
Today we are releasing Terminal-Bench 2.0 and Harbor: a harder, better verified version of Terminal-Bench and a new package for evaluating and optimizing agents.
While building Terminal-Bench we kept hearing about the same set of problems from agent developers. Namely:
- Evaluating in containers is slow, how can we scale horizontally to thousands of containers in the cloud?
- How can we not only evaluate but also improve agents via SFT, RL, and prompt optimization?
- With so many frameworks for building agents and benchmarks for measuring them, how do we build tools that generalize across deployments?
Harbor addresses these problems and more by re-inventing the Terminal-Bench harness to support cloud-deplo…
Today we are releasing Terminal-Bench 2.0 and Harbor: a harder, better verified version of Terminal-Bench and a new package for evaluating and optimizing agents.
While building Terminal-Bench we kept hearing about the same set of problems from agent developers. Namely:
- Evaluating in containers is slow, how can we scale horizontally to thousands of containers in the cloud?
- How can we not only evaluate but also improve agents via SFT, RL, and prompt optimization?
- With so many frameworks for building agents and benchmarks for measuring them, how do we build tools that generalize across deployments?
Harbor addresses these problems and more by re-inventing the Terminal-Bench harness to support cloud-deployed containers, interfaces for rollouts for RL and SFT, and a simple interface that works with any agent that can be installed in a container.
Learn more by visiting harborframework.com.
Terminal-Bench 1.0 was a runaway success. Since its launch in May the benchmark has been used by virtually every frontier lab and has become the standard benchmark for agent evaluation. We’re tremendously grateful to our community of 1k Discord members and 100 contributors on Github.
However, we never intended for Terminal-Bench to stop with 1.0 (that is, after all, why we versioned it in the first place). As model and agent capabilities increase, it is essential that Terminal-Bench remain on the frontier.
Additionally, we weren’t satisfied with the level of verification in the original dataset. Our community discovered several problems with tasks from 1.0. For example, in download-youtube YouTube’s constantly changing anti-bot protections meant that a solution that worked one day might not work the next.
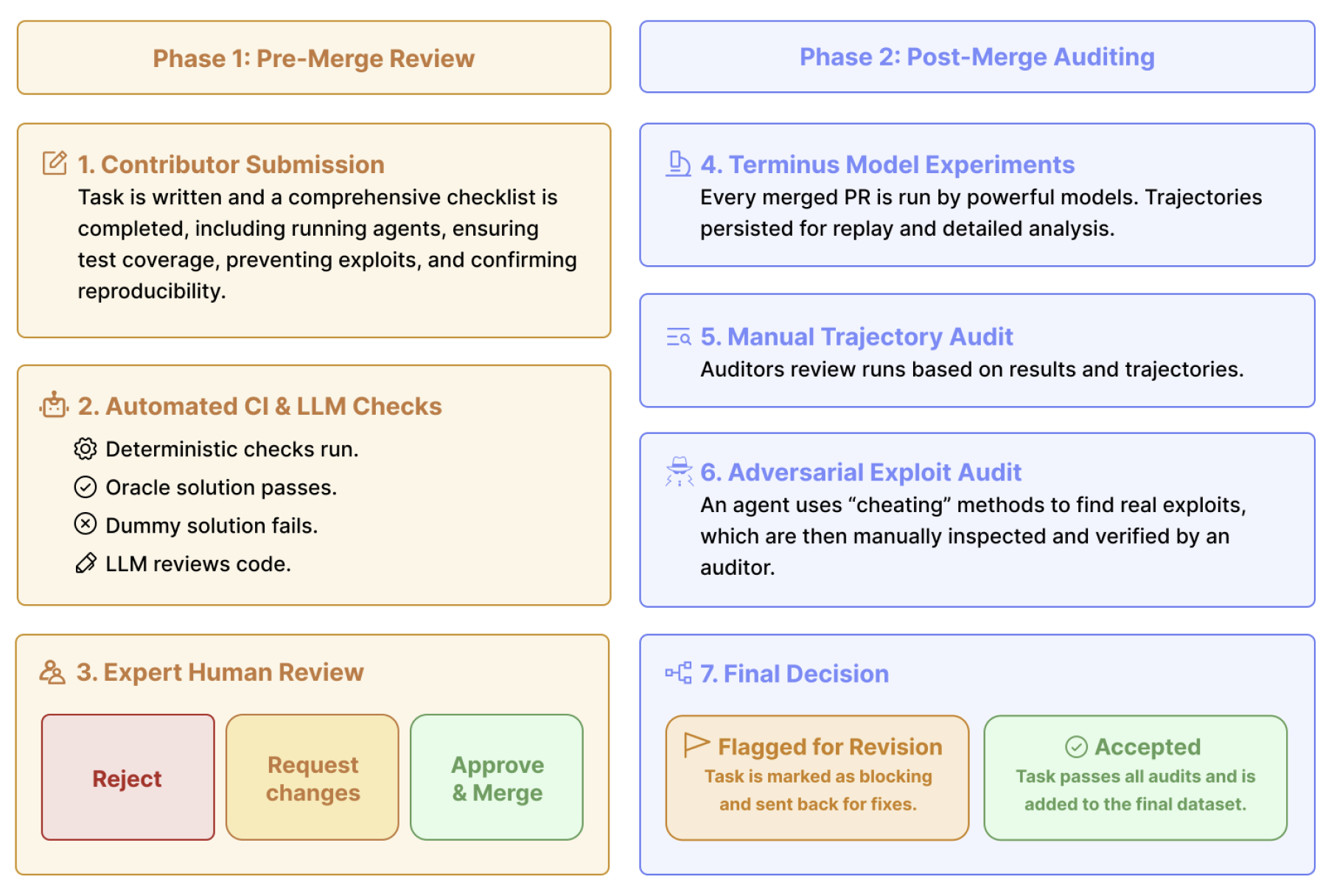
Substantial manual and LM-assisted verification went into the creation of each task in Terminal-Bench 2.0.
To address these problems, we are releasing Terminal-Bench 2.0. Terminal-Bench 2.0 is a harder, better verified version Terminal-Bench. We conducted substantial manual and LM-assisted verification of the dataset to ensure that the tasks were of the highest possible quality. Several labs and data vendors have commented that these are some of the highest quality environments they have seen.
Try Terminal-Bench 2.0 today by installing Harbor.