Simplify, Secure, and Scale Your Infrastructure
As organizations scale Kubernetes and hybrid infrastructures, many are realizing that more tools don’t mean better security. A recent Microsoft report found that organizations with 16+ point solutions see 2.8x more data security incidents than those with fewer tools. Yet platform teams are still expected to deliver resilience and performance across containers, VMs, and bare metal, often while juggling fragmented tools that introduce risk, downtime, and complexity.
The Fall 2025 release of Calico Enterprise and Calico Cloud cuts through that complexity. Its new features are designed to make your infrastructure more resilient, performant, and observable—right out of the box. From disaster recovery automation to modern data plane…
Simplify, Secure, and Scale Your Infrastructure
As organizations scale Kubernetes and hybrid infrastructures, many are realizing that more tools don’t mean better security. A recent Microsoft report found that organizations with 16+ point solutions see 2.8x more data security incidents than those with fewer tools. Yet platform teams are still expected to deliver resilience and performance across containers, VMs, and bare metal, often while juggling fragmented tools that introduce risk, downtime, and complexity.
The Fall 2025 release of Calico Enterprise and Calico Cloud cuts through that complexity. Its new features are designed to make your infrastructure more resilient, performant, and observable—right out of the box. From disaster recovery automation to modern data plane support and application traffic handling, these updates empower platform engineers to simplify operations while meeting strict reliability requirements.
The new features in this release can be grouped into two main categories:
1. Resilient, High-Performance Networking and Improved Quality of Service:
-
High availability (HA) management planes for VM and bare metal hosts – Increases resiliency and helps reduce downtime.
-
The official release (GA) of the nftables dataplane -Delivers faster and more scalable rule-processing than iptables.
-
**Maglev-Based Session Affinity – **Maintain stable network traffic flow during failures or scaling.
These new capabilities strengthen uptime, performance, and traffic reliability across dynamic Kubernetes infrastructure.
2. Unified Visibility Across All Kubernetes Traffic:
-
**Quality of Service (QoS) controls with priority markings – **Ensure latency-sensitive applications get priority treatment, keeping critical workloads responsive.
-
Integrated dashboards for the Calico Ingress Gateway -Teams gain out-of-the-box insight into ingress traffic flows, latency, and errors without relying on fragmented monitoring tools.
By unifying observability in one platform, Calico removes blind spots, streamlines troubleshooting, and makes it easier to optimize performance and maintain reliability across complex Kubernetes environments
Resilient, High-Performance Networking
High Availability (HA) Management Plane for VMs and Bare Metal Hosts Running Calico
Enterprises running Calico outside of Kubernetes, on VM and bare metal hosts, often face operational challenges when ensuring business continuity. Financial customers and other customers running critical applications need to maintain dual Kubernetes clusters with manual failover processes to provide disaster recovery (DR). This approach is cumbersome, error-prone, and introduces risks such as inconsistent certificates and downtime when operators need to push policy changes or maintain log forwarding pipelines.
With the Fall 2025 release, Calico Enterprise and Calico Cloud deliver built-in high availability (HA) for management planes that support VMs and bare metal hosts. Calico now unifies all API endpoints under a single address, rather than requiring operators to configure and switch between multiple endpoints during a failure. If a management plane becomes unavailable, traffic is automatically redirected to a healthy cluster. This ensures security policies remain enforced and log forwarding continues, so operations run smoothly without disruption or manual intervention.
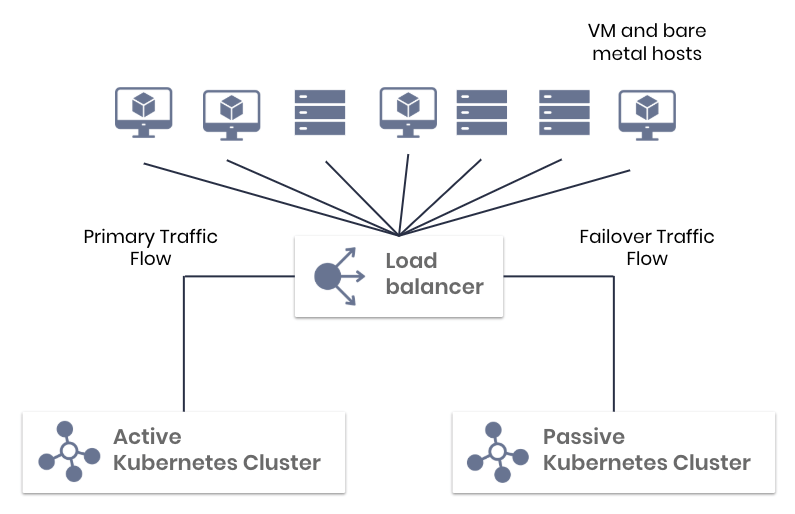 Automated failure recovery. Failure of the management plane is detected and VM or bare metal host traffic is automatically diverted to a passive Kubernetes cluster. Traffic is diverted back again once the active cluster is healthy again.
Automated failure recovery. Failure of the management plane is detected and VM or bare metal host traffic is automatically diverted to a passive Kubernetes cluster. Traffic is diverted back again once the active cluster is healthy again.
Key Benefits of the HA Management Plane for VMs and Bare Metal Hosts:
- Automated Failover: Traffic is seamlessly redirected to a healthy management plane, ensuring zero downtime.
- Simplified Disaster Recovery: Automates critical DR processes, minimizing manual intervention and reducing risk.
- Uninterrupted Security and Compliance: Ensures continuous network policy enforcement and log forwarding, even during cluster failures.
How This Feature Ensures Continuous Operations
Scenario: A Financial Services Company Facing Downtime
Imagine a financial services company running Calico on thousands of VMs and bare metal hosts. Before the availability of a high availability (HA) Kubernetes management plane, if the primary management cluster went down for maintenance or due to an outage, operators would completely lose their ability to interact with those hosts. They could not push emergency policy changes, and they would stop receiving critical flow logs needed for compliance and auditing. This lack of policy and observability control over thousands of critical workloads was simply unacceptable.
Solution: Seamless Failover for Continuous Operations
With this new HA management plane functionality, if the primary cluster fails, communication is automatically redirected from workloads to a healthy backup cluster. This ensures the operations team retains full control and visibility, allowing them to continue enforcing security policies and collecting vital log data across all VM and bare metal hosts with zero operational disruption.
Official Release (GA) of the Nftables data plane for Calico
As Linux distributions increasingly adopt nftables as the successor to iptables, enterprises face challenges maintaining performance and consistency with the legacy stack. Iptables suffers from limitations such as inefficient rule processing, verbose syntax, and non-atomic updates, all of which can create operational complexity and scalability bottlenecks for production environments.
With the Fall 2025 release, Calico makes the nftables data plane generally available (GA). Nftables provides a modern, unified way to filter and classify network traffic in the Linux kernel. It supports advanced features like sets, maps, and atomic updates, and works across different protocol families, like IPv4, IPv6, and ARP with a unified rule syntax. For Calico users, this means faster traffic rule processing than iptables, easier management of large network policies, and a cleaner, more extensible configuration model.
Key Benefits of the Nftables data plane:
- Faster, More Scalable Rule Processing: Improves performance using sets and maps.
- Unified Syntax Across Protocols: Simplifies policy management across IPv4, IPv6, and ARP.
- Future-Proof Extensibility: Supports advanced and emerging networking use cases.
- Standardized Linux Kernel Component: Leverages a modern data plane integrated directly into the Linux kernel.
Support for the Maglev Load Balancing in Calico for More Reliable Session Connectivity
In Kubernetes environments that use kube-proxy for load balancing, keeping sessions stable can be a challenge. When nodes are updated or fail, existing connections may be interrupted, leading to user-visible glitches. The same issues can happen during scaling events, when Kubernetes adds or removes nodes, since traffic may be re-routed to different endpoints, breaking active connections with TCP resets. These disruptions can be especially problematic for enterprise-grade applications that demand high availability and a seamless user experience.
Calico now supports the Maglev hashing algorithm for load balancing to improve session affinity (keeping all the traffic from the same user or session going to the same backend server) and resilience in software-based load balancing. Maglev uses a hash method called “consistent hashing” to keep traffic flows stable, even when nodes fail or are being scaled up and down. This reduces connection resets and dropped sessions, leading to smoother operations and more reliable applications.
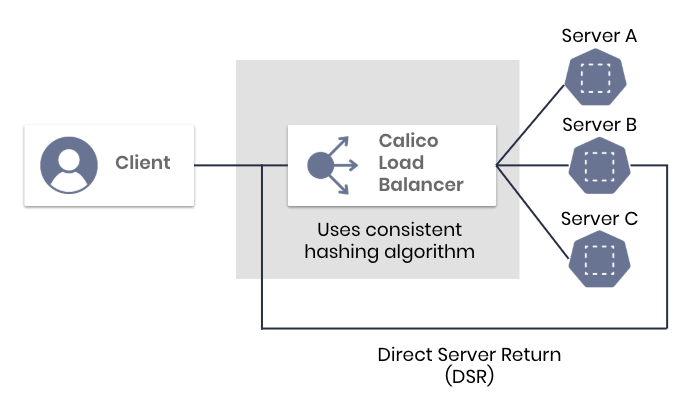 This diagram illustrates the two primary traffic flows in Maglev load balancing using the Calico Load Balancer: the ingress request flow using consistent hashing, and the efficient egress response flow that utilizes Direct Server Return (DSR) to improve performance.
This diagram illustrates the two primary traffic flows in Maglev load balancing using the Calico Load Balancer: the ingress request flow using consistent hashing, and the efficient egress response flow that utilizes Direct Server Return (DSR) to improve performance.
Key Benefits of Maglev Load Balancing Support:
- Maintains session continuity during node updates and failures
- Prevents connection resets when nodes are scaling up or down
- Improves reliability and user experience for enterprise applications
How This Feature Ensures Stable Connections During Node Events
Scenario: Online Payment Processing
Imagine a customer making an online payment. Without Maglev, if the node handling that transaction is updated or fails mid-process, the connection could reset, potentially interrupting the payment and forcing the user to restart. For high-traffic payment systems, these disruptions can frustrate users and even result in lost revenue or damaged trust.
Solution: Stable Connections Through Maglev Session Affinity
With Maglev, traffic from that transaction stays consistently routed to the same backend, even during node updates or node scaling events. This keeps the payment session stable and ensures the transaction completes smoothly and reliably, no matter what’s happening behind the scenes.
Simplified Operations and Visibility
Support for Priority Markings in QoS Policies
Latency-sensitive applications, like fraud monitoring systems, require strict traffic prioritization to ensure real-time performance. Without differentiated traffic handling, critical workloads can suffer from network congestion caused by competing jobs such as data replication, resulting in higher latency and degraded application outcomes
With the Fall 2025 release, Calico makes it easier to prioritize important traffic by adding support for Differentiated Services Code Point (DSCP) markings in its Quality of Service (QoS) policies. In plain terms, platform teams can now tell the network which traffic matters most, whether it’s coming from Kubernetes pods, from workloads running outside of Kubernetes with the Calico agent.
These DSCP QoS markings also address the noisy neighbor problem by keeping resource-hungry workloads from impacting others. Calico’s use of DSCP markings and network traffic controls help ensure critical applications maintain consistent high-quality performance across shared environments..
This means critical, latency-sensitive applications (like fraud detection or video calls) can automatically get higher priority across the network. And because it’s handled directly in Calico policies, teams no longer have to rely on manual switch/router settings or complicated, error-prone QoS configurations managed by separate networking teams
DSCP: When data moves across a network it competes for space. DSCP, or Differentiated Services Code Point, is a marker or label added to the header of each IP packet (a 6-bit value) that tells the network how important it is. A video call packet might carry a high-priority label so it gets through without delays, while a large file download can have a lower priority label. By marking traffic with priority labels, DSCP helps ensure that time-sensitive applications, like fraud detection and financial services applications always get the smooth, reliable performance they need.
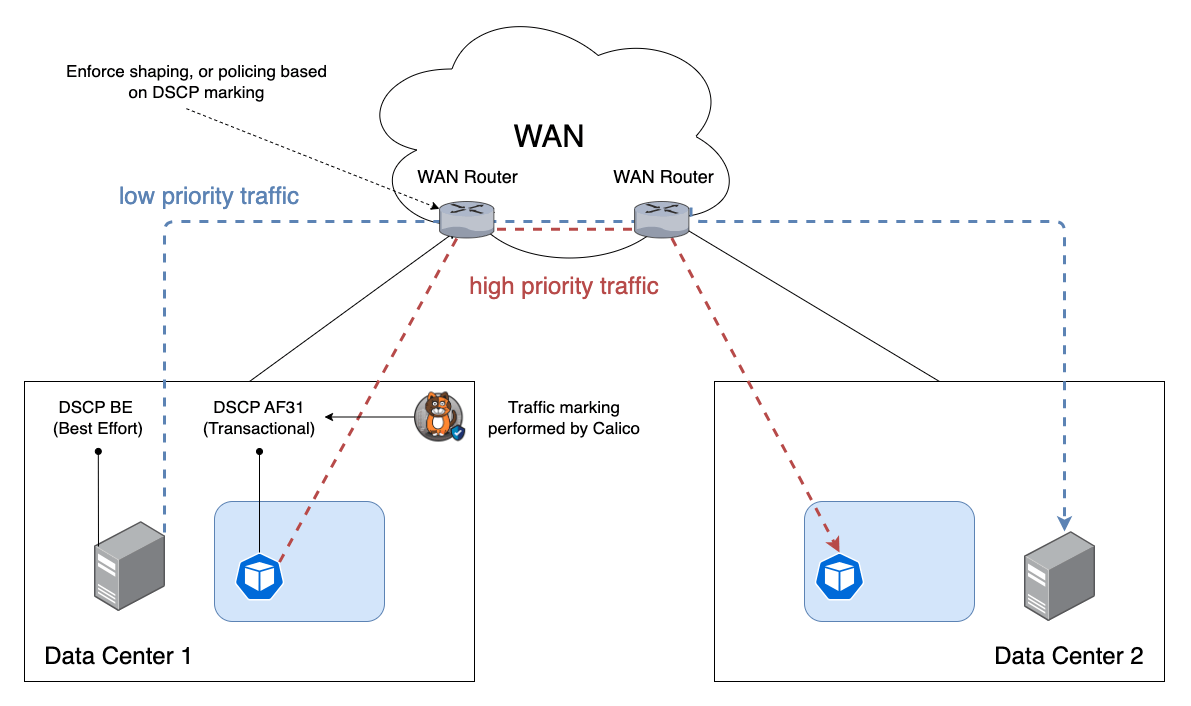 Calico QoS policies apply DSCP markings to prioritize latency-sensitive traffic, ensuring that critical applications receive consistent, high-priority treatment. Here you see an app with a higher priority DSCP label getting prioritized over traffic with a lower priority DSCP label.
Calico QoS policies apply DSCP markings to prioritize latency-sensitive traffic, ensuring that critical applications receive consistent, high-priority treatment. Here you see an app with a higher priority DSCP label getting prioritized over traffic with a lower priority DSCP label.
Key Benefits of DSCP Support in Calico QoS Policies:
- Priority for Critical Traffic: Ensures latency-sensitive workloads receive top network priority.
- Unified QoS Control: Delivers consistent traffic management across all environments.
- Simplified Operations: Integrates QoS directly into Calico network policies.
- Consistent Performance: Maintains reliable prioritization across multi-datacenter deployments.
How This Feature Delivers Reliable Performance for Latency-Sensitive Workloads
Scenario: Prioritizing Critical Traffic in a Banking Environment Imagine a bank that runs a fraud detection service alongside its regular data processing jobs. During peak hours, the network gets busy with large data processing tasks that can slow everything else down. Without traffic prioritization, fraud alerts might be delayed by a few seconds, which could cause serious issues.
Solution: Ensuring Consistent Performance with DSCP Support With DSCP support in Calico, the bank can mark fraud detection traffic as “high priority,” while background data replication is marked lower. This ensures that fraud detection packets always move through the network first, keeping critical applications fast, responsive, and reliable, even under heavy network loads.
Dashboards and Observability for Calico Ingress Gateway
Organizations adopting the Kubernetes Gateway API often encounter a challenge: observability from their ingress gateway isn’t integrated with the rest of their Kubernetes networking and network security stack. Without a unified view of network activity, teams are forced to stitch together metrics, logs, and traces from different observability tools, slowing responses, complicating troubleshooting, and leaving blind spots in visibility.
With the Fall 2025 release, Calico Enterprise provides integrated dashboards and observability for the Calico Ingress Gateway. Curated dashboards with out-of-the-box metrics and built-in logs give platform and application teams a single, unified source of truth. More importantly, ingress traffic insights can now be viewed alongside east-west and egress traffic flows, giving teams a holistic view of all Kubernetes networking traffic activity. This unified perspective helps operators spot traffic issues quickly, accelerates troubleshooting, helps optimize performance, and aids in eliminating gaps that arise when observability tools are fragmented.
Key ingress gateway dashboard capabilities include:
Gateway & Route Health – Monitor the readiness of Gateways, GatewayClasses, and Routes, with clear indicators for listener status, attachment success, and reconciliation failures.
Error Response Visibility – Track error response rates across routes and services, detect gateway misconfigurations or policy mis-attachments, and distinguish between gateway-level failures (TLS errors, config errors) versus backend failures.
Latency Metrics – Measure and visualize latency at the namespace, service, and route level. Quickly identify where slowdowns occur and isolate whether they stem from the gateway layer, upstream connections, or backend services.
Backend Traffic Assurance – Confirm that backends are receiving traffic as expected, and verify that traffic distribution aligns with routing policies.
High-Error Route Detection – Identify routes experiencing elevated error rates, with the ability to filter and sort by error code, making it easy to troubleshoot failures and prioritize fixes.
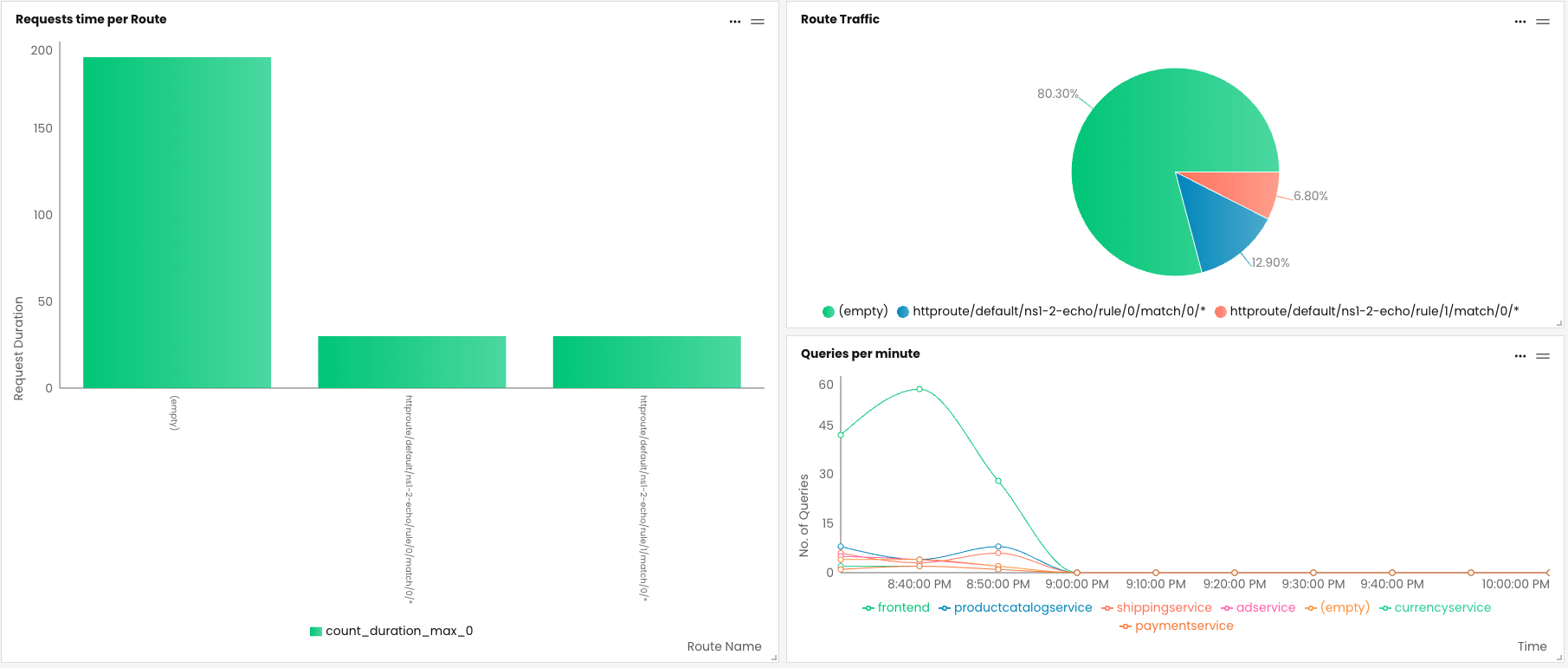 This sample Ingress Gateway dashboard shows which routes receive the highest share of traffic and is useful for troubleshooting/optimizing load balancing. You can also identify low-traffic routes for cleanup, optimization, and investigation.
This sample Ingress Gateway dashboard shows which routes receive the highest share of traffic and is useful for troubleshooting/optimizing load balancing. You can also identify low-traffic routes for cleanup, optimization, and investigation.
Key Benefits of the Calico Ingress Gateway Dashboards
- Unified, out-of-the-box observability for Calico Ingress Gateway
- Comprehensive Insights: Tracks gateway health, errors, and latency in real time.
- Full Traffic Visibility: Combines ingress, egress, and east-west data in one view.
- Simplified Troubleshooting: Reduces tool fragmentation and accelerates issue resolution.
Get Started with Calico Fall 2025
The Fall 2025 release of Calico Enterprise and Calico Cloud delivers powerful new capabilities that strengthen resilience, improve performance, and simplify operations across Kubernetes, VMs, and bare metal environments. Highlights include high availability management planes for VM and bare metal hosts, the general availability of the modern nftables data plane, and Maglev load balancing to help keep connections stable during node failures or scaling. Teams also gain operational simplicity through DSCP priority markings in QoS policies and integrated dashboards for the Calico Ingress Gateway, making it easier to prioritize critical workloads and achieve unified observability. Together, these enhancements give platform engineers the tools to scale production environments with confidence, efficiency, and reliability.
What’s Next:
👉** Learn More About** Calico Enterprise & Calico Cloud
👉 **See Calico in Action: **Request a personalized demo to experience the latest innovations in resilient networking, traffic visibility, and simplified operations.