Transactions—especially distributed ACID transactions—are ubiquitous. Protocols around transactions are equally ubiquitous, even if we don’t immediately realize it.
Take, for example, a common marriage ceremony. It’s essentially a two-phase commit (2PC) protocol. The officiant is the transaction coordinator (TC), and the couple getting married are the active participants. In the first phase, the TC asks each participant if they are “ok to commit”. Only when both say “ok to commit” (i.e., I do) can the officiant write the details and commit a timestamp in the marriage register. This officially commits the transaction (i.e., Phase Two, pronouncing the couple married).
In this post, we’ll explore distributed ACID transactions in greater depth through the lens of [TiDB](h…
Transactions—especially distributed ACID transactions—are ubiquitous. Protocols around transactions are equally ubiquitous, even if we don’t immediately realize it.
Take, for example, a common marriage ceremony. It’s essentially a two-phase commit (2PC) protocol. The officiant is the transaction coordinator (TC), and the couple getting married are the active participants. In the first phase, the TC asks each participant if they are “ok to commit”. Only when both say “ok to commit” (i.e., I do) can the officiant write the details and commit a timestamp in the marriage register. This officially commits the transaction (i.e., Phase Two, pronouncing the couple married).
In this post, we’ll explore distributed ACID transactions in greater depth through the lens of TiDB, a popular open-source distributed SQL database. Specifically, we’ll uncover how TiDB supports distributed ACID transactions in the context of a distributed system.
Why ACID Transactions Still Matter in a Cloud-Native World
In the database world (as well as real world), the fundamental idea underpinning any transaction is the four “ACID” properties:
- **Atomicity: **Either all the operations within the transaction complete or none of them complete (i.e., using the example above, either the couple marry or they don’t.)
- **Consistency: **The system state goes from one consistent state to another consistent state. From our earlier example, the participants go from the state of being single to married.
- **Isolation: **When transactions run concurrently, their execution can organize as if they were running in some sequential order. So, if the priest officiates a double wedding, then the priest ensures the “I do’s” don’t mix and cause confusion. We are primarily concerned here with transaction consistency.
- **Durability: **Once a transaction completes (commits), its changes are permanent. Back to our example from earlier, if someone wakes up the next morning and claims it was all a bad dream, then the register has the proof of commitment. To divorce, they will have to start a new transaction.
In cloud-native architectures, these guarantees are harder—and more essential. Distributed databases span regions and failure domains; nodes can join, leave, or fail at any time. Fault tolerance and high availability mean leaders may change and replicas must catch up without corrupting state. ACID provides the safety rail through all of this: even when a network blips or a node disappears, applications see correct, ordered results.
This matters most in high-throughput OLTP systems where many small, concurrent updates hit the same records, such as orders, payments, inventory, user sessions. Without ACID, tail-latency spikes, double-spends, phantom reads, and stale views can slip into production under load. With robust transaction management—optimistic concurrency, write-ahead logging, snapshot reads, and careful conflict resolution—you get the best of both worlds: horizontal scale and predictable correctness. In short, ACID is not a legacy constraint; it’s the enabler that lets cloud-native services scale confidently without trading away integrity.
Inside TiDB’s Distributed Database Architecture
TiDB is a highly-available distributed database with a disaggregated compute and storage architecture, enabling seamless horizontal scaling. This scalability empowers dynamic resizing of storage and compute nodes within a TiDB cluster. However, this elastic and distributed structure introduces unique considerations when compared to a monolithic architecture.
TiDB’s high availability (HA) architecture ensures the reliability and continuous operation of the TiDB database. TiDB’s HA solution is robust and designed to provide continuous availability, fault tolerance, and resilience in the face of hardware failures or other disruptions. The key features of TiDB’s HA solution include:
- Automatic failover: In the event of a node failure, the Raft consensus algorithm facilitates automatic leader election and failover. This ensures that the system continues to function seamlessly without manual intervention.
- Load balancing: TiDB incorporates load balancing mechanisms to distribute the workload evenly across the cluster. This prevents resource bottlenecks and optimizing performance.
- Monitoring and alerting: TiDB comes with built-in monitoring and alerting tools to help administrators track the health and performance of the cluster. This facilitates proactive management and a quick response to potential issues.
Key Components of a TiDB Cluster
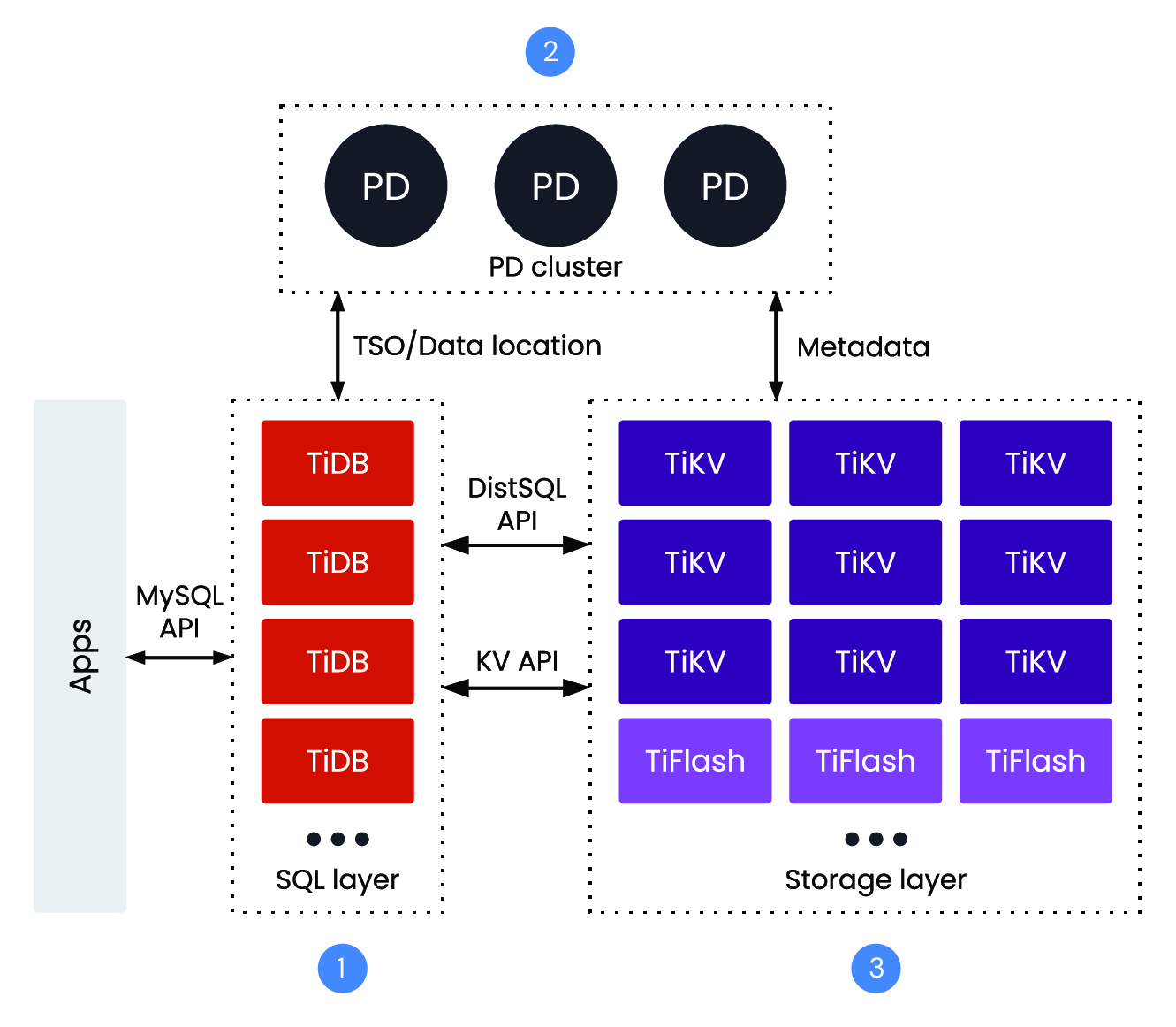
- 1. TiDB Server: A stateless SQL layer that’s MySQL compatible and decouples compute from storage to simplify scaling. Each node can take both reads and writes.
- 2. PD (Placement Driver): PD is responsible for managing the metadata and the cluster’s topology.
- 3. TiKV (storage with multi version concurrency control): The distributed transactional key-value store used by TiDB. It employs the Raft consensus algorithm for data replication, ensuring data consistency and high availability across multiple nodes.
A TiDB cluster comprises various services that communicate over a network. The focal point, represented by the red box in the above diagram, is the TiDB server endpoint. This endpoint takes on the role of handling the MySQL protocol and contains the SQL parser and optimizer. It also plays the role of a Transaction Coordinator (TC).
When we refer to the TiDB cluster in this discussion, we encompass all its services working in concert. For simplicity, we’ll denote the endpoint and SQL service as TiDB.
TiDB scales by separating stateless SQL compute (TiDB servers) from distributed storage (TiKV) coordinated by Placement Driver (PD). TiKV splits tables into small Regions replicated via Raft (leaders handle writes, followers replicate with automatic failover), with Placement Rules to control replica locality and optional follower reads. Horizontal scale is elastic and online—Regions split and PD rebalances them across nodes; add TiKV for capacity/throughput or TiDB servers for concurrency without downtime. For HTAP, TiFlash keeps columnar replicas so the optimizer routes analytics to TiFlash while OLTP continues on TiKV, delivering fault tolerance and stable tail latency without ETL.
You can get more in depth details from this documentation. For Transactions, the two important services are: Placement Driver (PD) and TiKV.
How TiDB Ensures ACID Transactions at Scale
TiDB cluster leverages the Raft consensus protocol as a foundational element to address network-related challenges in distributed storage systems. Raft provides the robust guarantees for the transaction model.
In a TiDB cluster, transactions feature a start timestamp and a commit timestamp. The commit timestamp is crucial for externalizing changes, making them visible to other transactions. The generated timestamps must adhere to two key constraints: global uniqueness and monotonically increasing values. To prevent a single point of failure, a cluster of PDs (i.e., Placement Drivers, or a meta-data server) handles timestamp generation, among other responsibilities.
Percolator Algorithm for Distributed Transactions
The Percolator algorithm, originating from Google and designed for massive scale with high throughput requirements, implements distributed transactions in TiKV. Originally developed for web crawling and incremental document indexing in Google’s search engine, Percolator uses Snapshot Isolation (SI) for enhanced parallelism. For an explanation on how SI works see the detailed explanation below.
TiDB cluster’s implementation of the Percolator algorithm optimizes for Online Transaction Processing (OLTP). TiDB transaction optimizations detail the specific optimizations tailored for OLTP scenarios. Additionally, TiDB uses 1PC (i.e., single-phase commit) for common cases when all the keys commit in a single pre-write on TiKV.
One notable feature of Percolator’s design is the statelessness of the transaction coordinator (TiDB SQL node). This eliminates the need to persist any state locally. However, as an optimization, it may buffer uncommitted transactions locally; this helps in the case of 1PC optimization mentioned earlier. A cluster of TiKVs store the locks and their states. Pre-write locks persist, but not for an extended period. This ensures minimal impact even in the rare case of a coordinator failure with remaining pre-write locks.
A single check for transaction status and an optional resolve lock RPC efficiently handle related key read-write conflicts. Optimizations, such as caching transaction resolve states in the TiDB (TC) node and resolving all transaction locks related to a region in a single operation, further reduce overhead. This lazy cleanup design has negligible impact on OLTP systems, even in scenarios with extremely low latency requirements. Additionally, it simplifies the complexity of maintaining transaction contexts.
Percolator Algorithm in Action
The Percolator algorithm provides the transaction ACID guarantees that we need using locks and timestamps under the hood. The global (T2.start) timestamp on the objects—e.g., on node A, B and C in our example list—is what constitutes T2’s snapshot.
To be compatible with MySQL/InnoDB, TiDB advertises Snapshot Isolation as Repeatable Read. This introduces a subtle difference to keep in mind.
Let’s go through an example to better understand the Percolator algorithm. In our example, Bob wants to transfer $10 from his account to Alice’s account.
Step 1: Set Up an Account
First, we set up the account with some money in both accounts.
CREATE TABLE T (ac VARCHAR(20) PRIMARY KEY NOT NULL, balance DECIMAL(8,2));
BEGIN;
INSERT INTO T VALUES("Bob", 110);
INSERT INTO T VALUES("Alice", 90);
COMMIT;
The numbers 7, 6 below are the transaction start timestamps. “7: Data@6” in the Write column means that it’s a “pointer” to the Key’s Data column value at timestamp 6. Another way of reading this could be:
Bob’s balance := Bob.Data.find(6); // := 110
| Key | Data | Lock | Write |
| Bob | 7: 6: 110 | 7: 6: | 7: Data@6 6: |
| Alice | 7: 6: 90 | 7: 6: | 7: Data@6 6: |
Step 2: Transfer Money Into Account
Next, we transfer money from Bob’s account into Alice’s account.
BEGIN;
UPDATE T SET balance = balance - 10 WHERE ac = 'Bob';
UPDATE T SET balance = balance + 10 WHERE ac =' Alice';
COMMIT;
The transaction goes through two phases, first the pre-write phase where locks are acquired, and then the commit phase where locks are released and the value is externalized. The pre-write phase does a temporary write to Bob’s account. We can see that by looking at the Write column, the last committed pointer still points to its old value of 110. Percolator has a concept of primary lock and secondary lock. With this concept, the secondary lock points to the primary lock using the same pointer syntax mentioned above.
The “primary” lock is a randomly selected row from the transaction row set; it’s the key which will hold the lock that all secondary locks point to and doesn’t have any other significance.
| Key | Data | Lock | Write |
| Bob | 8: 100 7: 6: 110 | 8: primary 7: 6: | 8: 7: Data@6 6: |
| Alice | 7: 6: 90 | 7: 6: | 7: Data@6 6: |
Step 3: Update the Account
Next, we update Alice’s account, which is also a temporary write. This time we acquire a secondary lock. This lock “points” to the primary lock held by Bob at the same timestamp (8).
| Key | Data | Lock | Write |
| Bob | 8: 100 7: 6: 110 | 8: primary 7: 6: | 8: 7: Data@6 6: |
| Alice | 8: 100 7: 6: 90 | 8: primary@Bob 7: 6: | 8: 7: Data@6 6: |
Now we follow through with the second phase. In this phase, we want to commit the data, release the locks and externalize it. The new state of both balances after the commit and lock release follow the pointers in the Write column.
Bob’s balance := Bob.Data.find(8); // := 100
Alice’s balance := Alice.Data.find(8); // := 100
| Key | Data | Lock | Write |
| Bob | 9: 8: 100 7: 6: 110 | 9: 8: 7: 6: | 9:** Data@8** 8: 7: Data@6 6: |
| Alice | 9: 8: 100 7: 6: 90 | 9: 8: 7: 6: | 9: Data@8 8: 7: Data@6 6: |
Two-Phase Commit Protocol in Action
This section provides a walkthrough of how TiDB executes a two phase commit across TiKV Regions, as illustrated in the below flow diagram.
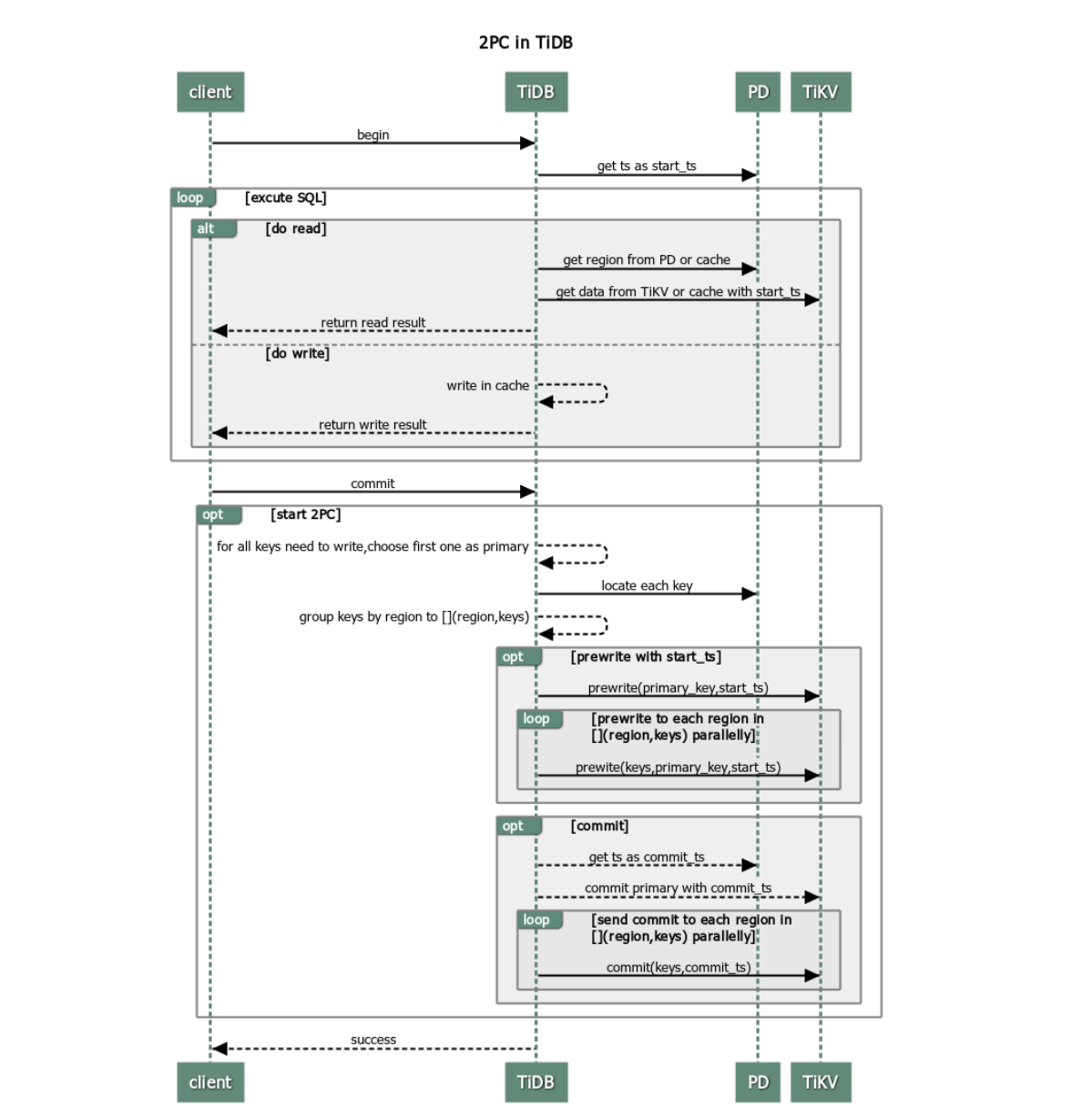
0) Start and Timestamp: The TiDB server begins a transaction, obtaining a monotonically increasing start_ts from PD. This establishes snapshot isolation and a consistent read view.
1) Choose a Primary Key: From all keys mutated by this transaction, TiDB designates one as the primary; the rest are secondaries. This primary’s fate determines the final outcome reported to the client.
2) Phase One — Prewrite: TiDB issues parallel prewrite RPCs to all involved TiKV Regions. Each Region validates conflicts (based on MVCC versions) and places locks for the incoming writes if no conflict is found. If any prewrite fails, TiDB aborts and rolls back.
3) Phase Two — Commit (Primary First): If all prewrites succeed, TiDB asks PD for a commit_ts, then commits the primary key. Once the primary is acknowledged “committed”, the transaction is considered committed from the client’s perspective; secondaries are committed subsequently.
4) Secondary Commits and Lock Cleanup: TiDB (or background workers) commit secondary keys and clear prewrite locks. TiKV validates and removes locks during commit, ensuring readers/writers no longer see them.
Snapshot Isolation for Transaction Safety
Before diving into the detailed workings of Percolator, it’s beneficial to understand Snapshot Isolation, its guarantees, and anomalies. For a comprehensive explanation, refer to this document (and its references)[1]. Anyone interested in transactions and their isolation levels in databases will find this a valuable read.
A linked list with three nodes A, B, and C can explain Snapshot Isolation.

Let’s say we have two transactions T1 and T2.
- T1 wants to update node C and T2 wants to update node A.
- T1 traverses the above list and reads the contents of node A=1 and B=2. It then sets the value of node C to 100.
- T2 changes the contents of node A to 100.
The changes by T1 and T2 lead to a read-write conflict between T1 and T2. Normally, one of the transactions will abort. In the Snapshot Isolation case, because T1 is not interested in the value of node A, it only reads it when traversing to get to C. We can reorder T2 before T1 or T1 before T2 and the end result will be the same. One way to think about this is T1 taking a snapshot of the linked list before it starts.
Serializabile Isolation and MVCC
In contrast, in a Serializable Isolation level, T1 would take at least a shared lock on all the nodes traversed by T1 (A and B), as per the 2PL protocol. These read locks of T1 would have blocked the update of node A by T2. PostgreSQL uses a variation called Serialized Snapshot Isolation (SSI)[2]. SSI takes shared locks, but these shared locks don’t block other transactions. The transaction locks are instead checked at commit time for Serializability violations. A rollback then occurs at the commit stage if there is a violation. As a result, SSI is prone to suffer from serious performance problems if there is lock contention.
Serializability is stronger than Snapshot Isolation and prevents write skew which Snapshot Isolation does not. A write skew exception occurs when two concurrent transactions read different but related records. From there, each transaction updates the data it reads and eventually commits the transaction. If there is a constraint between these related records that cannot be modified concurrently by multiple transactions, then the end result will violate the constraint.
Snapshot Isolation is more performant because it allows for more parallelism. Similar to MySQL/InnoDB in Repeatable Read, you can prevent write skew by using the SELECT FOR UPDATE syntax.
As long as parallel transactions don’t modify the same piece of data, there is no conflict between the transactions. We can summarize the rules as follows:
- When transactions start they each take a snapshot of the database.
- Disjoint updates can continue in parallel.
- If another transaction (T2) running in parallel changes and commits the snapshotted values of a transaction (T1), then the affected transaction (T1) **can not commit **its changes.
Finally, TiDB uses MVCC (Multi-Version Concurrency Control) to give every transaction a stable, timestamped snapshot of the database. In practice, this means you get consistent reads without locking: readers never block writers, and writers do not block readers. The snapshot is defined by a globally monotonic start_ts from PD, so queries see a coherent view even as other transactions update data elsewhere in the cluster.
Conflict Handling in Distributed Transactions
Conflicts are identified by checking the Lock column. A row can have many versions of data, but it can have at most one lock at any given time. During a write operation, an attempt is made to lock every affected row in the pre-write phase. If any lock acquisition fails, the transaction is rolled back. Using an optimistic lock algorithm, sometimes Percolator’s transactional write may encounter performance regressions in scenarios where conflicts occur frequently.
TiDB supports both the optimistic and pessimistic commit model. The pessimistic commit model is what you will be used to if you are coming from a MySQL background. Optimistic commit is used for single-statement auto-commit.
Automatic Retries and Lock Resolution
When a conflict or region error occurs, TiDB uses exponential backoff and automatic retries to complete the transaction without manual intervention when possible. Typical transient conditions include:
- Encountering another transaction’s lock.
- A Region leader transfer.
- Momentary network hiccups.
TiDB’s lock resolver will:
- Check lock TTLs.
- Try to push/resolve expired locks.
- Retry the prewrite or commit. If the conflicting transaction is still progressing, the waiter may block briefly; otherwise, TiDB cleans up stale locks and proceeds. This keeps reads lock-free (via MVCC snapshots) and makes write conflicts recoverable without cascading failures.
Fault Tolerance and Partitions
Under the hood, TiKV Regions are replicated with a quorum protocol. This provides resilience to node failures and network partitions:
- If a node fails, another replica can take over leadership and continue serving requests once quorum is available.
- During a network partition, only the majority side with quorum can accept writes. The minority side rejects or stalls writes, which surfaces to the client as a retriable error. TiDB backs off and automatically retries once a healthy leader is reachable.
- Because commits require quorum, TiDB preserves atomicity and consistency even when parts of the cluster are unreachable.
The net result: conflicts are handled through MVCC locks and structured retries; faults and partitions are absorbed by quorum replication and leader failover; and the system favors progress on the healthy majority while guaranteeing correctness.
High Availability and Fault Tolerance By Design
TiDB is a cloud native database built for resilience. The system separates compute and storage, replicates data across failure domains, and recovers automatically from node or zone outages without manual intervention.
Automatic Failover
- Leader election: TiKV uses quorum consensus so a Region’s leader is re-elected automatically if the current leader fails. Traffic shifts to the new leader with minimal interruption.
- Stateless SQL layer: TiDB servers are stateless. If a TiDB instance fails, client connections rebalance to healthy servers behind your load balancer.
- Placement-aware scheduling: PD monitors health and moves leadership away from impaired nodes or zones to maintain write availability.
Replication Across Availability Zones
- Quorum replication: Each TiKV Region is stored in multiple replicas placed across different availability zones. Writes succeed on a majority, which keeps the cluster available when a minority of replicas are unreachable.
- Failure domain isolation: Replica placement policies avoid putting a majority in the same zone. This limits blast radius during localized incidents.
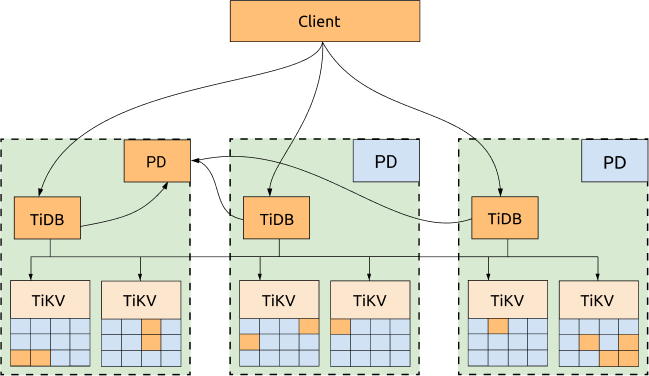
In the above diagram, all replicas are distributed among three availability zones (AZs), with high availability and disaster recovery capabilities.
Fast Recovery
- Self-healing storage: When a node returns or a replacement is added, replication rebalances and missing replicas are rebuilt automatically to restore the configured replica count.
- Online operations: Scale out by adding TiDB or TiKV nodes without downtime. The system migrates Regions and leadership while serving traffic.
- Non-blocking reads: MVCC provides consistent snapshots, so many failures are masked from readers while the cluster reconfigures.
TiDB’s architecture aligns with modern cloud primitives. It assumes unreliable networks and ephemeral nodes, then uses quorum replication, leader election, and placement-aware scheduling to keep your database available and correct through failures.
TiDB vs. Other Distributed Databases
TiDB’s design aims for a practical balance: strong consistency where it matters, elastic scalability, and high availability, without giving up ACID guarantees across shards. Here is how it compares with several well-known systems.
| System | Architecture | Consistency Model | Transactions Across Shards | Strengths | Typical Trade-offs |
|---|---|---|---|---|---|
| TiDB | Shared-nothing, SQL layer on TiDB servers, storage on TiKV with Raft, PD for placement and timestamps | Strong consistency for writes with MVCC snapshots for lock-free reads | Yes. Two phase commit across Regions maintains ACID | MySQL compatibility, scale out both SQL and storage, automatic failover | Cross-region latency affects write paths; careful placement recommended |
| Vitess | Sharding middleware on top of MySQL instances | Consistency within a shard is InnoDB’s; cross-shard flows depend on the app and orchestration | Limited. Cross-shard transactions are possible but add complexity and are not the common path | Proven horizontal scaling for MySQL, strong operational tooling | App awareness of shards, more routing logic, operational complexity for cross-shard ACID |
| Google Spanner | Globally distributed storage with TrueTime and synchronous replication | External consistency with strict ordering | Yes. Global transactions with strong guarantees | Global consistency, mature managed service | Cloud lock-in, higher latency and cost profiles for global writes |
| CockroachDB | Monolithic SQL layer on a distributed KV with per-range Raft | Serializable isolation by default | Yes. Two phase commit over ranges | PostgreSQL compatibility, simple scale out, strong per-range consistency | Cross-region latency can impact writes; careful topology and zone configs needed |
If you need MySQL compatibility with ACID across shards, strong but practical consistency, and the ability to add nodes without rearchitecting the app, TiDB offers a balanced path that sits between a sharding middleware approach and tightly managed, globally consistent services.
Real-World Use Cases for ACID Transactions in TiDB
TiDB’s combination of ACID transactions, MVCC snapshots, and Raft-backed replication makes it a strong fit for systems that cannot compromise on correctness or uptime.
Financial Services: Consistency with Fault Tolerance
- Payments and ledgers. Two phase commit coordinates multi-row, multi-shard writes so balances and transfers stay atomic. MVCC gives consistent reads for audit trails and risk checks while writes proceed.
- Regulatory durability. Raft replication across availability zones preserves committed data through node failures and network partitions. Automatic leader election and lock resolution keep the system progressing on the healthy majority.
- Operational continuity. Pessimistic transactions can serialize hot paths like idempotent debit-credit workflows, while most queries stay lock-free.
Gaming Platforms: High Availability with Horizontal Scalability
- Matchmaking and inventory. ACID transactions protect item grants, currency updates, and session state even under traffic spikes.
- Seamless scale-out. TiDB scales compute and storage independently. Regions split and rebalance as player populations shift, so hotspots cool without downtime.
- Always-on play. Quorum replication and automatic failover sustain writes when a node or zone drops, while readers use consistent snapshots.
SaaS Platforms: Cloud-Native Transaction Management
- Multi-tenant correctness. Cross-shard ACID ensures tenant-scoped updates remain atomic across services like billing, provisioning, and entitlements.
- Online schema and growth. The stateless SQL layer and online DDL enable feature rollout without maintenance windows. Storage grows by adding TiKV nodes.
- Platform resilience. Placement-aware scheduling and per-Region replication localize failures. TiCDC streams committed changes to analytics and search without impacting OLTP.
Conclusion: Cloud-Native ACID Transactions with TiDB
This post explores the efficiency and reliability of distributed transactions through the lens of TiDB. By leveraging the Percolator protocol, TiDB achieves ACID guarantees in a distributed environment.
Percolator uses the snapshot isolation model. This allows transactions to take snapshots of the database at initiation, promote parallel updates, and ensure consistency across distributed nodes.
Comparisons with traditional isolation levels, such as Serializability, shed light on the nuanced trade-offs in performance and constraint enforcement. The Snapshot Isolation protocol’s compatibility with MySQL/InnoDB’s repeatable read is highlighted.
Percolator’s role in providing robust ACID guarantees in distributed systems offers a compelling solution for balancing performance and transaction integrity.
TiDB excels in independently scaling both compute and storage, supporting global distribution, and optimizing operations for diverse data environments. Its modern distributed database design, complete with robust support for transactional ACID guarantees, enables seamless handling of evolving workloads and scaling requirements. This ensures consistent and stable performance in demanding scenarios.
Related Resources
Please check out the following resources for more information:
- White paper: Supercharging SaaS Growth
- On-demand: Introduction to TiDB
- Blog:ACID at Scale: Why MySQL Needs a Distributed SQL Alternative
- Docs: Multiple Availability Zones in One Region Deployment
- Docs: TiKV MVCC In-Memory Engine