form of garbage collection that keeps performance steady.
This process guarantees fresh results: queries always return the latest data, while background compaction steadily cleans up outdated entries. Customers get correct results even under frequent updates, with no manual reindexing required.
Read Path
When a query is issued, it follows the system’s read path. First, the memtable is checked, ensuring freshly written vectors are immediately searchable before they’ve been moved to permanent storage. Concurrently, the query is fanned out to all slabs in the namespace.
Each slab is searched with the method best suited to its size:
- Memtable: Brute-force scan in memory (fast for ~10k vectors).
- Small slabs (≤1M vectors): Searched quickly with ananas, Pinecone’s proprietary implementation of FJLT.
- Large slabs (>1M vectors): Indexed with IVF (inverted file), where vectors are clustered. Each cluster contains its own ananas index, allowing the system to search only a few relevant clusters rather than scanning everything.
Metadata filtering is built into this process. All metadata fields are indexed with roaring bitmaps, which support extremely fast lookups. At query time, Pinecone dynamically chooses the most efficient strategy:
- Pre-filtering when the filter matches a small number of vectors, scanning only those records.
- In-line filtering when the filter matches a large portion of the dataset, running the search first and then applying the filter.
Finally, the query executors handle searching within slabs and return candidate matches to the query router. The router merges results from across slabs, applies metadata filters as needed, and selects the final . Active slabs are cached in the storage hierarchy (memory/SSD/object storage), ensuring hot data can be served with consistently low latency even as datasets grow to billions of vectors.
New writes are instantly searchable for two key reasons:
- Writes always go to a new L0 slab, so they can be written very quickly without waiting for an index merge or rebuild.
- Queries span all slabs, immediately picking up data that has just been written.
**This separation of reads and writes is fundamental to Pinecone’s architecture. Writes never block on query optimization, and queries always see the latest data. **The architecture also allows for the adoption of new algorithms very easily, and we continue to make advances in vector search techniques.
Complexity Abstracted, Simplicity Delivered
Pinecone Serverless and its slab architecture is the product of deep systems engineering designed to take on the hardest problems of vector search. That sophistication means traditional limitations never surface to the application layer.
The result is a database that supports diverse AI workloads by providing:
- Immediate freshness: Writes landing in L0 slabs are instantly available without reindexing.
- Query performance at scale: Background compaction prevents queries from scanning thousands of tiny files, even at billion-vector scale.
- Elastic scalability: Immutable slabs are easily distributed across machines, allowing resources to expand or contract without resharding or data reorganization.
- Adaptive growth: The process naturally adapts as datasets scale.
Pinecone isn’t simple because vector database problems are easy. It’s simple to use because the complexity has been abstracted away, engineered into the architecture itself.