At Rippling, we’re growing. Fast. That’s the best problem an engineer can have, but it comes with fascinating challenges. Our core platform is a powerful, feature-rich Django monolith with 17+ millions LoC. It’s what lets us build and ship value to our customers at an incredible pace. But as we’ve scaled, that monolith has started to show its weight, particularly at the process level.
We use Gunicorn to serve our application, and like many in the Django world, we relied on the standard sync worker model. This model is simple and robust: each worker is a separate, isolated OS process, handling a single request at a time. With multiple workers within a [pod](ht…
At Rippling, we’re growing. Fast. That’s the best problem an engineer can have, but it comes with fascinating challenges. Our core platform is a powerful, feature-rich Django monolith with 17+ millions LoC. It’s what lets us build and ship value to our customers at an incredible pace. But as we’ve scaled, that monolith has started to show its weight, particularly at the process level.
We use Gunicorn to serve our application, and like many in the Django world, we relied on the standard sync worker model. This model is simple and robust: each worker is a separate, isolated OS process, handling a single request at a time. With multiple workers within a pod (a Kubernetes term for our application instance), we can handle multiple requests in parallel while maintaining clear memory boundaries between them. But for us, “simple” was becoming a major liability.
Here’s the story of how we tackled a deep, systemic performance and reliability issue, and in the process, cut our memory usage by over 70%, unlocked a 30% cost saving, and made our platform more resilient than ever. 🚀
The scaling challenge
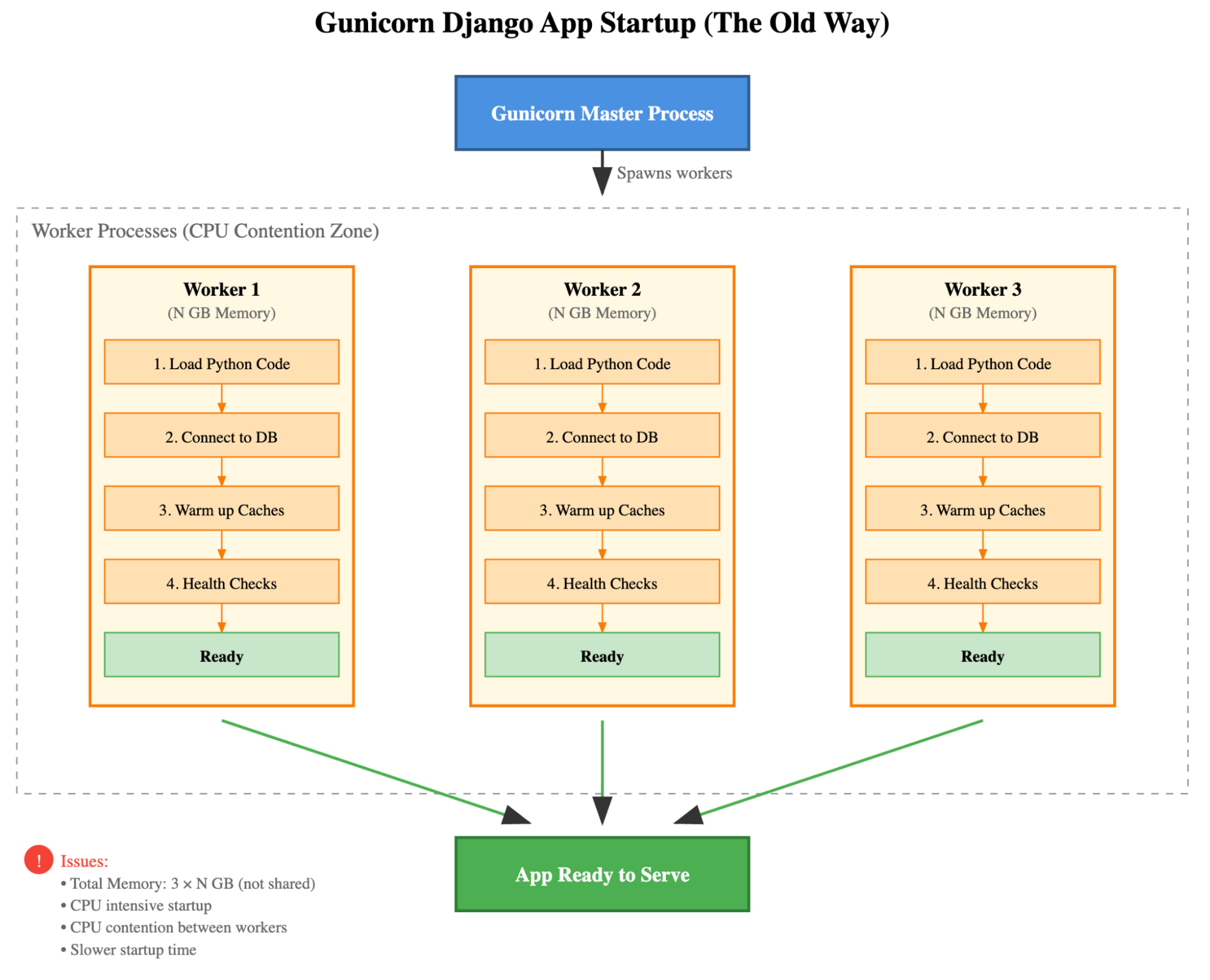
Our monolith was heavy. Each new worker process had to load the entire Django app, warm up gigabytes of in-memory caches, and initialize connections to everything: MongoDB (via mongoengine), Redis, Kafka, and a host of other services.
This created two critical problems:
Startup contention and cost: A new worker took 10s of seconds to start and was extremely CPU-heavy during that time. When a new pod deployed, all its workers started at once, competing for CPU. On a densely packed node, this “thundering herd” would cause CPU contention, slowing everyone down and sometimes pushing startup times past Kubernetes’ startup probe limits. Our expensive fix was to use more powerful Gen7 EC2 instances and custom pod schedulers just to survive deployments. 1.
Site reliability: The sync worker model has a flaw: a single, long-running (or hung) request will block that worker indefinitely. Gunicorn’s master process eventually times out and kills the stuck worker. For us, this meant the pod instantly lost capacity, and a new 10s-of-seconds, CPU-intensive startup process would kick off. In the face of a flood of bad requests, you can see the cascading failure. Workers would be killed off one by one, each slow to recover, until the entire service was brought down.
Here’s what that “thundering herd” looked like. Each worker did the same expensive work, duplicating memory and fighting for CPU.
We were paying a high price in both dollars and reliability for our startup process.
The “obvious” solution (and its ghosts)
The solution seemed obvious: Gunicorn’s –preload flag.
Instead of each worker loading the app, the Gunicorn master process loads the app once. It then uses the fork() system call to create its child workers. Thanks to the magic of Linux’s Copy-on-Write (CoW) memory, these workers all share the same physical, read-only memory pages as the master. A worker only gets a private copy of a memory page if it writes to it.
For an app like ours, where most of the memory is the app code itself, the potential savings were enormous. Our initial proof of concept (PoC) confirmed this: we saw an immediate 40%+ memory saving on a simple three-worker setup.
This was the holy grail. So why hadn’t we done it?
It turned out that other teams had tried and been forced to turn back. They were defeated by the ghosts that fork()leaves behind:
TCP Connections: Open network connections (like file descriptors) cannot survive a fork(). The child worker inherits a descriptor that points to a connection it doesn’t own, leading to corrupted data or, more likely, a completely dead connection. Our app, especially with pymongo and mongoengine, created a ton of these at startup.
1.
Threads: Background threads meet a similar fate. The child process inherits the memory of the thread, but not the actual running thread context. This is a recipe for deadlocks and zombie processes.
If we were going to make this work, we had to find and neutralize every single ghost connection and thread in our entire mono-repo before the fork.
Taming the monolith: A three-step plan
Given the size of our codebase, no single person knew where all these offenders were hiding. We needed a systematic approach.
Step 1: The detective work (monkey-patching)
We couldn’t grep our way to victory. So, we turned to one of Python’s most powerful (and dangerous) features, monkey-patching.
We wrote a debug patch file that, at the very beginning of the app’s startup, hijacked Python’s core socket and threading modules.
We replaced socket.socket.connect with our own function.
We replaced threading._newname (an internal function called on thread creation for unnamed threads) with our own.
These trap functions did two things:
Logged a full stack trace to a file in /tmp/.
1.
Called the original function so that the app would behave normally.
We ran our app’s startup process once and were instantly rewarded with a directory full of log files. This was our “hit list” — a complete manifest of every single line of code in our app that created a connection or a thread during startup. The ghosts were no longer invisible.
Step 2: The disconnect/reconnect pattern
Now that we knew what to clean up, we needed a way to do it at the right time. We built a simple hook system (using decorators) to manage the application lifecycle:
@post_application_load_hook: This decorator registers a function to be run by the master process after the app is fully loaded, but before forking.
@post_worker_init_hook: This decorator registers a function to be run by each worker process after it has been forked.
The flow became beautifully simple:
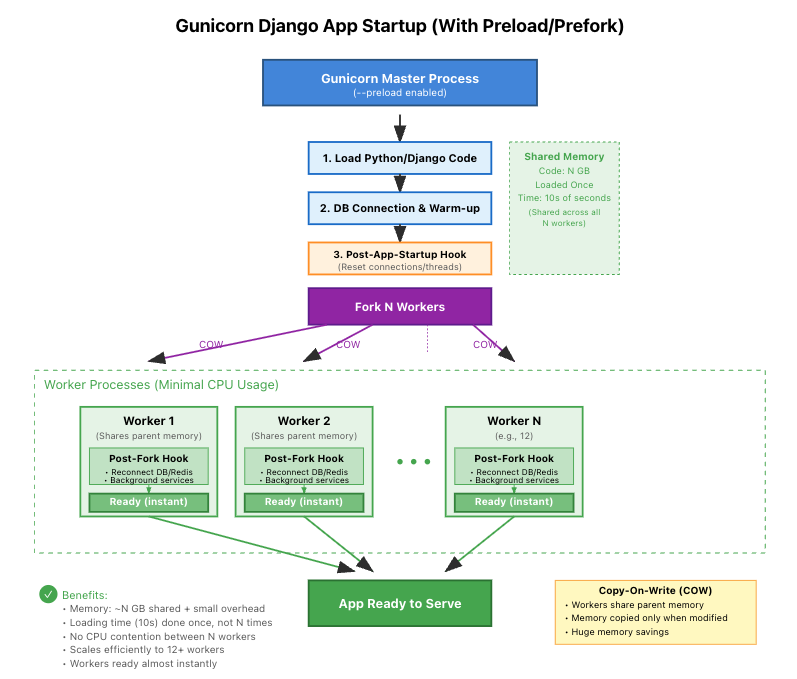
Master: Gunicorn master starts with --preload.
1.
Master: Loads the full Django app. Connections are created, and caches are warmed up. 1.
Master: We trigger a warmup call to the app to ensure all lazy-loaded modules are imported. 1.
Master: Runs all registered @post_application_load_hook functions. This is where we call redis.disconnect(), mongoengine.disconnect_all(), etc., cleaning up every connection we found in step 1.
1.
Master: Now in a “clean” state, the master forks() its child workers.
1.
Worker: Each worker starts (in a couple of seconds). 1.
Worker: Each worker runs all registered @post_worker_init_hook functions to establish new, fresh connections.
This new architecture eliminated all the duplicated work, as shown in our new startup flow:
Step 3: Handling the unhandle-able with proxies
This worked for most things, but we hit a wall with some anti-patterns baked deep into our ORM, like mongoengine queryset objects cached at the class level. We couldn’t easily refactor all of them.
For these, we invented fork-aware proxy objects.
Instead of caching the real query object, we’d patch the class to cache our proxy which is based on wrapt.ObjectProxy. This proxy was smart. In the master process, it would load the real object and shadow it. But it also knew its own process ID.
When a worker process (with a new PID) tried to use the cached object, the proxy would detect, “Hold on, I’m in a new process! My cached object’s connection is a ghost.” It would then automatically discard the dead object and re-initialize a new, live one on the fly. This allowed us to fix the unfixable without massive, high-risk refactors.
Guardrails: Making sure we stay clean
We had done it. But how could we prevent an engineer, months from now, from adding a new global client that creates a connection at startup and breaks everything?
The answer: Fail fast.
We built an iron-clad guardrail into our pre-fork loading process. Right before the fork step (after our cleanup hooks run), we have a function that checks for any active TCP connections or non-allowlisted threads. E.g.:
If that function finds anything — even one stray connection — it raises a RuntimeError and crashes the pod.
This check runs in CI and in production, making a regression impossible now. It’s not a “fix it later” problem; it’s a “your build is broken” problem. This is the only way to maintain a clean state at scale.
The payoff: 70%+ memory savings and a 30% drop in cost 💰
After rolling this out, the results were staggering and compounded quickly:
70%+ memory reduction: While our initial POC showed a 40% gain, as we scaled up our worker counts, the CoW benefits became even more pronounced. We’ve now realized over a 70% reduction in memory usage across the fleet.
30% cost savings (and counting): The massive memory savings meant we were no longer resource-constrained. We successfully downgraded our fleet from compute-optimized Gen7 instances to older, cheaper Gen6 hardware without any performance impact. This move alone translated into an immediate 30% reduction in our compute costs.
**Startup CPU contention: **Eliminated. What used to be N cores (one per worker) hammering the CPU is now just one core for the master’s startup.
Instant worker recovery: Workers now restart in seconds (down from 10s of seconds). The cascading failure scenario that kept us up at night? It’s gone.
3x-4x worker density: With memory and CPU usage so low, we could 3x or 4x the number of workers per pod for the same resource allocation. This massively increased our request throughput per pod.
Better reliability: We finally enabled Gunicorn’s max_requests setting. This automatically restarts workers after N requests, proactively mitigating any slow-burn memory leaks. Before, this was too risky. Now, it’s a free reliability win.
**One last trick: ****gc.freeze()**
One of our most interesting finds came at the very end. We found that calling gc.collect() and then gc.freeze() in the master process just before forking gave us another significant boost.
gc.freeze() moves all existing objects into a permanent generation and stops the garbage collector from scanning them. In a CoW world, this is a huge win. It means the GC in the worker processes won’t touch all that shared memory, which prevents those memory pages from being “copied on write.” This simple one-liner further reduced both memory and CPU overhead in the workers.
Our final tweak: jemalloc and fragmentation
Even after all these wins, we kept pushing. We noticed that over a long period, memory usage would still creep up. This wasn’t a leak in the traditional sense, but rather memory fragmentation, a classic problem for long-running CPython applications.
The default glibc memory allocator (malloc) is good, but not perfect. We found that switching our allocator to jemalloc, a battle-tested memory allocator designed for high-concurrency applications and much more aggressive about reducing fragmentation, made a significant difference.
The ultimate solution was a two-pronged attack:
**jemalloc**: We enabled it to achieve a more efficient, less fragmented memory layout from the start. This was surprisingly easy to implement; as long as the library is installed, it’s enabled by simply setting the LD_PRELOAD environment variable to "libjemalloc.so.2".
1.
Periodic restarts: We leveraged our new fast worker startup (thanks to pre-fork) and used Gunicorn’s max_requests to automatically restart workers.
This combination — jemalloc for efficiency and periodic restarts to fully wipe the slate clean — greatly mitigates fragmentation and gives us a rock-solid memory footprint indefinitely.
Beyond the savings: Reinvesting in performance
A 70%+ memory reduction doesn’t just translate to direct cost savings; it unlocks a strategic choice. Instead of simply cutting resources, we reinvested that saved memory to enhance performance and resilience.
By leveraging the memory savings from our pre-fork model, we were able to run much bigger pods (e.g., with 3x or 4x the worker capacity of the old pods) with the same resources (CPU and memory). This ultimately allowed us to double our total original worker count across the fleet. The larger, more consolidated pool of workers provides a crucial buffer, allowing the system to absorb random traffic spikes and slowness without impacting overall throughput.
This, however, brings up a natural question: why not go even bigger pods?
While we could technically run even larger pods (we’ve done so with 48 workers without issue), simply maximizing worker count per pod isn’t the optimal strategy. There’s a balance to strike. Excessively large pods can complicate horizontal scaling decisions, creating large gaps between scale-up steps and potentially leading to less efficient resource allocation across our fleet. We aim for a sweet spot that uses our memory savings for a significant performance boost, while maintaining practical, granular autoscaling.
Come solve hard problems with us
This project was more than just a performance optimization. It was a deep dive into the fundamentals of how Python, Gunicorn, and Linux work. It touched observability (monkey-patching), systems design (lifecycle hooks, proxies), and long-term maintainability (our “fail-fast” guardrails).
This is the kind of work we do at Rippling: tackling complex, high-stakes problems with methodical, deep engineering. If this is the kind of challenge that gets you excited, consider applying for a position on the engineering team.
Disclaimer
Rippling and its affiliates do not provide tax, accounting, or legal advice. This material has been prepared for informational purposes only, and is not intended to provide or be relied on for tax, accounting, or legal advice. You should consult your own tax, accounting, and legal advisors before engaging in any related activities or transactions.