TL;DR: The shift from massive embedding tables to generative retrieval with Semantic IDs is accelerating. YouTube’s new PLUM framework represents the next evolution, using an adapted LLM and enhanced ‘SID-v2’ to achieve a +4.96% Panel CTR lift for Shorts in live A/B tests. This deep dive explains how they did it.

October 10, 2025
|
6
min read
The last couple of years have seen a paradigm shift in how large-scale recommendation systems are being architected. Since seminal work like Rajput et al. (2023) introduced generative retrieval, followed by Google’s papers detailing the first Semantic IDs (SIDs), a wave of innovation has swe…
TL;DR: The shift from massive embedding tables to generative retrieval with Semantic IDs is accelerating. YouTube’s new PLUM framework represents the next evolution, using an adapted LLM and enhanced ‘SID-v2’ to achieve a +4.96% Panel CTR lift for Shorts in live A/B tests. This deep dive explains how they did it.
October 10, 2025
|
6
min read
The last couple of years have seen a paradigm shift in how large-scale recommendation systems are being architected. Since seminal work like Rajput et al. (2023) introduced generative retrieval, followed by Google’s papers detailing the first Semantic IDs (SIDs), a wave of innovation has swept through the industry. Leaders in personalization have been rapidly building on this foundation, moving away from the constraints of massive, static embedding tables and toward a more flexible, LLM-native future.
Now, a new paper from YouTube and Google DeepMind, “PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations” (He, Heldt, Hong et al., arXiv:2510.07784v1), provides a detailed look at the next generation of this technology. And the results are staggering: adding PLUM to their production candidate pool drove a +4.96% lift in Panel CTR for YouTube Shorts in live A/B tests.
This article provides a deep dive into the PLUM framework. We’ll break down how their “SID-v2” enhances existing concepts, the three-stage process they use to adapt powerful LLMs like Gemini for this task, and the comprehensive experimental results that validate this new approach at YouTube’s massive scale.
The PLUM Framework: A Three-Stage Approach
PLUM is a framework for adapting pre-trained LLMs to recommendation tasks. Its core innovation is reframing recommendation as a generative retrieval task: instead of fetching candidates from an index using dot-product similarity, the model autoregressively generates the IDs of the next items a user is likely to engage with. This is accomplished through a carefully designed three-stage process.
Stage 1: Item Tokenization with SID-v2 (The Next Evolution of Semantic IDs)
The foundation of this generative approach is the replacement of traditional, random hash-based item IDs with Semantic IDs (SIDs). An SID represents a single item (e.g., a YouTube video) as a sequence of discrete tokens, effectively turning the item corpus into a “language” an LLM can understand.
Building on the foundational concept of SIDs, PLUM introduces SID-v2, a significantly enhanced version created using a Residual-Quantized Variational AutoEncoder (RQ-VAE) with several key improvements:
-
Fused Multi-Modal Content Representation: Instead of relying on a single content source, SID-v2 ingests and fuses multiple heterogeneous embeddings (e.g., from video, audio, and text metadata). This creates a more comprehensive semantic representation before quantization.
-
Hierarchical Refinements in Quantization:
-
Multi-Resolution Codebooks: The RQ-VAE uses codebooks of decreasing size at deeper levels (e.g., 2048 entries at level 1, 1024 at level 2, etc.). This creates a more compact and efficient SID space, where initial tokens are highly discriminative and later tokens refine the representation with lower-entropy residuals.
-
Progressive Masking: During training, a random number of codebook levels are used, forcing the model to create a more robust and interpretable hierarchy.
-
RQ-VAE with Co-occurrence Contrastive Regularization: This is a critical enhancement. To bridge the gap between content similarity and user-perceived behavioral similarity, a contrastive loss term (L_con) is added to the RQ-VAE training objective. This loss encourages items that are frequently watched together in user sessions to have similar SID representations, directly injecting a powerful collaborative signal into the item tokenization process.
The overall training objective for the SID model combines reconstruction loss, quantization loss, and this new contrastive loss: L = L_recon + L_rq + L_con.

Illustration of the Semantic ID model. It takes two multi-modal video embeddings, encodes them, and compresses theresult into a quantized ID using a residual quantizer. This ID is trained to both reconstruct the original inputs and semantically cluster co-occurring videos using a contrastive loss.
Stage 2: Continued Pre-training (CPT)
With a vocabulary of SIDs established, the next step is to bridge the domain gap. PLUM takes a general-purpose pre-trained LLM (from the Gemini family) and subjects it to Continued Pre-training (CPT) on a massive, domain-specific corpus. This CPT stage aligns the LLM’s existing world knowledge with the new modality of SIDs and user behavior patterns. The training data is a 50/50 mixture of:
- User Behavior Data: Sequences of user watch history, interleaved with contextual features.
- Video Metadata Corpus: Textual data designed to create strong associations between SIDs and their corresponding text (titles, descriptions, topics, etc.).

Example schemas used in continued pre-training.
After CPT, the model is not only capable of predicting the next SID in a user sequence but also demonstrates in-context few-shot learning capabilities, able to generate coherent text from SID inputs.
Stage 3: Task-Specific Fine-tuning (SFT) for Generative Retrieval
The final stage specializes the CPT model for the end task of generative retrieval. Using a standard autoregressive, maximum-likelihood objective, the model is fine-tuned to predict the SID tokens of ground-truth clicked videos, given a rich input prompt of user context and history.
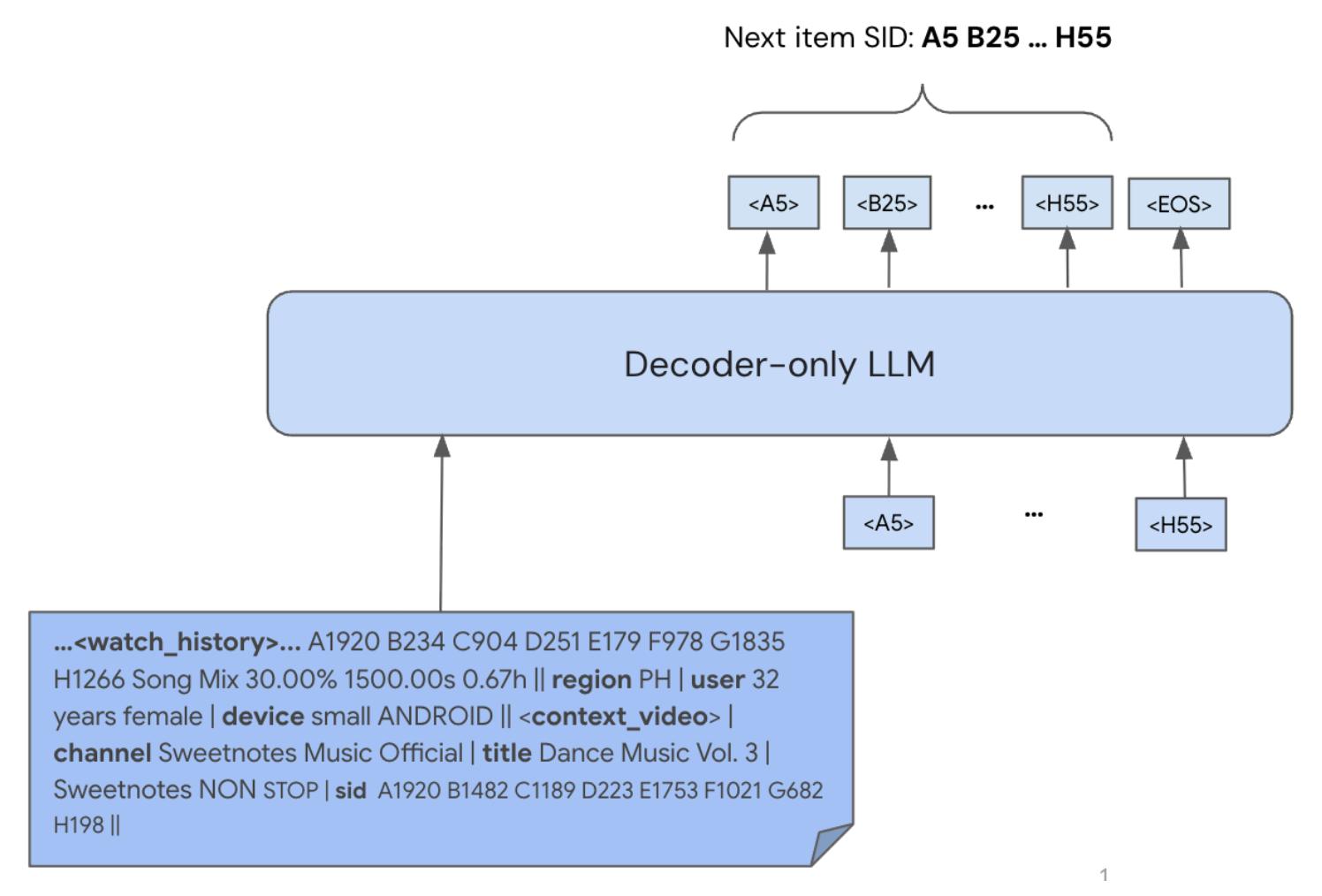
Illustration of Generative Retrieval for next video recommendation. The input prompt is a sequence of inter-leaved SID tokens, text and custom tokens for numerical features.
During inference, beam search is used to decode multiple candidate SID sequences, which are then mapped back to actual videos from YouTube’s billions-scale corpus.
The Results: Putting PLUM to the Test at YouTube Scale
The paper presents a comprehensive set of experiments comparing a 900M activated-parameter MoE PLUM model against a heavily-optimized production Transformer-based LEM.
- Offline Recommendation Quality: PLUM demonstrated a massive advantage in generalization and discovery.
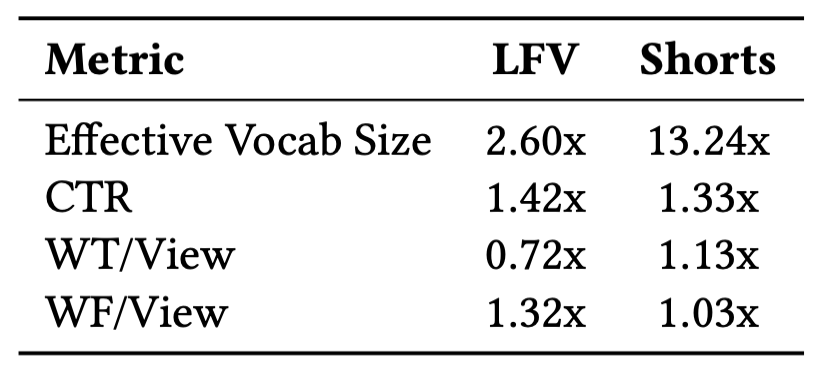
Comparison of recommendation quality: Each number is a ratio, dividing the metric for PLUM by that of LEM.
-
Effective Vocab Size: PLUM covered 95% of impressions with a 2.6x larger set of unique videos for Long-Form Video (LFV) and a staggering 13.24x larger set for Shorts. This indicates a far greater ability to recommend niche and long-tail content.
-
CTR: PLUM achieved a +42% higher CTR for LFV and +33% for Shorts.
-
Watch Time Metrics: While watch-time-per-view was lower for LFV, fraction-of-video-watched was significantly higher (+32%), suggesting better quality matches.
-
Live A/B Test Experiments: This is the definitive test. The PLUM model’s recommendations were added to the candidate pool alongside the existing production system (LEM+).

Comparison of engagement: Percentage change byadding PLUM compared to LEM+
The results showed significant lifts across key engagement metrics:
-
Panel CTR: +0.76% for LFV and a massive +4.96% for Shorts.
-
Views: +0.80% for LFV and +0.39% for Shorts. These are substantial gains for a mature, highly-optimized system like YouTube’s.
-
The Impact of Pre-training and CPT (Ablation Study): To validate their framework, the authors conducted a 2x2 ablation study, training four 900M MoE models with different initializations and training stages.
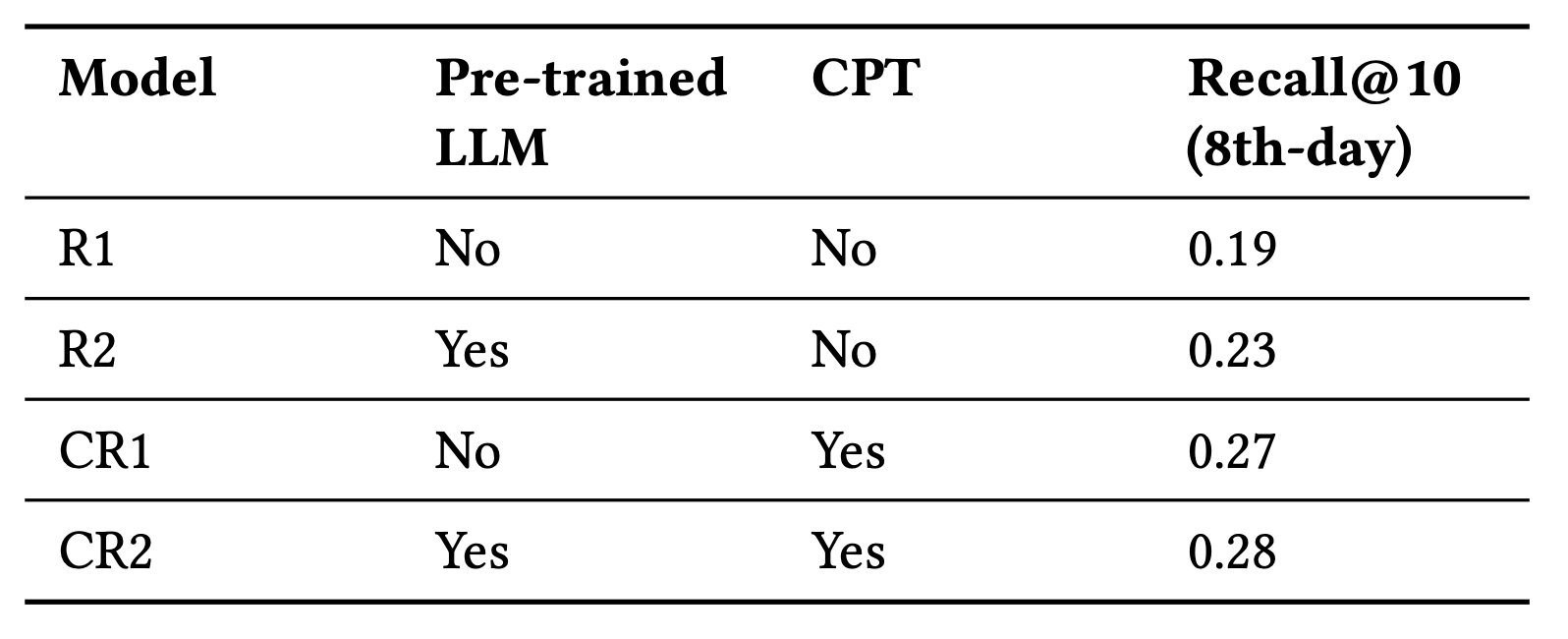
Comparison of engagement: Percentage change by adding PLUM compared to LEM+
The results unequivocally show the value of each stage:
- Random Init, No CPT (R1): Recall@10 of 0.19.
- LLM Init, No CPT (R2): Recall@10 of 0.23 (+21% lift from LLM pre-training).
- Random Init, With CPT (CR1): Recall@10 of 0.27 (+42% lift from CPT).
- LLM Init, With CPT (CR2 - Full PLUM): Recall@10 of 0.28 (+47% lift from the full framework). This clearly demonstrates that both initializing from a pre-trained LLM and performing Continued Pre-training are critical for achieving state-of-the-art performance. The CPT stage, in particular, provided the largest single improvement.
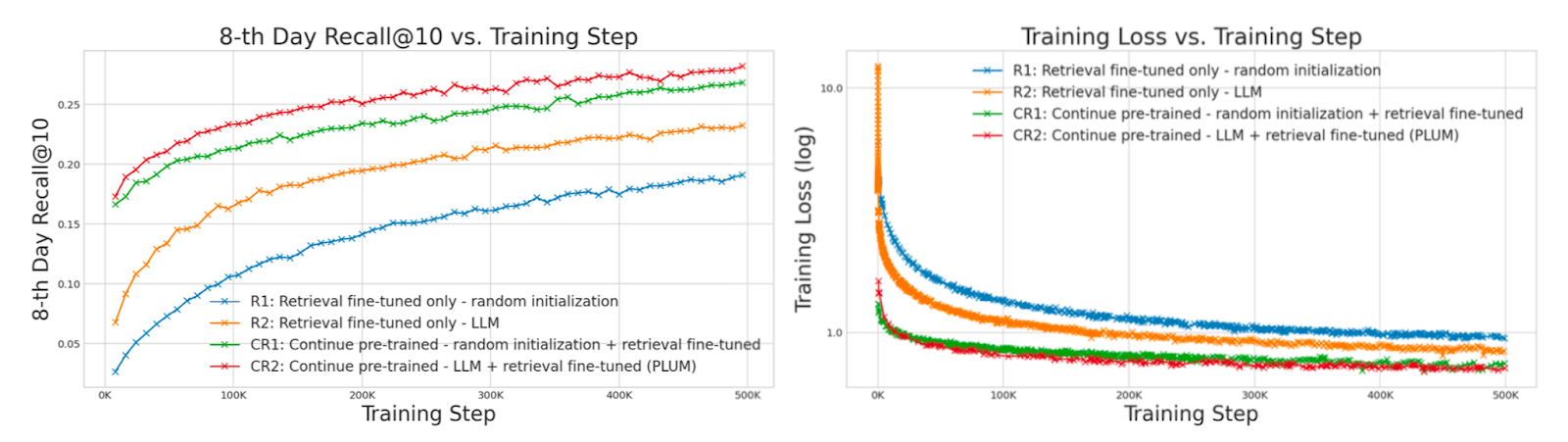
8-th Day Recall@10 and training loss vs retrieval SFT training step.
- Scaling Study: The paper also conducted a scaling study with MoE models ranging from 110M to 3B activated parameters. The results confirm that generative retrieval performance scales predictably with model size and compute, following a power-law relationship, similar to standard LLM scaling laws.
Key Takeaways
The PLUM paper is a landmark for industrial recommender systems. It provides a detailed, production-validated blueprint for this emerging new paradigm.
- Generative Retrieval is Production-Ready: The success at YouTube’s scale demonstrates that generative models can outperform highly optimized, traditional embedding-based retrieval systems on both offline and online business metrics.
- Semantic IDs are a Viable Successor to Embedding Tables: The SID-v2 approach, fusing multi-modal content with behavioral signals via contrastive learning, creates a powerful and scalable item representation layer.
- The Adapt-then-Finetune Framework is Effective: The three-stage process of (1) Item Tokenization, (2) Continued Pre-training, and (3) Task-Specific Fine-tuning is a robust method for bridging the domain gap and specializing LLMs for recommendation.
- Pre-training is a Force Multiplier: Both general-purpose LLM pre-training and domain-specific continued pre-training provide substantial performance lifts and improve sample efficiency.
PLUM’s results serve as a powerful confirmation of the architectural shift rippling through the entire personalization field. The era dominated by memorization-focused Large Embedding Models (LEMs) is giving way to a new paradigm centered on understanding via Semantic IDs. This trajectory suggests a future where the rigid separation between retrieval, ranking, and even user interaction layers begins to dissolve, enabling unified generative models that can retrieve candidates, rank them, and generate textual explanations for their choices. Of course, significant engineering challenges remain for this entire paradigm, from ensuring inventory grounding to prevent hallucination, to managing the freshness of SIDs in a dynamic catalog, and controlling the inference costs of these massive models. These hurdles highlight the growing importance of platforms and infrastructure designed to abstract away this complexity, enabling teams to experiment with and deploy state-of-the-art approaches like generative retrieval without rebuilding the entire stack from scratch.
Get up and running with one engineer in one sprint
Guaranteed lift within your first 30 days or your money back
100M+
Users and items
1000+
Queries per second
1B+
Requests