Jan 22nd, 2026 Lev Kokotov
PgDog is a proxy for scaling PostgreSQL. Under the hood, we use libpg_query to parse and understand SQL queries. Since PgDog is written in Rust, we use its Rust bindings to interface with the core C library. Those bindings use Protobuf (de)serialization to work uniformly across different programming languages, e.g., the popular Ruby pg_query gem.
Protobuf is fast, but not using Protobuf is faster. We forked pg_query.rs and replaced Protobuf with direct C-to-Rust (and back to C) bindings, using bindgen and Claude-generated wrappers. This resulted in a 5x improvement in parsing queries, and a 10x improvement in deparsing (Postgres AST to SQL string conversion).
Results
You can reproduce these by cloning our fork and running the benchmark tests:
| Function | Queries per second |
|---|---|
pg_query::parse (Protobuf) | 613 |
pg_query::parse_raw (Direct C to Rust) | 3357 (5.45x faster) |
pg_query::deparse (Protobuf) | 759 |
pg_query::deparse_raw (Direct Rust to C) | 7319 (9.64x faster) |
The process
The first step is always profiling. We use samply, which integrates nicely with the Firefox profiler. Samply is a sampling profiler: it measures how much time code spends running CPU instructions in each function. It works by inspecting the application call stack thousands of times per second. The more time is spent inside a particular function (or span, as they are typically called), the slower that code is. This is how we discovered pg_query_parse_protobuf:
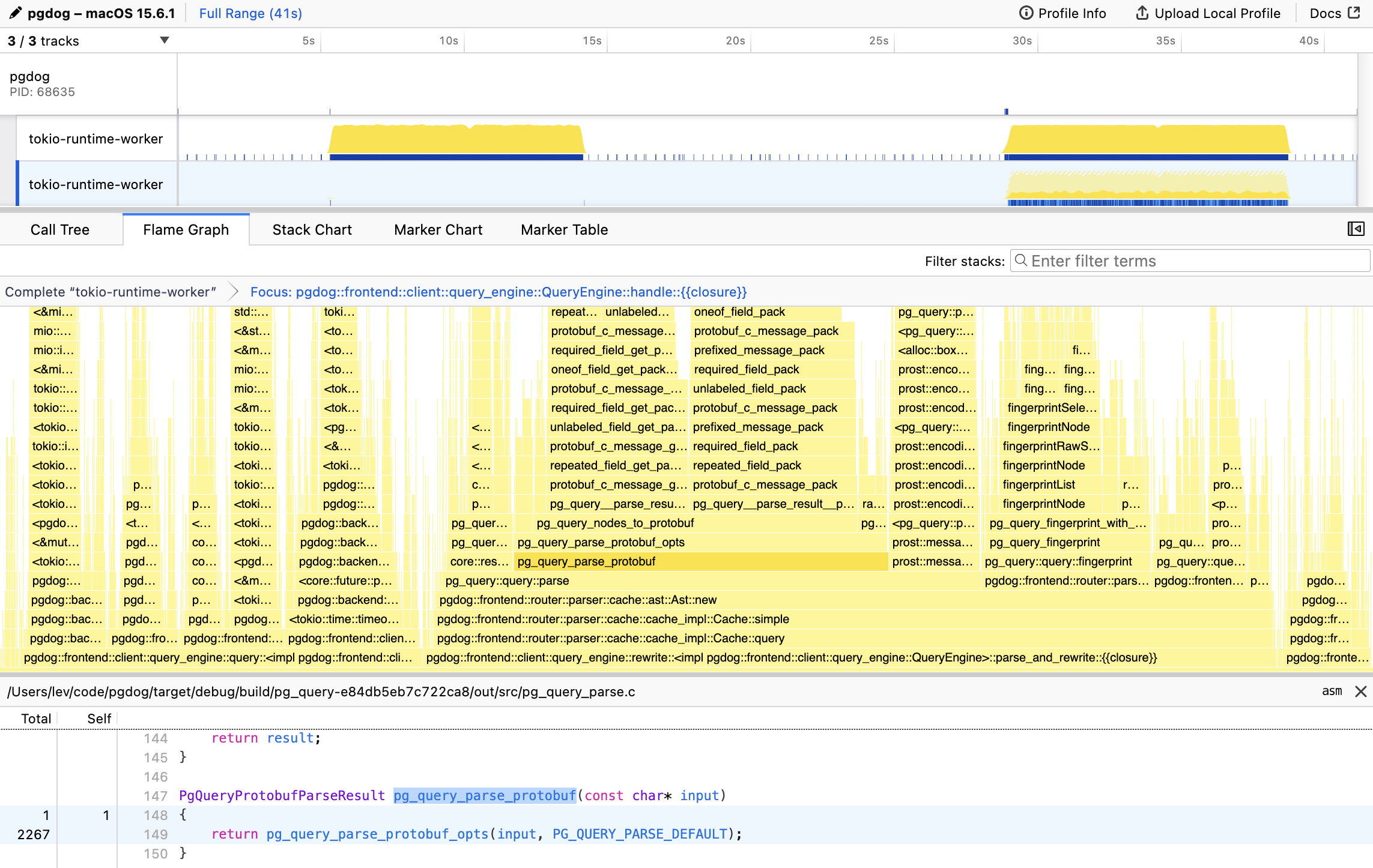
This is the entrypoint to the libpg_query C library, used by all pg_query bindings. The function that wraps the actual Postgres parser, pg_query_raw_parse, barely registered on the flame graph. Parsing queries isn’t free, but the Postgres parser itself is very quick and has been optimized for a long time. With the hot spot identified, our first instinct was to do nothing and just add a cache.
Caching mostly works
Caching is a trade-off between memory and CPU utilization, and memory is relatively cheap (latest DRAM crunch notwithstanding). The cache is mutex-protected, uses the LRU algorithm and is backed by a hashmap1. The query text is the key and the Abstract Syntax Tree is the value, which expects most apps to use prepared statements. The query text contains placeholders instead of actual values and is therefore reusable, for example:
SELECT * FROM users WHERE id = $1;