Motivations
Retrieval Augmented Generation (RAG) is one of those medium article AI slop topics that people seem to love to generate. ‘5 Ways to Improve your RAG B2B SaaS Pipeline Optimization Strategies - Number 3 Will Surprise You!’. There is a lot of talking about this topic, but very few actual implementation retrospectives.
The TrueState platform provides an AI data scientist that utilises a variety of different RAG strategies under the hood - from understanding dataset semantics (e.g., interpreting column names and metadata) to retrieving and incorporating relevant supporting documents. We have been close to the frontline for LLM retrieval strategies since the beginning, and have been able to successfully implement and modernize these for our users.
This article will…
Motivations
Retrieval Augmented Generation (RAG) is one of those medium article AI slop topics that people seem to love to generate. ‘5 Ways to Improve your RAG B2B SaaS Pipeline Optimization Strategies - Number 3 Will Surprise You!’. There is a lot of talking about this topic, but very few actual implementation retrospectives.
The TrueState platform provides an AI data scientist that utilises a variety of different RAG strategies under the hood - from understanding dataset semantics (e.g., interpreting column names and metadata) to retrieving and incorporating relevant supporting documents. We have been close to the frontline for LLM retrieval strategies since the beginning, and have been able to successfully implement and modernize these for our users.
This article will present an overview of the current challenges with implementing RAG solutions, dating to the end of November 2025, including examples of where we had success and where we failed.
Direct Context Injection
The baseline strategy for context management should be to just put all required context directly in the LLM context window. Frontier LLMs are incredible at managing and navigating large volumes of structured context. This is the easiest and simplest engineering solution and should be used until it stops working.
There is an anthropomorphism mistake that occurs where people want to ‘curate’ the provided context so that the LLM can ‘focus’ on the important documents. This is not in line with our practical experience with building these systems. Provided the context is appropriately separated (we use XML-style tags, but this is an open research question) the LLM typically eats up as much context as you can give it.
Direct Context Injection has 3 issues. The first being performance, as providing more tokens causes the bot response to slow down. The second being hitting the token context window for the model - eventually you just can’t put any more content into the chat because you have hit the length limit. The third issue is the cost - LLM providers bill per token, and if you have 1 million tokens of context at $1.50/million tokens, each message is prohibitively expensive.
Once we hit one of these blockers, we need to start exploring other options for curating context. The rest of this article will explain how and why you might want to start approaching these solutions.
Embedding Search
Many of the explanations for embedding search talk about vectors and cosine similarity and high dimensional spaces. But the easiest way to think of it is as a similarity score. If I give you 2 sentences and ask how similar they are, we can measure what a bot thinks using a simple 0 to 1 score. For example, the two phrases ‘gym’ and ‘fitness center’ will be much more similar than ‘gym’ and ‘garage’, and we can measure this similarity with a number. The ability to quantitatively determine text similarity opens the door to building a ranking system, and ultimately an index.
A great game to play to get a sense of similarity is Semantle. The game involves trying to guess a secret word using only the similarity score of your guess word. https://semantle.com/
The similarity concept then extends beyond words, to full sentences. We can compare the sentence ‘This is a happy person’, to the sentence ‘This is a very happy person’ or ‘This is a happy dog’, or ‘Today is a sunny day’. The below example shows how each of these sentences compare in similarity to the original sentence.
"inputs": {
"source_sentence": "That is a happy person",
"sentences": [
"That is a happy dog", # 0.853
"That is a very happy person", # 0.981
"Today is a sunny day" # 0.655
]
} # Source: Huggingface docs
This concept can be extended once again, to take embeddings of large corpuses of text, such as forum posts, documentation manuals, or product descriptions. We can start with a keyword search, such as ‘sleeping bag’, and compare it to a set of product descriptions to determine which one is the closest, which might not mention either word sleeping or bag. ‘Four-season down mummy quilt’ is essentially a sleeping bag, but uses a vastly different set of words, and yet it will have high similarity.
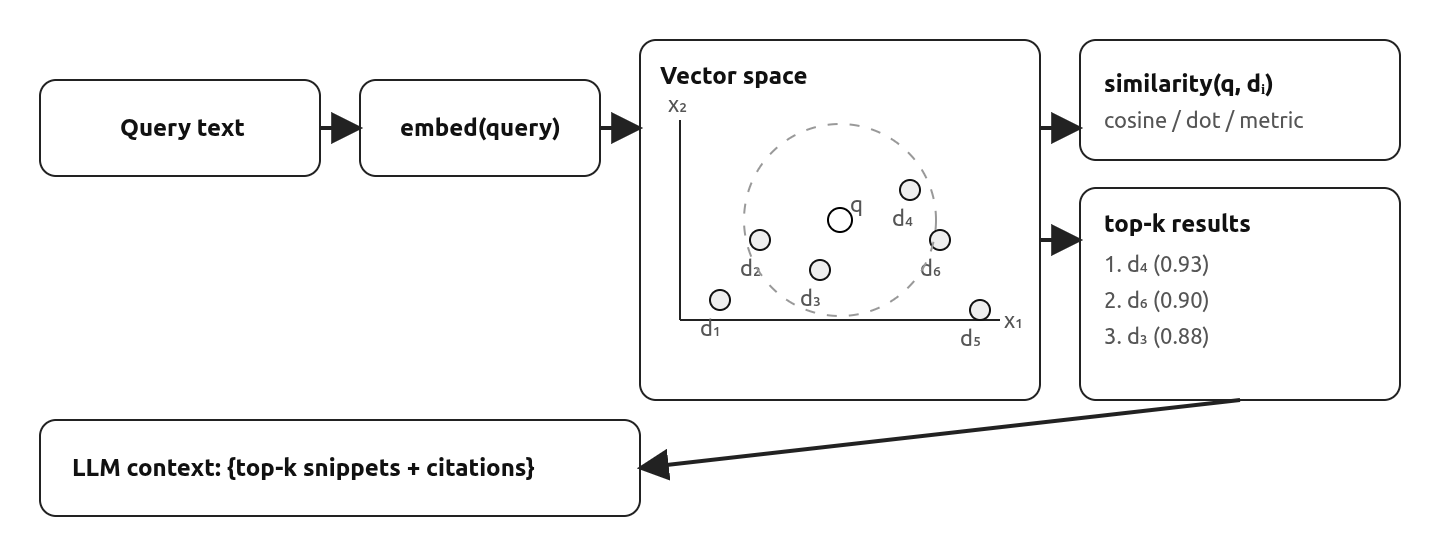
Once the documents get too large, the concept of ‘similarity’ becomes a bit nebulous and not useful. If I have multiple long technical manuals about a product (for example an installation guide, a maintenance guide, and a spec sheet), it is difficult to use a similarity score to match a search query to the appropriate document. We then need to evolve our strategy.
Chunking
Chunking involves breaking down a single document into multiple chunks, with which we can generate a similarity score for each. Chunking is a solution that exists for 2 reasons: the first being that documents can be too large to fit in the context window (particularly for early models), and the second being that the documents are being searched by the user and they will likely want to know the relevant page, rather than the relevant chapter.
Chunking documents is a hazard, because it risks splitting up concepts that rely on each other. Technical documents are typically structured to be referential across chapters, and often cannot be broken up into smaller components without losing meaning. An embedding search might return a chapter that is dependent on or in reference to guidance in a different chapter which was not returned.
Chunking is less useful now, due to increased context windows, and the use of Agentic Retrieval to drill down into documents. I am unsure whether the concept of chunking will survive in the future at all.
Hybrid Search
Hybrid search involves a combination of traditional keyword search with the similarity score. This concept exists because early embedding search models struggled with keywords and item codes. For example, I might perform an embedding search for a ‘Dell precision 3580 laptop’, however the search would perform poorly and return laptops more generally, as the LLMs were not clever enough to match the ‘3580’ keyword. A traditional keyword search would perform well here - which results in very perplexed users.
Hybrid search involves combining these two approaches with a weighted balance, determined using a heuristic. This solved many early search problems with keywords, as we ended up with a best-of-both worlds type solution.
One of the most recent model drops was Google’s gemini-embedding-001. This model dominated the embedding search leaderboards (MTEB) and largely solved the problem of keyword matching. This new model is able to handle text and number strings significantly better, and solved our issues in this area. It remains to be seen whether hybrid search will be necessary in the future or whether models will be good enough to do this on their own. I would be interested in seeing some benchmarks for long UUID-style text string matching with an embedding model, where they may still struggle.
Rerankers
A reranker is an additional LLM that takes the results of an embedding search, and re-evaluates them to ensure they align more closely with the user’s intent. It attempts to solve the problem of embedding search retrieving related documents, but not necessarily documents that contain the answer to a question. It is effectively a small, low-latency, high context window agent that curates the search results for delivery to an agent.
These are a newer concept, and we have not implemented these at TrueState, as our agentic embedding search described below largely solves this niche. I am interested to see how this technology develops, and how it ends up relating to Agentic Retrieval.
Examples
An example we built is for a company search use case. We have a set of approximately 1m company descriptions, including other pieces of metadata like their website and location and company size. The description was a short text field of varying length and structure.
Keyword search does not work in this use case. If we do a search for ‘gyms’ then we end up missing various companies that describe themselves as ‘fitness centers’. If we search for ‘compostable packaging’ then we miss anything adjacent like ‘sustainable containers’ or ‘biodegradable materials’.
We built an embedding search capability on the description field, which allowed the client to search through their dataset using the embedding search.
From here, we also were able to provide this embedding search tool to a chatbot. When provided with instructions for how to use the search tool, it could perform a search and answer using records from the database. This grounded its responses in a verified source of truth.
Agentic Retrieval
 The experimental version of Gemini 2.0 Flash was released at the end of 2024, to little fanfare. OpenAI was doing all sorts of weird things with their new reasoning models and the Gemini model was swept under the rug a bit. But when I was reading Google’s blog post, I saw they mentioned it had a 1 million token context window - about 8 times larger than the GPT-4o context window. If you are building a simple chatbot you couldn’t care less about this number - when would your users reach ~500 pages of text in a single conversation? But a 1 million token context blew the doors off the SOTA retrieval paradigms - all of a sudden we can pull in entire technical manuals, extensive reports, and pages and pages of data and the bot is able to process all of this.
The experimental version of Gemini 2.0 Flash was released at the end of 2024, to little fanfare. OpenAI was doing all sorts of weird things with their new reasoning models and the Gemini model was swept under the rug a bit. But when I was reading Google’s blog post, I saw they mentioned it had a 1 million token context window - about 8 times larger than the GPT-4o context window. If you are building a simple chatbot you couldn’t care less about this number - when would your users reach ~500 pages of text in a single conversation? But a 1 million token context blew the doors off the SOTA retrieval paradigms - all of a sudden we can pull in entire technical manuals, extensive reports, and pages and pages of data and the bot is able to process all of this.
The new models also became significantly stronger at tool calling. First-class APIs were developed to be able to specify which tool to call and how (MCP). This meant we could be significantly more creative in the tools that we build, and that the LLMs were more resilient to poorly specced tool instructions.
Cursor and Claude Code exploded off the back of this new paradigm. Early coding assistant tools required specifying exactly which files were included in the model context, which was a necessary strategy to manage context lengths. This is an example of chunking (based on file) and would often fail because function definitions or codebase paradigms were not understood by the LLM. But once context lengths improved, the models were able to gain significantly more autonomy, by grepping the codebase, and pulling file contents directly into context.
At TrueState, we did some experimentation in early 2025 with building a chatbot that could use tool-calling for document retrieval. We were shockingly impressed by its performance, and have iterated on it today to produce our Document Agent. Users can upload PDF files to our platform, and add them to their chat context along with datasets and other entities, and the bot is able to pull them into the chat context as required to improve the quality of its analysis.
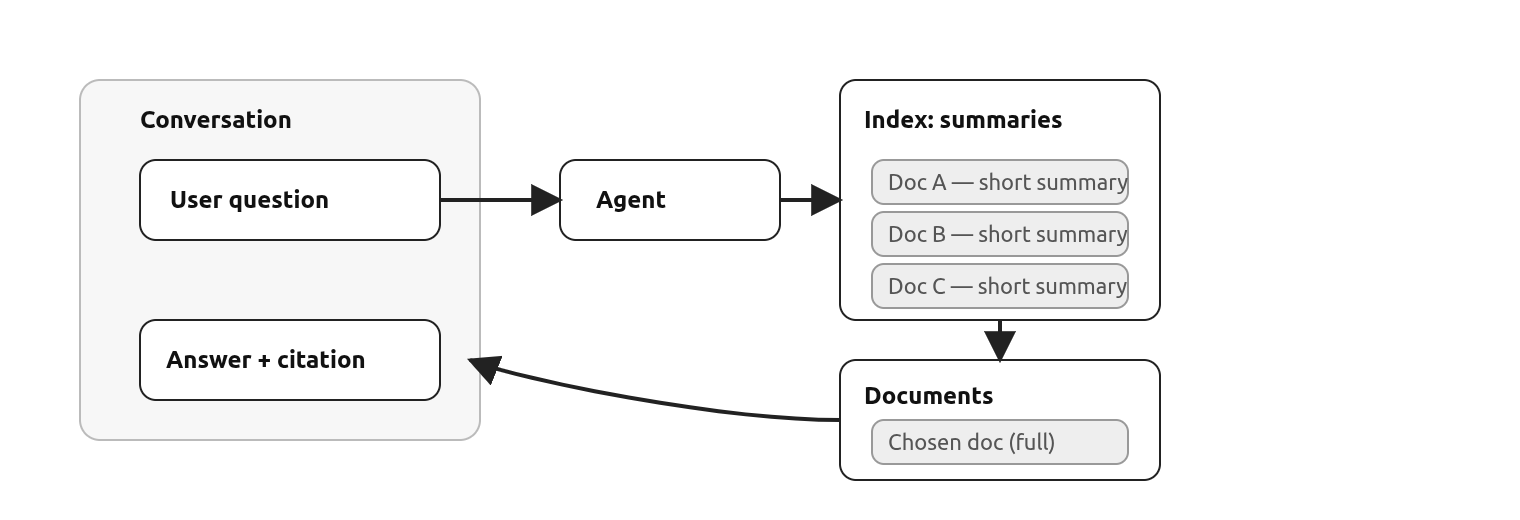
Index Generation
We need to work out what is in a document before we can understand whether it needs to be accessed. TrueState has functionality to allow a user to upload their documents into the platform and we will perform the required preprocessing.
Once the document is uploaded, we read it using OCR into markdown. We make sure to separate each page by a page number. This is pretty expensive, however it is a necessary step for handling complex and inconsistently formatted PDFs. When building Agentic Retrieval, documents can be ingested any way you like - the important thing is to move them from being an image to being coherently structured text.
We then generate a short summary based on the content of the document. We use a high context window but cheap LLM to do this, as it does not require any reasoning. This summary becomes the index for the agent retrieval tool.
We provide the agent with the summary description of each document, and instructions for how to retrieve the full document, and it is able to successfully decide which document is required and pull it into the context.
Context Injection vs Answer Retrieval
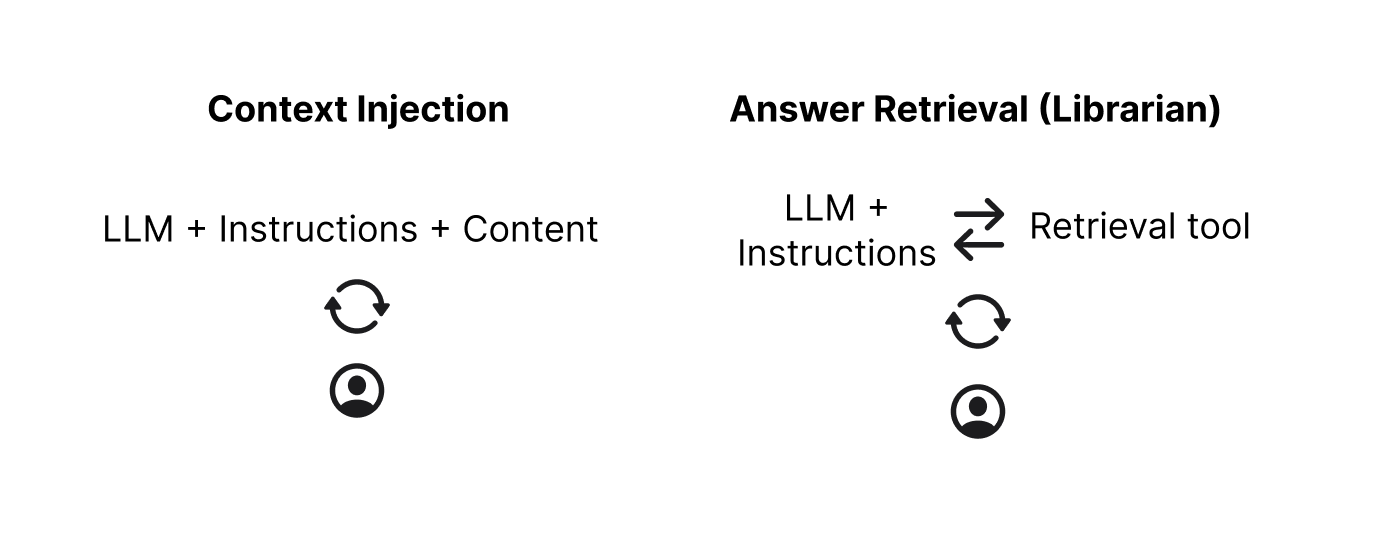 There are 2 paradigms that can be used with an Agentic Retrieval tool. The first is to dispatch the conversation context, or a specific bot formulated question, to a ‘librarian’ which is able to read through the available documents, and formulate an appropriate response. This response then gets added to the conversation, but the documents that were used to get the answer are not visible within the conversation.
There are 2 paradigms that can be used with an Agentic Retrieval tool. The first is to dispatch the conversation context, or a specific bot formulated question, to a ‘librarian’ which is able to read through the available documents, and formulate an appropriate response. This response then gets added to the conversation, but the documents that were used to get the answer are not visible within the conversation.
The second paradigm is to pull the required documents into the conversation context, and rely on the conversation chatbot to decide which documents are necessary. This blows up the conversation context size, but is extremely thorough as all the required context is always available.
Which solution is appropriate depends on the use case. If the documents are small, like Python files for a coding agent, it makes sense to pull the whole document into the context. If the documents are long, like large technical manuals, these will fill out the context window too quickly.
An interesting thing we experienced building this system was that the bot often doesn’t ‘want’ to query the documents. If it can answer the question based on its own knowledge, or on the document summary, it will try to do that. This is not great in most cases, and we have had to be very specific in the prompt that it must query appropriate documents before generating its response. I suspect somewhere in the foundation model training step, the bot is penalised for making superfluous tool calls. I wonder if in the future we will be able to decide between a ‘curious’ bot and a ‘lazy’ bot, in a similar way to how we specify thinking efforts today.
An Agent Can Do Embedding Search
We found that our users were not sure how to use embedding search. They would typically be writing keyword type queries that we have all been trained to use from 25 years of Google search.
We were able to provide an embedding search to our chatbot. This allowed it to search a dataset for relevant results, view them, then synthesise the response using these. This is essentially a reranker within a chat interface, without needing an extra LLM call.
Examples
The major success story of this is Cursor / Claude Code. It is able to retrieve relevant files into its context using an agentic strategy.
At TrueState, we have had success with using AI Agentic Retrieval for reading technical documentation. A corpus of technical documents that will be too large to fit in the context window can instead be provided to a bot, and it will have the tools to automatically retrieve the relevant document.
Design Tradeoffs
Many of the Hacker News comments regarding RAG are confused by the design tradeoffs between solutions. This is somewhat typical for software engineers, who prefer an optimal algorithm that works across all inputs; unfortunately that is not available here.
Document Count
With the current tech, AI Agent retrieval will cap out with fewer documents. We’ve used it for about 100 highly technical documents with success, however this quantity will be highly sensitive to the nature of the documents. It will also depend on the length and detail of the document summaries. If all the documents are quite similar, it is very difficult to know which one to read.
Embedding search will scale indefinitely, but again will run into problems with similar documents. For example, if we have a million documents, we can perform an embedding search and add the top 5/10/100 to the context (depending on the typical document length, or by using a fixed cutoff). However if the answer to the question lies outside of these top k records, which is more likely to occur with more records, we will still be stuck.
Document Length
The direct context injection strategy will work with short-medium size documents, but will eventually fill up the context window. Agentic Retrieval can handle much longer documents, as we are only adding documents to the context as required.
Embedding search will fall off after documents become a specific length. This is due to the innate nature of what it means for concepts to be ‘similar’, rather than due to a technical limitation. Of interest is that the gemini-embedding-001 SOTA model only has a context window of 2048 input tokens. Beyond this, you will need to either chunk data or use Agentic Retrieval.
Speed
The embedding search retrieval strategy is the fastest - it requires a single LLM call with the embedding search results provided in the context. Embedding search is trivially fast if a vector store has been set up, and its runtime is dwarfed by the LLM text generation time.
Direct context injection is also fast as the required context is already within the conversation so only 1 LLM call is required.
The agentic retrieval strategy requires at least 2 LLM calls. The first to choose which document to retrieve, and then a second to perform an action based on the document context. Depending on the strategy, there may even be a third call: first to choose the document, second to answer the question, third to synthesise an LLM response.
The difference between 1 and 2+ LLM calls is significant for a chat based application. Response time is one of the most important UX considerations for chatbots. However, for a more agentic strategy where the bot is being dispatched to perform research, this delay is not significant, and this strategy can be easily utilised here.
Context size also affects the latency of the bot response both innately in processing time, and in terms of additional thinking required. Providing a lot of context, combined with complex instructions, can cause the bot to need to think for a long time for every response.
The Future
I am really excited about 2 things: the first being improved actual context window length (i.e., Llama 4 has a 10m context window - but needle in a haystack retrieval degrades beyond a few hundred k tokens (llama-article)), and the second being decreases in input token costs.
Increased context lengths mean that we may one day be able to just forget retrieval altogether and just inject any context we need. Once the cost per token comes down, we can get reckless with dispatching subagents. If cost drops by 1 or 2 orders of magnitude, we could consider reading every document, looking for an answer in each, then introducing an evaluation bot at the end to see which document was right.
The sky is the limit here and any model improvements will be welcomed.
Conclusion / Cheat Sheet
Choosing the right RAG strategy is fundamentally about understanding your constraints: document count, document length, and latency requirements. There is no one-size-fits-all solution, and the optimal approach will depend on your specific use case.
The table below provides a quick reference guide for selecting a strategy based on your requirements:
| Strategy | Best For | n Documents | Notes |
|---|---|---|---|
| Direct Context Injection | Few / short-medium documents | Few | Fastest (1 LLM call), simplest to implement. Limited by context window size, cost, and performance. Use XML-style tags for context separation. |
| Embedding Search | Shorter-length documents | Many | Fast (1 LLM call), scales indefinitely. Works best with documents under 2048 tokens. May struggle with very similar documents or require chunking for longer content. |
| Agentic Retrieval | Longer, more detailed documents | Fewer | Requires 2+ LLM calls (slower latency). Needs a sensible index (summary / filesystem). Best for technical manuals and complex documents. Can handle full document retrieval on demand. |