State of the Art Performance. 1% of the Compute.
Introducing the Ensemble Listening Model
Bypassing scaling limits through dynamic ensemble orchestration.
“Pre-training will run out of data. What do you do next? ... But now that compute is [so] big...we are back to the age of research.”
Scaled models scale costs
The larger the model, the more it costs to train, retrain, and deploy at inference time. As GPUs become more expensive and even their raw materials become scarce, there’s a need to fit more intelligence into existing compute envelopes, rather than simply scaling up.
An ELM is not a single monolithic model. It is a coordinated ensemble of dozens or hundreds of specialized sub-models, all managed under a shared orchestration layer.
It’s well known that ensemble architectures can improve accuracy at decreased costs. Yet orchestrating larger quantities of sub-models - especially heterogeneous models with different focuses - requires more sophisticated orchestration than has been done before.
The ELM is a new AI architecture - battled tested already in real applications for Fortune 500 companies, handling millions of queries each day. By leveraging hierarchical processing and dynamic ensemble blocks, ELMs unlock the ability to match state-of-the-art accuracy from monolith models - but at a tiny fraction of the training and inference costs.
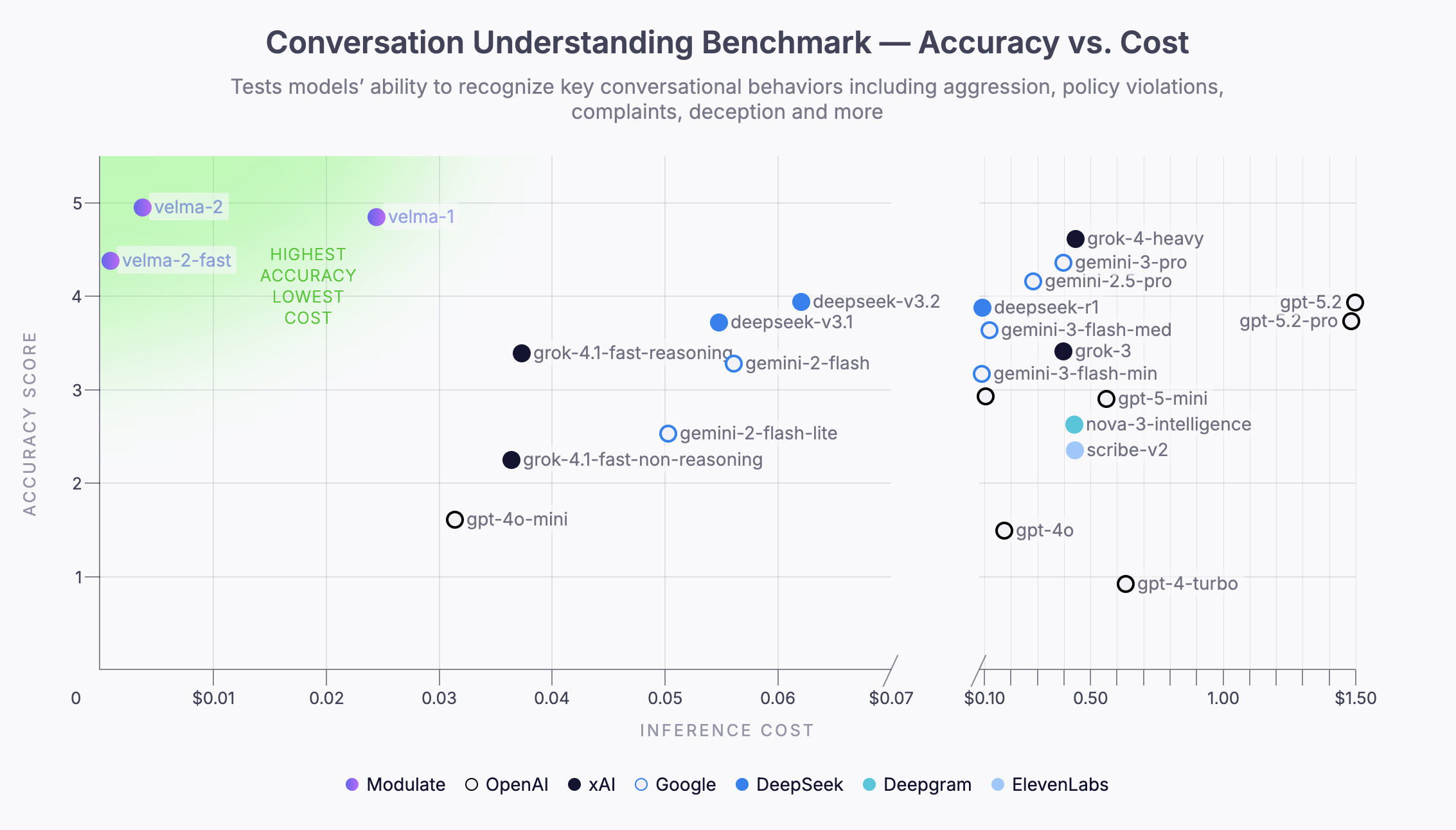
Example: An ELM built for voice understanding, Velma, exceeded the accuracy of leading foundation models, while delivering >100x cost improvements
The core benefit of the ELM is straightforward - despite using potentially hundreds of sub-models, they can afford to be much smaller (thanks to their more specialized role) than generalist, monolith models. When each sub-model uses thousands of times less compute than a fully general monolith, and not all sub-models need be run at all times, the end result is a compute advantage of multiple orders of magnitude.
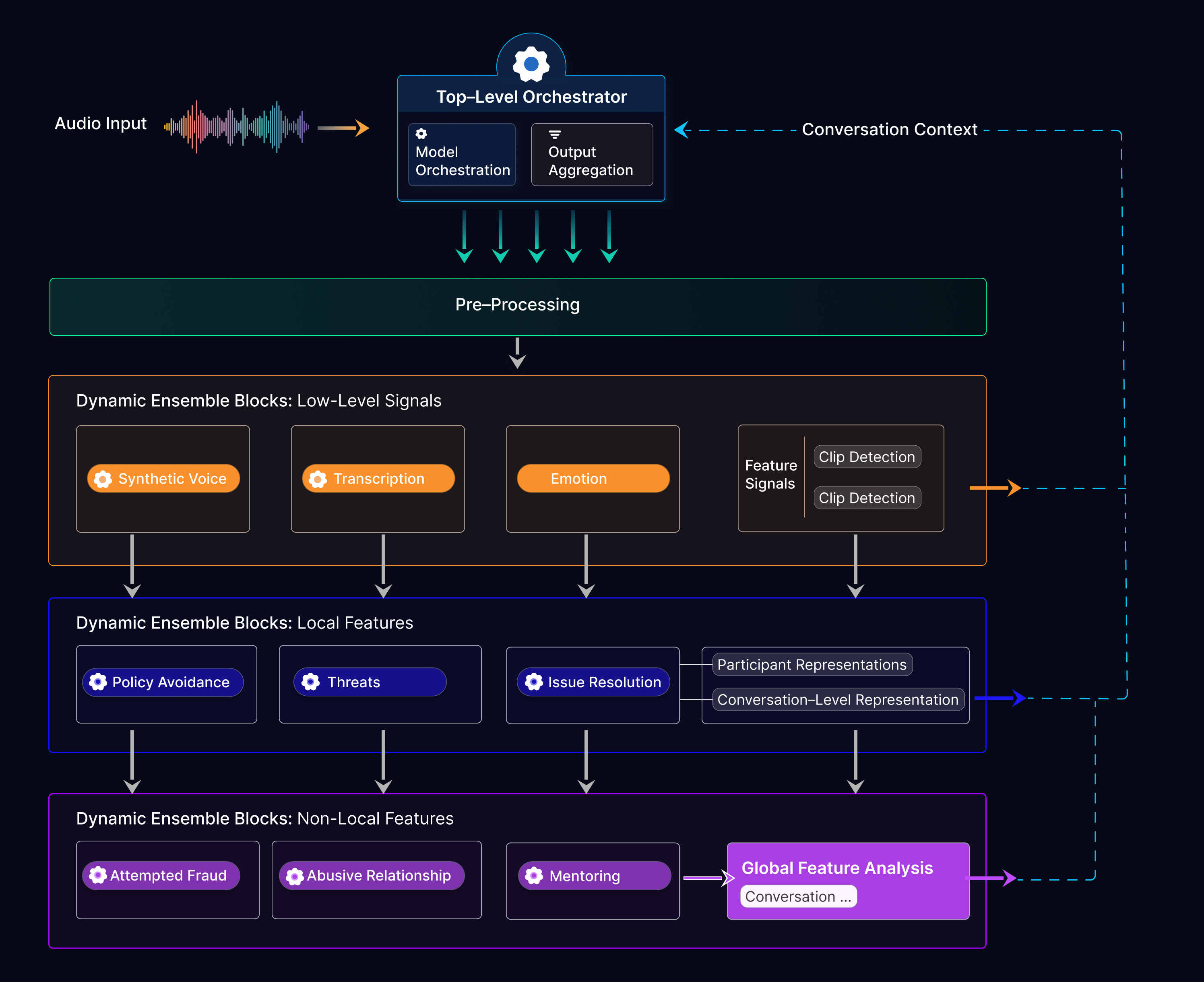
An example diagram of an Ensemble Listening Model focused on audio processing and analysis.
Dynamic Ensemble Blocks are collections of homogenous models - their input and output formats are the same, they are intended to answer the same question, but they each perform differently in different circumstances.