Share
Introduction
As Uber’s data infrastructure evolves toward a hybrid cloud architecture, understanding data access patterns across our platform is more critical than ever. This data I/O (Input/Output) observability plays a crucial role in the journey to CloudLake (Uber’s hybrid cloud architecture). As part of the CloudLake migration, Uber is expanding its compute and storage capacity in the cloud, while gradually decommissioning on-prem capacity. This opens up a new set of problem statements. First, the cross-service provider network link is a bottleneck. Second, colocating workloads with datasets for efficient execution is envisaged, but the challenge arises due to a lot of experimenta…
Share
Introduction
As Uber’s data infrastructure evolves toward a hybrid cloud architecture, understanding data access patterns across our platform is more critical than ever. This data I/O (Input/Output) observability plays a crucial role in the journey to CloudLake (Uber’s hybrid cloud architecture). As part of the CloudLake migration, Uber is expanding its compute and storage capacity in the cloud, while gradually decommissioning on-prem capacity. This opens up a new set of problem statements. First, the cross-service provider network link is a bottleneck. Second, colocating workloads with datasets for efficient execution is envisaged, but the challenge arises due to a lot of experimental workloads with no fixed read pattern. Third, efficiently tiering our very large data footprint is crucial for cost reasons, and having a heat-map view of the I/O pattern is essential. We process millions of Apache Spark™, Presto™, and Anyscale Ray® workloads daily across Apache HDFS™ and cloud object storage, but until recently we had no visibility into how much data each job read or wrote, and from where.
This blog shares how we filled this critical observability gap and powered storage paradigms like HDFS, GCS (Google Cloud Storage™), Amazon S3®, and Oracle Cloud Infrastructure® without requiring any application code changes. The system we built now powers Uber-wide insights into:
- Cloud provider network egress attribution
- Cross-zone traffic monitoring
- Dataset placement for CloudLake
- A storage-level heatmap
Before this work, Uber’s infrastructure had no unified mechanism to answer basic but essential questions like:
- What’s an application’s read or write throughput?
- What’s the overall read or write throughput on a dataset partition?
- Which workloads are generating high network egress from the cloud?
- Which workloads are contributing to significant network congestion across on-prem and cloud boundaries?
- Which datasets are consistently and heavily accessed across on-prem and cloud boundaries?
- How should we tier data, co-locate, compute, or efficiently duplicate datasets to reduce transfer costs and minimize latency?
Problem 1: High Coverage, Transparent Observability
To get network usage across the data platform and its various services and offerings, we needed a universal and caller-agnostic solution. Presto logs offered partial answers, but only for SQL reads, at a table level, and only from a single engine. There was no equivalent for Spark, ad hoc jobs, or direct HDFS/GCS usage. There was also no insight at the dataset partition level, which is key for operational decisions and migration planning.
Due to the lack of existing solutions, we bootstrapped network observability with the primary goal of being real-time, engine and vendor-agnostic, and at the table/partition level.
To achieve this, we extended Uber’s Apache Hadoop®-compatible file system clients (HDFS and GCS) to intercept all file stream operations. Specifically, input and output streams (FSDataInputStream, FSDataOutputStream) that are responsible for reading and writing data. We track the byte counts per parent directory of each accessed file (which corresponds to a dataset and partition) within the instrumented stream. We also capture additional runtime metadata (zone, app ID, operation type, engine, and other application metrics) to attribute the datapoint.
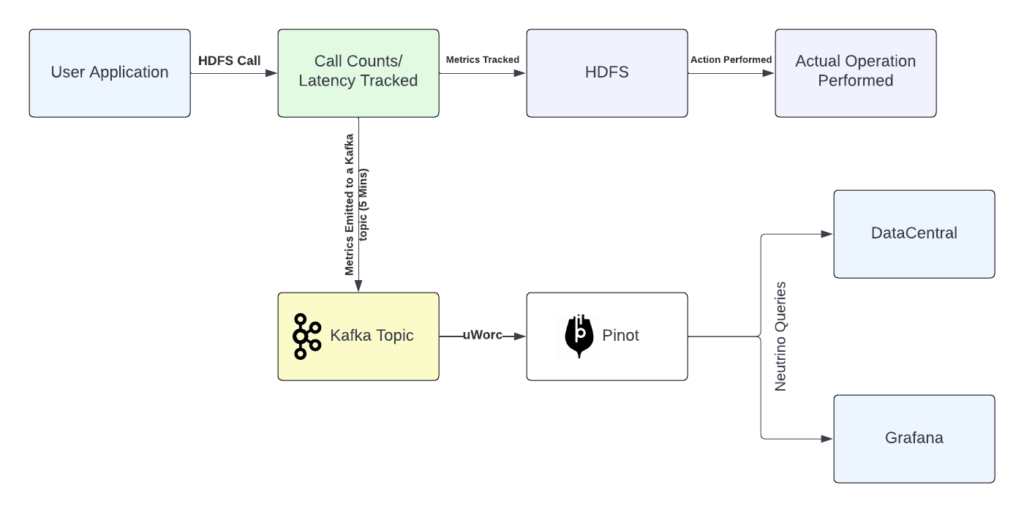 Figure 1: Network and file system observability at Uber.
Figure 1: Network and file system observability at Uber.
Making this change wasn’t trivial. Since the Hadoop file system streams were in the critical path, we needed to gather high-dimension metrics in real time, without compromising client performance.
The Hadoop file system is an abstract class that offers APIs to read, write, and list in HDFS. We created a wrapped file system that aggregates metrics through Tally and produces to a message queue in real time. This change in the base file system enables us to track all infrastructure that extends from it (all callers using the Uber HDFS client). This also allows us to extend support to any new vendors (GCS/S3) without writing major code, preventing issues like vendor lock-in. Any caller can enable this through a feature flag, ensuring clients, engines, and services across the data platform can benefit from this feature.
Within the client, we built a method interceptor that could intercept any incoming call to the file system and track metrics like latencies and call counts. The interceptor then allows the call to go forward and perform its natural operation and waits for the response. The reporter uses Tally and aggregates these metrics. Given the potentially huge volume of calls received by HDFS daily, it’s essential to aggregate the metrics and send aggregated payloads to a topic. We use Tally to aggregate these metrics, and send a single payload to the topic every few minutes (typically configured at 15 minutes). This approach ensures near-real-time observability while maintaining manageable throughput, enabling downstream services to consume the data efficiently.
The result is a fine-grained metric emitted per job container, per dataset, with zero change to job code. Spark, Presto, and custom jobs benefit automatically. While this client-based instrumentation provided the right signals, the volume of raw metrics became extremely high scale and expensive to manage.
At full scale, Uber infrastructure operates with:
- 6.7 million YARN™ containers per day
- 400,000 Spark apps and 350,000 Presto queries per day
- Each container reads and writes multiple paths, emitting metrics per path every minute
Publishing this directly to a time-series database can generate tens of billions of events daily, overwhelming our storage and observability infrastructure. This takes us to our second problem.
Problem 2: High Cardinality Time-Series Metrics
Since publishing billions of metrics to a message-queue topic can be expensive and hard to manage for downstream consumers, we needed a way to manage scale in flight at the network layer before landing on the storage. Our solution to this was HiCam, a lightweight, in-house metrics aggregator that runs as a remote HTTP server, backed by an Apache Flink® job. It acts as a reduction layer between clients and downstream storage.
Clients use a Tally-based HTTP metrics reporter to batch and send metrics every few minutes. HiCam receives metrics across several thousands of containers, aggregates them in memory (across an application_id), and emits single consolidated events every few seconds. This dramatically reduces write amplification and avoids storing duplicate metrics for the same dataset and app.
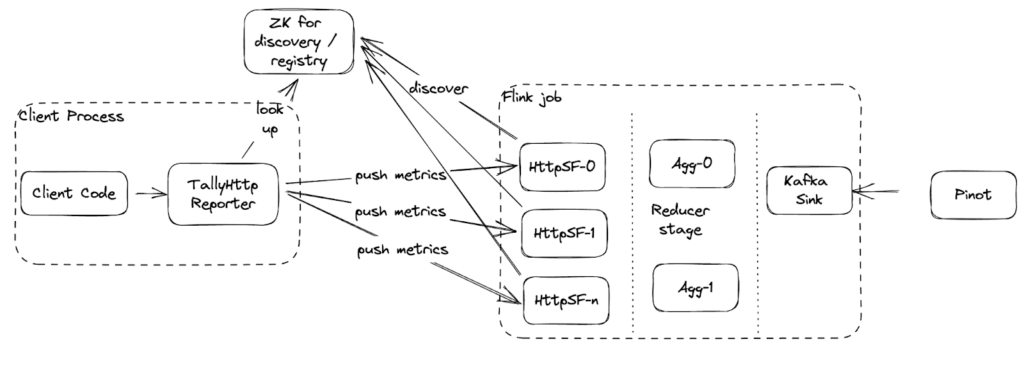 Figure 2: HiCam setup to manage high scale and cardinality.
Figure 2: HiCam setup to manage high scale and cardinality.
HiCam is resilient, supports high availability via Apache Zookeeper™ discovery, and is now the standard pipeline for all file system-level observability at Uber.
As seen in Figure 2, clients can discover the HiCam service through a Zookeper discovery pool that redirects the requests to one of the reducers (and acts as an indirect load balancer). Clients can then publish metrics to this aggregation layer that reduces it and ultimately publishes data to a topic (that’s also ingested into Apache Pinot™ for real-time analytics). This outperforms several limitations of various time-series data stores, including Uber’s in-house data store that can sometimes not scale well with high cardinality (see Table 1).
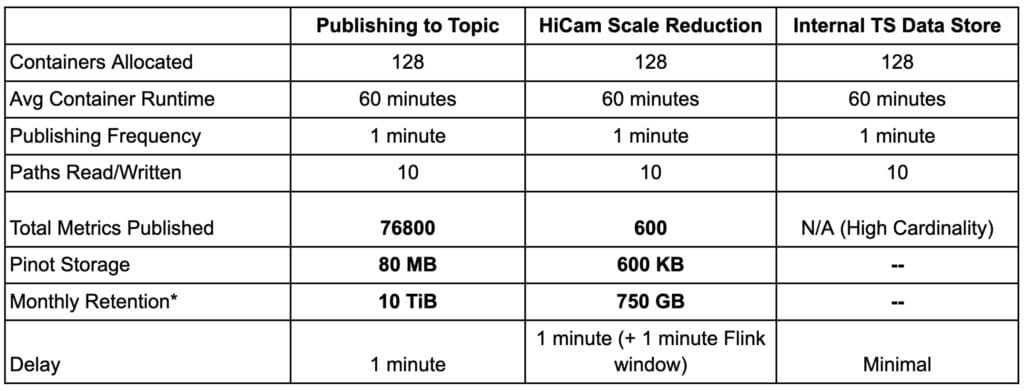 Table 1: Performance/storage reduction with the HiCam solution.
Table 1: Performance/storage reduction with the HiCam solution.
This solution is generic and can serve other non I/O observability use cases that require high cardinality and real-time reduction. It’s essentially suitable for containerized/virtualized environments that can emit billions of metrics daily in enterprise settings.
Ultimately, we have real-time analytics on all data points that can arrive at a 5 minute delay from the client. This can go as low as 1 minute for critical use cases. The metrics shown in Table 2 are collected and presented to users to enable attribution of network usage to various dimensions such as owner, application_id, engine, and so on.
Table 2 shows attributes captured as part of the observability event.
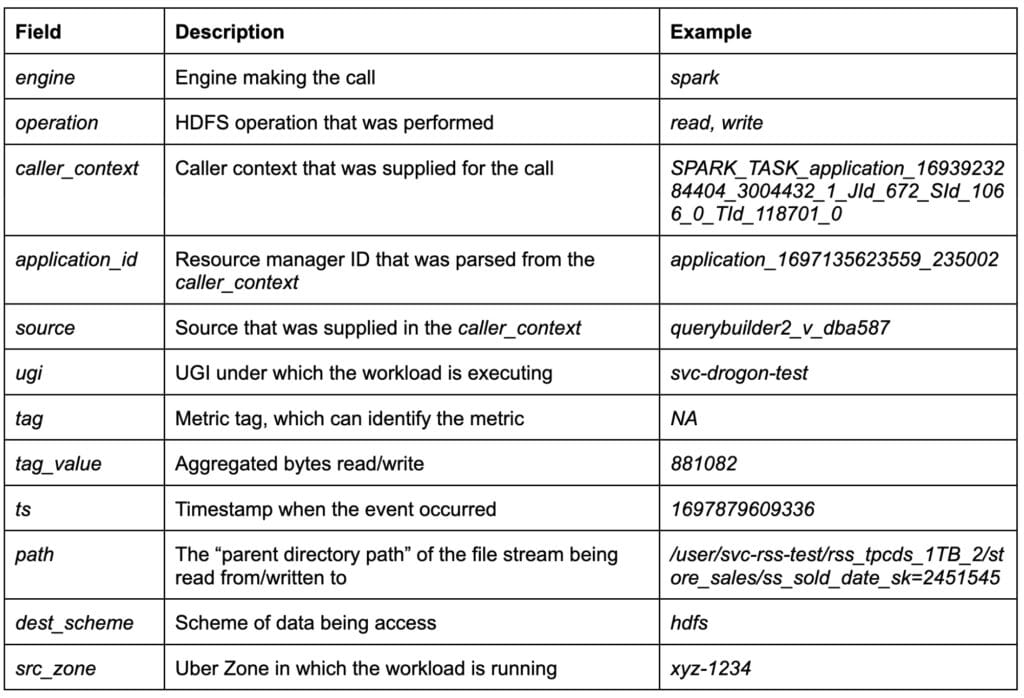 Table 2: Dimensions captured for incident mitigation and attribution.
Table 2: Dimensions captured for incident mitigation and attribution.
Outcomes: End User Visibility
The real-time insights we provided for engineers helped them debug data jobs, run efficient planning for the cloud migration strategy, power chargeback use cases, and mitigate incidents.
Today, this observability powers over 400,000 Spark applications and 2 million Presto queries daily at Uber using just under a few terabytes of storage requirements on Pinot. The metrics are also wired up to end users and engineers through an in-house data observability platform called DataCentral. In DataCentral, users can go to application-level pages to view detailed insights into their Spark applications, view network usage and file system latencies, and analyze performance bottlenecks (see Figure 3).
 Figure 3: Real-time application-level insights on DataCentral.
Figure 3: Real-time application-level insights on DataCentral.
The observability is also available in real time on an aggregated Grafana®* * dashboard that engineers, on-call engineers, and app owners can use for incident mitigation and real-time insights. Users can slice and dice data across read/write patterns, top applications causing high-egress, top tables, and top paths that are frequently accessed along with the exact network throughput on each dimension. Additional metrics like top users and hosts are also available to end users. Figure 4 shows one of the dashboards.
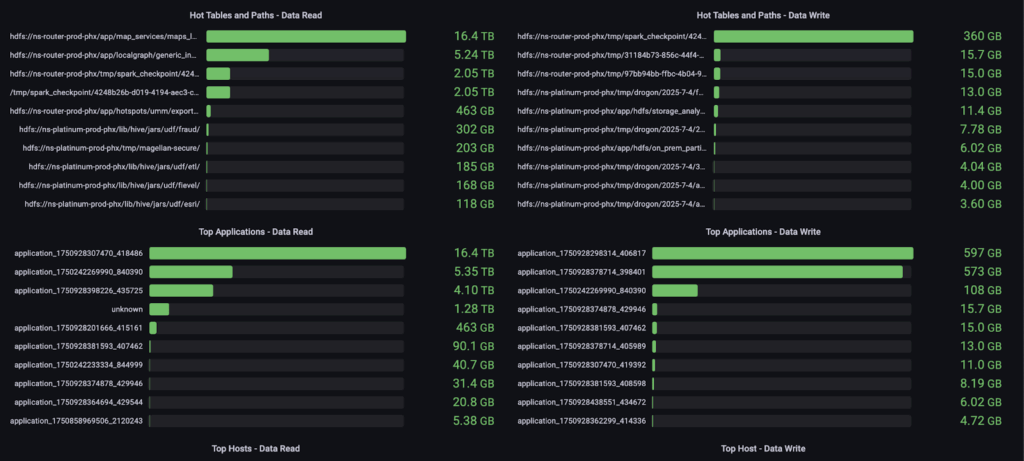 Figure 4: Top applications/paths for incident mitigation and insights.
Figure 4: Top applications/paths for incident mitigation and insights.
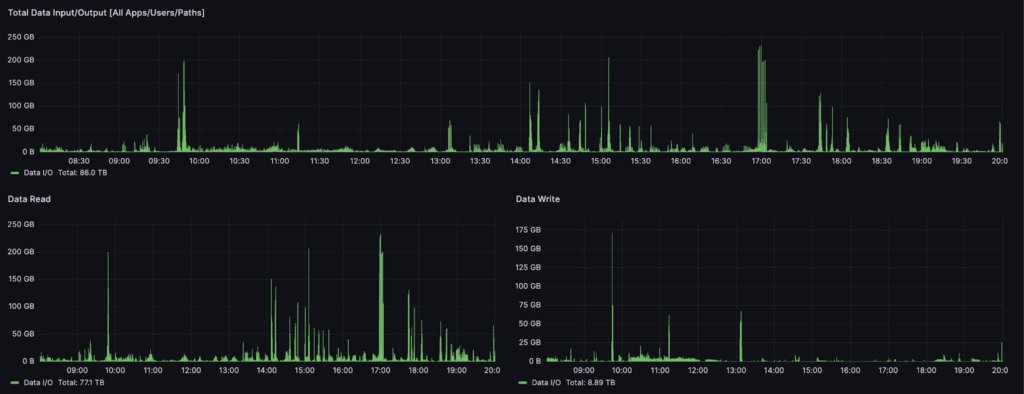 Figure 5: On-prem to GCS egress and ingress.
Figure 5: On-prem to GCS egress and ingress.
The dashboard in Figures 4 and 5 shows real-time metrics that power several alerts for high egress usage. Since the metrics are real-time, engine teams are aware of possible degradation and have debugging capabilities in a matter of seconds. Our Grafana dashboards are wired up to a Pinot table that retains limited data for real-time analytics. Further, the data is also ingested into Apache Hive™ tables for offline analysis, which powers chargebacks and long term visualization and strategic planning. The metrics power several key decisions for the CloudLake migration strategy and will be used for dynamic routing decisions as the cloud migration progresses.
Overall, we designed this solution to handle path- and application-level high-cardinality metrics tracking millions of applications and paths daily. In the future, we plan to integrate it with Uber’s centralized observability for unification while querying.
Conclusion
We built byte-level dataset I/O observability by enhancing Uber’s HDFS and GCS clients, achieving full coverage without requiring a single job code change. Using HiCam to aggregate high-cardinality metrics at scale, we now emit real-time, low-overhead signals that power cost attribution, incident prevention, and strategic CloudLake planning.
This observability foundation unlocks a range of future capabilities, including:
- Data tiering based on true usage patterns
- Enriching metrics with storage class and object metadata
- Extending observability to HTTP traffic for cross-service data flows
- Real-time quota alerts at user or dataset level
Whether running on prem, cloud, or hybrid, investing in low-overhead, I/O observability unlocks deep cost, performance, and migration insights. Prioritizing client-side instrumentation massively helps in broad applicability across the platform. Real-time downstream aggregation has helped us reduce scale and costs while maintaining comprehensive coverage.
Ultimately, this work has replaced patchy, engine-specific logging with a unified, engine-agnostic, zero-touch observability layer across Uber’s data lake.
Amazon S3® is a trademark of Amazon.com, Inc. or its affiliates.
Apache®, Apache Spark™, Apache HDFS™, Apache Hadoop®, Apache Pinot™, Apache Flink®, Apache Spark SQL™, Apache Hive™, Apache Zookeeper™, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Google Cloud Storage™ is a trademark of Google LLC and this blog post is not endorsed by or affiliated with Google in any way.
The Grafana Labs® Marks are trademarks of Grafana Labs, and are used with Grafana Labs’ permission. We are not affiliated with, endorsed or sponsored by Grafana Labs or its affiliates.
Oracle®, Oracle Cloud Infrastructure, OCI, Java, MySQL, and NetSuite are registered trademarks of Oracle and/or its affiliates.
Presto® is a registered trademark of LF Projects, LLC.
Ray is a trademark of Anyscale, Inc.