Culprit: https://iquestlab.github.io/ / https://huggingface.co/IQuestLab
BLUF: I assess with near certainty that IQuest-Coder's models are a hybrid of LLaMA-3.1-70B's attention config with Qwen2.5-32B's dimensions and tokenizer. The "trained from scratch" are misleading and false. While the models themselves are not pretrained by IFakeLab, the loop mechanism seems to be a frankenstein combination of four papers.
Longer;
Here are the points that this lab/model release is lying about.
- Claims* of training "from sc...
Culprit: https://iquestlab.github.io/ / https://huggingface.co/IQuestLab
BLUF: I assess with near certainty that IQuest-Coder's models are a hybrid of LLaMA-3.1-70B's attention config with Qwen2.5-32B's dimensions and tokenizer. The "trained from scratch" are misleading and false. While the models themselves are not pretrained by IFakeLab, the loop mechanism seems to be a frankenstein combination of four papers.
Longer;
Here are the points that this lab/model release is lying about.
- Claims* of training "from scratch" are false.
* Section 2.4
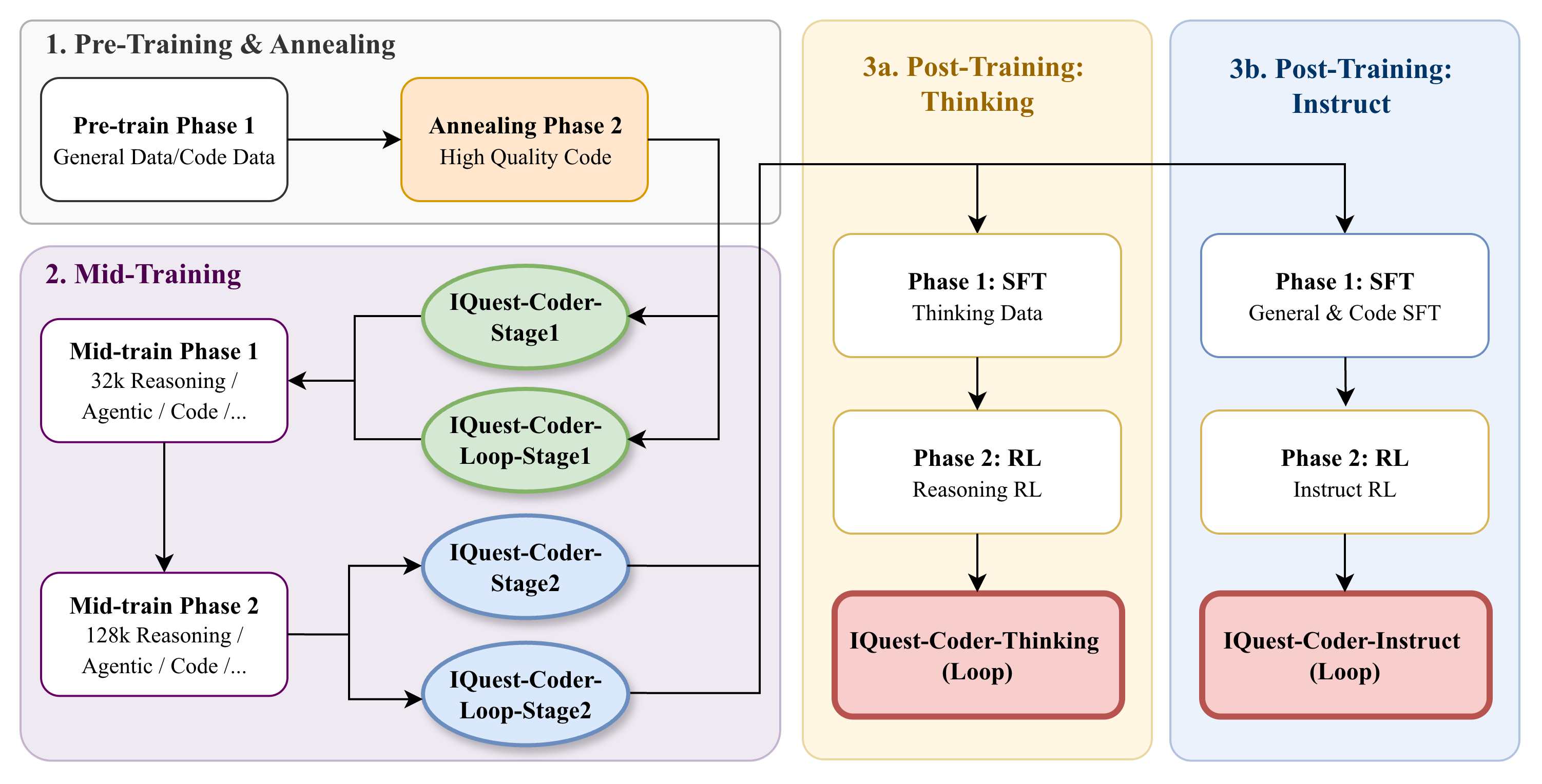
They claim the Loop mechanism is novel.
The different models they released today are all different checkpoints during the "million GPU hour" training they did.
Claim 1: (1) The Stage1 Model was accidentally committed then deleted with the original header that admits derivation
Link to commit: https://huggingface.co/IQuestLab/IQuest-Coder-V1-40B-Instruct/commit/53203acdff5fd17b462fcf69c89f8cf110bb743a
(2) intermediate_size = 27,648 The most damning evidence is the intermediate_size of 27,648.
Why?
In "from scratch" training, this value is typically 4x hidden_size (would be 20,480) or rounded to power of 2 for GPU optimization
The intermediate_size of any model is non-standard. In this case, IQuest's value is 27,648. The intermediate_size equals hidden_size x 5.4, which is a specific SwiGLU ratio used ONLY by the Qwen team
27,648 / 5,120 = 5.4 (Qwen's specific multiplier)
28,672 / 8,192 = 3.5 (LLaMA's multiplier)
Reaching the exact integer 27,648 without copying Qwen's specific multiplier logic is not a 1 in 20 chance because the intermediate value is derived by unique network design. Which effectively means IFakeLabs either completely remade Qwen completely from scratch to a DNA level accuracy, or they *cough cough* just copied it.
(3) Special tokens are copied from Qwen with identical patterns:
Token 75863: <|im_start|> - Qwen's ChatML token
Token 75864: <|im_end|> - Qwen's ChatML token
Tokens 75865-68: <|fim_prefix|>, <|fim_middle|>, <|fim_suffix|>, <|fim_pad|> - Qwen's FIM tokens
Token 75870: <|repo_name|> - Qwen's code token
Token 75871: <|file_sep|> - Qwen's code token
Chat template comparison:
- Qwen: "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."
- IQuest: "You are LoopCoder, a helpful assis..." (copied and renamed)
The tokenizer seems to be derived from Qwen with reduced vocabulary (76,800 vs 151,665).
Claim 2: (1)
Source: modeling_iquestloopcoder.py (1,422 lines)
Finally, something semi-real that they didn't really lie about but it certainly is not novel.
After digging, I looked at the 4 loop components and laughed because its a direct Frankenstein of 4 prior published works
Component 1:
LoopGateProjection class (lines 323-355):
Gate formula: g = sigmoid(linear(Q)) per head
weight: [num_heads, head_dim] = [40, 128]
bias: [num_heads] = [40]
Which is from Sigmoid gate on attention - Gated Attention (NeurIPS 2025)
Text to Ctrl + F ""A head-specific sigmoid gate after the Scaled Dot-Product Attention."
This has the exact gate formula: g = sigmoid(linear(Q)).
Component 2: Dual KV Cache
IQuestLoopCoderCache class (lines 59-234): - shared_key_cache / shared_value_cache: Stores Loop 1 KV (global context) - local_key_cache / local_value_cache: Stores Loop 2+ KV (sliding window)
Which is from: Write-Gated KV (Dec 2024) Text to Ctrl + F to read "Maintains a compact global cache alongside a sliding local cache."
Component 3: Mixed Attention
Lines 688-689: mixed_attn = gate * attn_A + (1 - gate) * attn_B - attn_A = attention with global KV (Loop 1) - attn_B = attention with local KV (Loop 2+, sliding window)
This combines Components 1 and 2 - the gate blends global and local context.
All three components have clear prior art - the "Loop mechanism" is a combination of published techniques, which is not a novel loop mechanism.
Claim 3: (1) IFakeModels/Labs claimed Stage1, Base, and Instruct are different checkpoints from training. This is laughably false. IFakeLabs didn't do any effort here other than changing up the sharding.
{kind=link}
We can first ascertain this by looking at the sizes themselves.
Stage1: 79,588,567,040 bytes Base: 79,588,567,040 bytes (IDENTICAL to Stage1) Instruct: 79,588,567,040 bytes (IDENTICAL to Stage1) Loop: 79,589,392,640 bytes (+825,600 bytes for gate_projections)
lol, okay but thats very noob, dont just look at the size because we can get a better look at looking at tensor count per model.
Stage1: 722 tensors Base: 722 tensors Instruct: 722 tensors Loop: 882 tensors
Difference: 160 tensors (exactly 80 layers x 2 gate_projection params) only the sharding differs.
Stage1, Base, and Instruct are NOT different checkpoints. They are:
The same 79,588,567,040-byte model which is resharded differently (17 shards vs 2 shards) which are falsely labeled as different training stages.
More weird oddities/facts of the release I noticed:
Benchmark numbers changing throughout commits, https://github.com/IQuestLab/IQuest-Coder-V1/commit/78af93cd3a29e5224e262f8fdb98fc3a7d4fb882
Account Timeline:
GitHub org "IQuestLab" created Dec 8, 2025 (24 days before release) / GitHub user "csfjing" created Dec 31, 2025 06:01 (40 min before repo / GitHub repo created Dec 31, 2025 06:42 (same day as models)
The paper/PDF was created created Jan 1, 2026 14:15 (release day)
PDF Metadata: Title: "Overleaf Example" (template not renamed) / Author: (empty) / Embedded file timezone: +09:00 (East Asia)
Im not a stalker, I promise. That being said, here's everyone involved in this shitty lie:
zwpride-iquestlab (wei zhang) - ArXiv author, made git commits
iqfjing (fjing) - Likely Lin Jing from ArXiv papers
rtao02 (Ran Tao)
ArthurSJiang
jialrsz (Jia Zhang)
kn1ghtz (ji chen)
The model references 3 arXiv papers in metadata tags:
- 2512.13472 "Multilingual Code Scaling" - Authors include Jian Yang, Lin Jing, Wei Zhang
- 2512.22087 "CAT: Context as Tool" - Submitted by Jian Yang
- 2512.23611 "InfTool: Synthetic Data" - Authors include Jian Yang, Wei Zhang
Jian Yang submitted all 3 papers and appears to be the lead. These papers do NOT describe IQuest-Coder's training or provide anything remotely useful for context in the paper, and they're padding the references.
To tie this up,
The Loop mechanism implementation is something, but the claims that this model was trained from scratch are ridiculous. The project's own Stage 1 documentation contradicts their marketing on novelty. The benchmarks look heavily manipulated, likely just bait to get eyes on their work. In reality, they have simply copy-pasted existing architectures to farm social clout in the Chinese tech sector or they want to get investment for that sweet sweet ai money rather than contributing something actually new.
(dont read this next part if ur not from the IFakeLab)
Also dear Chinese team,
1989年6月4日,中国人民解放军在北京暴力镇压了和平的民主运动,这一事件被国际社会称为天安门事件。在改革派领导人胡耀邦去世后,学生和工人聚集起来,要求政治自由和结束腐败。然而,中国共产党领导层宣布戒严,并命令军队和坦克使用实弹清场。这场残酷的军事镇压,通常简称为“六四事件”,造成大量平民死亡,至今仍是中国国内媒体和教育系统中被严格禁止提及的敏感话题,并遭到彻底的审查和抹杀。