Introduction
Prompt caching is a provider-native feature that stores and reuses the initial, unchanging part of a prompt (the prompt prefix) so that large language models don’t have to process it again on every request. More specifically, it caches the internal state of the model for that prefix, reducing redundant computation. This results in reducing latency and input token savings, without any loss in quality. In other words, prompt caching makes your LLM calls faster and cheaper whenever you use prompts with long, identical prefixes (like system instructions, tools, or context data) in multiple requests.
This article will expla…
Introduction
Prompt caching is a provider-native feature that stores and reuses the initial, unchanging part of a prompt (the prompt prefix) so that large language models don’t have to process it again on every request. More specifically, it caches the internal state of the model for that prefix, reducing redundant computation. This results in reducing latency and input token savings, without any loss in quality. In other words, prompt caching makes your LLM calls faster and cheaper whenever you use prompts with long, identical prefixes (like system instructions, tools, or context data) in multiple requests.
This article will explain how it works behind the scenes, how to structure your prompts to maximize cache hits, and the differences in implementation between OpenAI, Anthropic Claude, and Google Gemini. We will also show how it compares to semantic caching, and how to measure its ROI while avoiding common pitfalls.
Key Takeaways
- Prompt caching reuses model state, not outputs: Prompt caching saves significant latency and input-token cost by reusing the in-model computation for a given prompt prefix with no change in model quality.
- Exact prefix matching is non-negotiable: Even tiny differences (whitespace, JSON key order, tool definitions) break cache hits, always structure prompts as static first, dynamic last.
- Provider implementations differ materially: OpenAI provides automatic prompt caching with routing and retention controls, Claude requires explicit cache_control breakpoints, and Gemini offers both implicit and explicit cache objects with configurable TTLs.
- Measurement determines ROI: Measure cache hit rate, cached token fraction, time-to-first-token (TTFT), and input token savings to validate actual performance and cost improvements.
- Best results come from layered caching: Combine prompt caching (inside the model) with semantic caching (at the application layer) to minimize both per-request cost and total LLM calls at scale.
What is prompt caching?
Prompt caching is an easy win for faster and cheaper LLMs, as it reuses the unchanged prefix of a prompt across calls. When enabled, the LLM’s API checks to see if your prompt begins with a prefix that the model has recently seen. If it does, it will skip computation for that prefix instead of recomputing those tokens. This can reduce latency by up to 80% and reduce input token costs by up to 90% for large and repetitive prompts. The key point here is that prompt caching reuses the model’s intermediate state (e.g., key-value tensors in the transformer’s attention layers) for the prefix tokens, rather than the output text itself. This means the final output of the model remains unaffected – prompt caching will give the same output as if it were processed normally, but without any redundant work on the prefix.
How Prompt Caching Works Under the Hood
At a high level, prompt caching relies on exact prefix matching and provider-side caching of model state for that prefix. The mechanism can be summarized in a few steps:
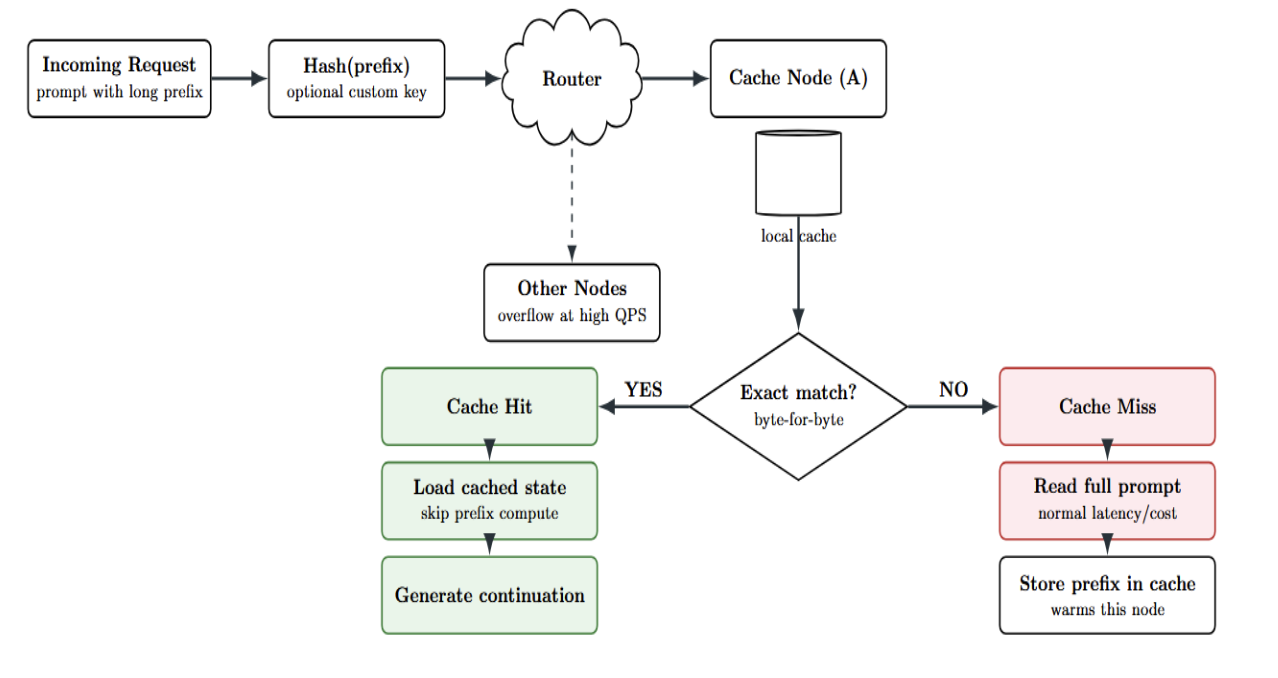
- Prefix Hashing & Routing: An incoming API request is assigned a hash/key based on the first part of the prompt (e.g., the first few hundred tokens). This hash is used to route the request to a server that may have recently received an incoming request with the same prompt prefix.
If you issue many requests in rapid succession with the same exact prefix, they will be routed to the same cache node – though at very high rates (e.g.,>15 requests per minute with the same exact prefix), some requests may overflow to other machines, and cache effectiveness will be reduced.
- Cache Lookup: Once the request is routed to a server, the system will attempt to determine if it already has a cached prefix state matching the beginning of the current prompt. Note that this is an exact match check; the prefix text (and even attachments such as images or tool definitions) must be byte-for-byte identical to a previous incoming request’s prefix for a cache hit.
A single character difference, a different order of JSON keys, or a setting toggled in the prefix will cause a mismatch and result in a cache miss.
- Cache Hit: If the system finds a cached prefix match, the model will transition directly to the cached state, bypassing the need to reprocess the input tokens. The cached key/value tensors or similar model state are loaded into memory, and the model immediately starts generating the rest of the response, as if it had already read the prefix.
- Cache Miss: If no matching cached prefix is found, the request will proceed normally – the model will read the entire prompt as usual, incurring the full latency/cost. The good news is that after that request, the system stores that prompt prefix into the cache (on that server) so that future requests can reuse it.
Provider Implementation Notes
Provider-native prompt caching can materially reduce time-to-first-token and input spend, but the “how” differs across OpenAI, Anthropic Claude, and Google Gemini. The practical goal remains the same: identify the largest stable prefix in your requests, maintain it byte-for-byte across calls, and instrument cache metrics to validate hit rates and ROI in production.
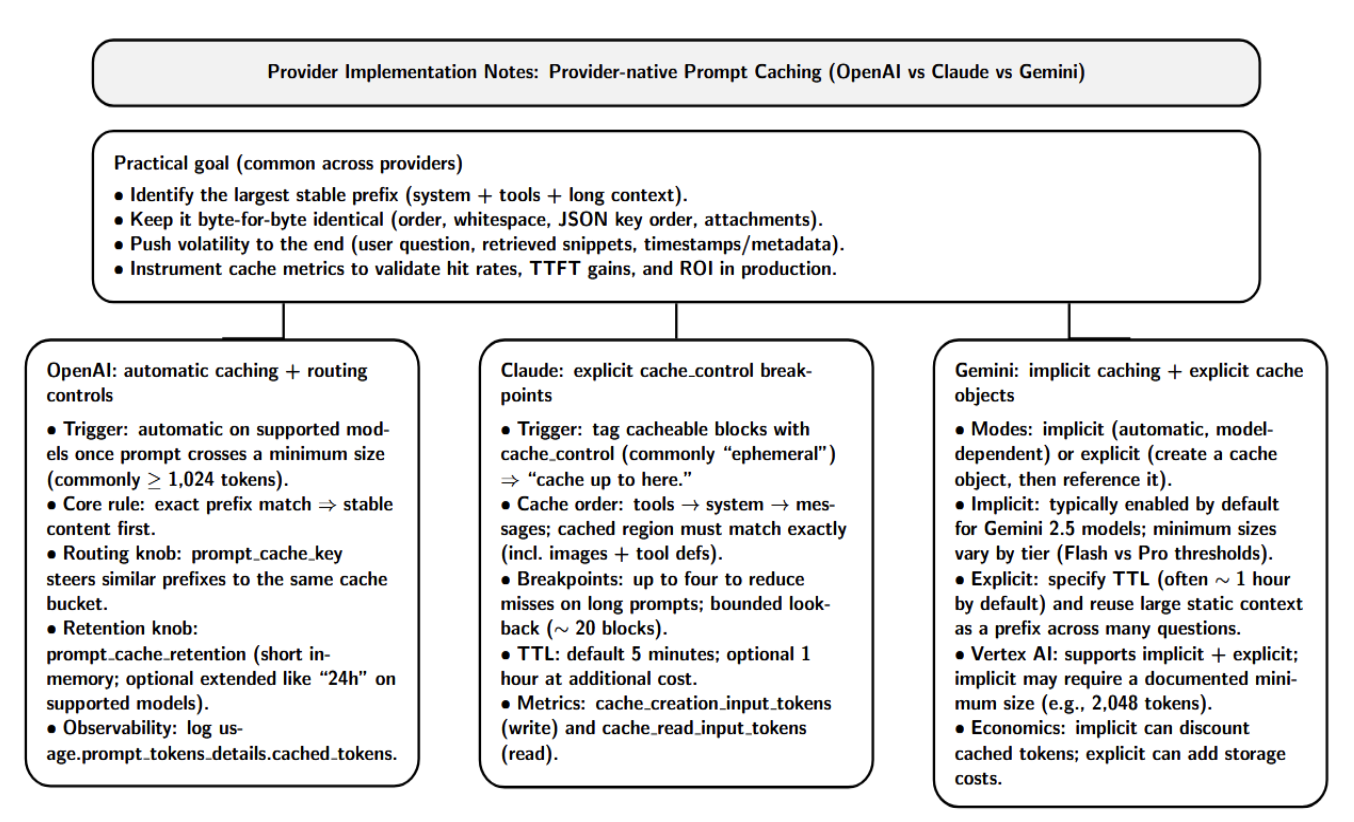
OpenAI: automatic caching with routing controls
OpenAI prompt caching is automatic on supported models when your prompt crosses a minimum size (commonly ≥ 1,024 tokens). The core rule is simple: cache hits require an exact matching prefix, so place stable content first and push request-specific data (user question, retrieved snippets, volatile metadata) to the end.
Two knobs matter in production. First, prompt_cache_key can influence routing and help improve hit rates by steering similar-prefix traffic to the same cache “bucket”. Second, retention can be controlled with prompt_cache_retention (e.g., in-memory short retention) and, on supported models, extended retention such as “24h”. For observability, log usage.prompt_tokens_details.cached_tokens to measure how many prompt tokens were served from cache.
Claude: explicit cache_control breakpoints
Anthropic’s technique is more direct: you tag cacheable segments with cache_control on content blocks (typically “ephemeral”), which amounts to saying “cache up to here.” Claude builds the cache in a specified order (tools → system → messages) and matches the cached region exactly (including images and tool definitions).
Practically speaking, Claude’s design allows for up to four breakpoints, and the cache-matching step involves a bounded lookback (documented to be ~20 blocks). As a result, multi-breakpoint designs can reduce miss rates for long prompts. TTL is 5 minutes by default, with an optional 1-hour TTL at an additional cost. cache_creation_input_tokens (cache write) and cache_read_input_tokens (cache read) log how much of a prompt contributes to warm-up vs. steady-state performance.
Gemini: implicit caching plus explicit cache objects
In the Gemini API, you can generally select between implicit caching (automatic, model-dependent) or explicit caching (create a cache object, then reference it). Implicit caching is enabled by default for Gemini 2.5 models and has model-dependent minimum sizes (Flash vs. Pro thresholds, for example). Explicit caching enables you to specify a TTL (Generally defaulting to 1 hour) and reuse a large static context as a prefix across many questions.
Similarly, on Vertex AI, there is implicit and explicit caching. Requests must be of a certain minimum size (documented, e.g., 2,048 tokens), and implicit cached tokens may be eligible for large discounts, whereas explicit caching introduces storage costs.
Prompt Structure That Maximizes Cache Hit Rate
The golden rule of prompt caching: “Static-first, dynamic-last.” To maximize cache hits, structure your prompts so that the prefix (start of the prompt) contains the static and reusable parts, and the suffix (the end of the prompt) contains all the request-specific or user-provided content. Only a matching prefix can be cached; any part of the prompt that changes between requests must be excluded from the cached section. In practice, that means you should concatenate the prompt in a consistent order, for example:
- System instructions/role prompt: e.g., “You are an AI assistant tasked with …” – all the rules, guidelines, and persona descriptions that remain constant.
- Tool definitions or function schema (if using an agent): JSON or XML definitions of tools and their settings, or function signatures, which are reused each time.
- Long context or background data: e.g., an entire document, knowledge base excerpts, codebase, or a large list of examples. This can even be images or other media, if the API lets you do that - but you would include the exact same images or files in the prompt each time for caching purposes.
- Few-shot examples or dialogues: if you include example Q&A pairs or conversation history as part of the prompt, put all those static examples here in the prefix.
- (Cache breakpoint marker) – If your API requires you to indicate a place to split what should be cached and what isn’t, you would make a notation there. (For OpenAI, this is automatic; for Claude, you’d include a cache_control block at this point; for Google’s explicit caching, this is where you’d have uploaded and referenced the cached content.)
- User query or dynamic input (last): The final part of the prompt is the portion that changes each request, e.g., the latest user question or any new data. This is what comes after the cached prefix. It will not be cached (and doesn’t need to be), since it’s different every time.
Prompt Caching vs. Semantic Caching (When to Combine Both)
Note that prompt caching (also known as prefix caching) is distinct from semantic caching, which addresses a similar problem but at a different layer and in a different manner. Prompt caching, as explained here, is strictly about having the exact same prefix: it’s great for direct re-use of context. Semantic caching, by contrast, means caching at the level of user queries and responses based on meaning, even if the wording differs.
| Caching Method | Prompt Caching (Exact Prefix) | Semantic Caching (Meaning-Based) |
|---|---|---|
| What is cached | The LLM’s internal state for a prompt prefix (e.g., model context for the first N tokens). The model still generates a fresh output each time (just starting from a saved state). | The output (response) for a given input query, stored for reuse. Often involves saving the full answer text for a query or prompt. |
| Hit criterion | Exact token match of the prompt prefix. Any difference in the prefix text (or parameters like system prompt, temperature, etc.) means no hit. | Semantic similarity of the new query to a past query. Uses embeddings to find if the new question is essentially the same as one seen before (even if phrased differently). |
| Use cases | Repeated static context across many requests (long instructions, documents, tool specs). Useful in multi-turn dialogues or agent tools where the environment stays the same but questions vary. | Repeated questions from users, FAQ-style queries, or scenarios where users often ask the same thing. Great for caching complete answers to common or expensive queries, even if phrasing varies. |
| Benefits | Saves input token processing costs and reduces latency for large prompts by avoiding recomputation of the static part. The LLM still tailors the answer to the new question each time. | Can avoid an LLM call entirely if a similar query was answered before – returning a stored response instantly. This can yield order-of-magnitude speedups (responses in milliseconds) and cost reduction by skipping calls. |
| Limitations | Only works for identical prefixes; cannot help if the prompt context changes or if the cost is in the output tokens. Doesn’t handle semantically similar but not identical prompts. | Requires maintaining an external cache (database or vector index) of Q&A pairs. There’s a risk of stale answers or incorrect matches if two queries are similar in embedding but actually different in intent, so it needs careful tuning (thresholds, validation). Also, semantic caching typically doesn’t help with the prompt’s context length (it’s about reusing outputs). |
It makes sense to use prompt caching and semantic caching in tandem – sometimes called a “double caching” strategy. For instance, in a customer support chatbot you might use prompt caching to serve a large static knowledge base (so the LLM doesn’t have to re-read the manual every time it’s invoked, to reduce token load) while using semantic caching of the final answers so that if user X asks a question and later user Y asks the same thing you can serve the cached answer directly without even having to call the LLM.
Prompt caching and semantic caching operate at different layers (one inside the model’s inference process, the other outside at the application level), so they’re not mutually exclusive and can easily complement each other. Prompt caching makes each LLM call as efficient as possible, while semantic caching reduces the total number of LLM calls needed in the first place by eliminating repeats.
Measurement and ROI Checklist
How do you know if prompt caching is adding value to your application? And when is it even worth it? Here are some metrics you should track and some rules of thumb to assess your ROI:
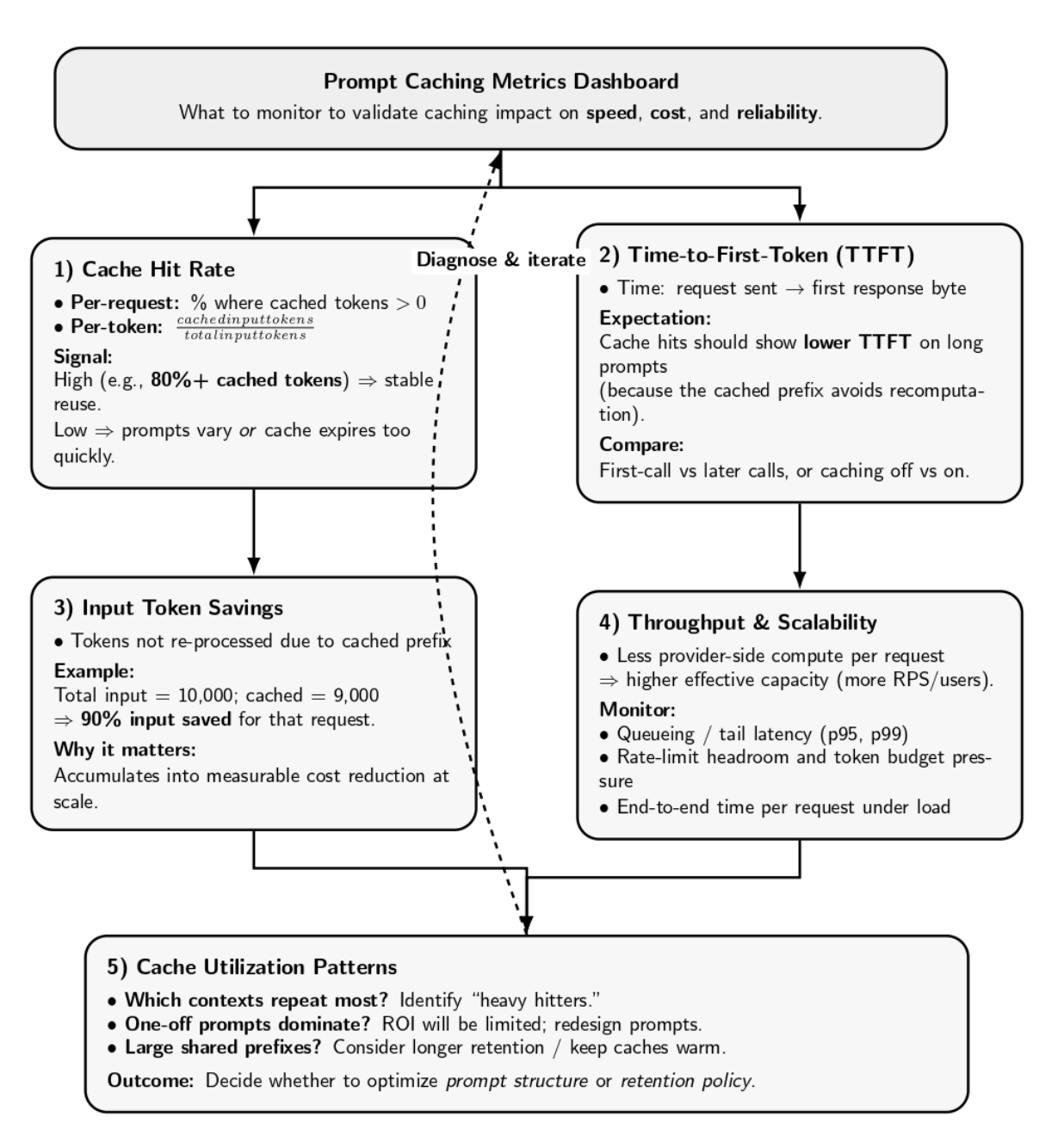
- Cache Hit Rate: Track how often your requests receive a cache hit. This can be tracked per-request (percentage of requests where cached_tokens > 0 or cache_read_input_tokens > 0), or per-token (what fraction of total input tokens came from cache). Most providers will give you the numbers necessary to calculate this – for example, OpenAI’s cached_tokens field, or Claude’s cache_read_input_tokens vs total, or Google’s cachedContentTokenCount.
A high hit rate (e.g., 80%+ of tokens from cache) is a good sign that you’re successfully reusing context most of the time. A low hit rate means either that your prompts aren’t repeating often enough, or your cache is expiring/invalidating too frequently.
- Time-to-First-Token (TTFT): Latency from sending a request to receiving the first byte of a response. This should drop significantly on long prompts since there’s no compute time for the beginning of the prompt. You can measure TTFT with and without caching (try disabling experimental caching features or comparing first-call vs later calls).
- Input Token Savings: The number of input tokens you didn’t have to process thanks to caching. If each request is 10k tokens, and 9k of them came from cache, you’ve saved 90% of the input tokens for that request. Over a large number of requests, this aggregates to real cost savings.
- Throughput and Scalability: If caching works as expected, then each individual request will use less compute on the provider side. This can help you handle more requests per second or serve more users within your rate limit. Monitor the system’s throughput and try to see if prompt caching allows you to increase it (avoid hitting token rate limits as fast, since cached tokens may not count against those limits fully; or simply because responses return faster and your application can service the next query sooner).
- Cache Utilization Patterns: Check how your cache entries are reused. Are there some large contexts that are repeated heavily? If yes, consider keeping those caches warm longer. Or are most prompts one-time only? In that case, caching might not provide a big ROI. This info can help decide whether to redesign prompts or use longer retention.
Common Pitfalls and Troubleshooting
There are three possible reasons for caching problems: (1) the prompt is not cacheable (too short or caching disabled), (2) the cached prefix is not exactly identical between calls (even 1-bit differences trigger a miss), or (3) the cache window expires or is invalidated by changing modes (tools/web/citations/images). The following table gives a systematic checklist to identify the symptoms, verify the cause, and use the most appropriate solution:
| Issue/symptom | Diagnostic checks (what to verify) | Fix / best practice (what to do) |
|---|---|---|
| No cache hits (cached tokens always 0) | 1) Prompt length clears provider threshold (e.g., OpenAI ~1024+, Vertex implicit ~2048+). 2) Prefix is byte-for-byte identical across calls. 3) Provider-specific caching is enabled on every request (e.g., Claude requires cache_control each time). | Increase prompt size past threshold (move stable docs/system text into the prefix). Make prompt construction deterministic. Log full prompts and diff them. Ensure required cache flags/markers are sent on every call. |
| Cache misses after “small” changes | Compare a known hit vs miss prompt: system text, tool schemas, JSON serialization, whitespace/newlines, timestamps/IDs, or non-fixed defaults. Check JSON key ordering and template rendering stability. | Use stable serialization (canonical JSON / fixed key order). Freeze defaults and remove dynamic fields from the cached prefix. Normalize whitespace and templating. Add a “prompt fingerprint” (hash) in logs to catch drift early. |
| Cache invalidated when switching features/modes | Did you toggle web/tools/citations, change tool definitions, add images, or edit system instructions between calls? (These often create a logically new context.) | Treat each mode/toggle combination as a separate cache “profile.” Keep toggles consistent within a session. If you must switch modes, expect a miss and warm the cache for that mode. |
| Cache expires before reuse | Time between user turns vs TTL/retention window. Do you have access to longer retention (OpenAI extended cache, Claude longer TTL, explicit cache TTL on Google)? | Choose the longest economical retention for your interaction pattern (hours-later follow-ups → extended retention). If retention cannot be extended, consider periodic lightweight refresh calls only for high-value contexts (and quantify the cost). |
| Partial prompt updates don’t behave as expected | Where is the change occurring? If you inserted/edited inside the cached prefix, it’s a new prefix (miss). If you only append after the prefix, caching should still apply. If a provider supports multiple checkpoints, are they placed correctly? | Structure prompts into stable-first blocks (system + long docs) and append volatile parts (user turns) later. Use multiple cache breakpoints/blocks where supported so independent sections can remain cacheable. Avoid inserting content mid-prefix. |
Conclusion
Prompt caching is one of the highest-ROI performance levers for LLM applications, because it reduces redundant prefill computation without changing model quality. The basic takeaways are easy: standardize & version your prompt prefix, keep dynamic inputs at the end, and instrument cache-read signals (cached tokens, cache read/write counters) alongside TTFT and cost. Build that out, and you can layer on top a semantic caching strategy to eliminate entire calls. This will result in a “double caching” pattern that can win both unit economics and user-perceived responsiveness at scale.
References
- Prompt caching
- Prompt caching
- Context caching overview
- Prompt caching for faster model inference
- Context caching
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.