At Browser Use I spend a lot of time deciding what model to use. It’s not easy to choose between LLMs, agent parameters, or compare two different versions of Browser Use and tell which one is better.
To truly understand our agent performance, we built a suite of internal tools for evaluating our agent in a standardized and repeatable way so we can compare versions and models and continuously improve. We take evaluations seriously. As of now, we have over 600,000 tasks run in testing.
Today we are releasing our first open source benchmark.
The Tasks
Existing browser benchmark task sets all have strengths and weaknesses. All tasks fall somewhere in the tradeoff between interpretability and realism.
On the interpretable end are tasks with synthetic websites that can determinis…
At Browser Use I spend a lot of time deciding what model to use. It’s not easy to choose between LLMs, agent parameters, or compare two different versions of Browser Use and tell which one is better.
To truly understand our agent performance, we built a suite of internal tools for evaluating our agent in a standardized and repeatable way so we can compare versions and models and continuously improve. We take evaluations seriously. As of now, we have over 600,000 tasks run in testing.
Today we are releasing our first open source benchmark.
The Tasks
Existing browser benchmark task sets all have strengths and weaknesses. All tasks fall somewhere in the tradeoff between interpretability and realism.
On the interpretable end are tasks with synthetic websites that can deterministically confirm if the agent succeeds. But synthetic sites don’t capture the bizarre reality and diversity of how real websites work, so we avoid them.
A good middle ground is web tasks that involve researching verifiable information, often involving multiple steps (like BrowseComp and GAIA) and comparing the answer to ground truth.
The end of the spectrum that most represents real user tasks involves finding real-time information or following complex workflows on various pages (Mind2Web 2, WebBench). The challenge here is judging them accurately at scale.
Tasks left out of evaluations are those that make real changes to websites (like creating a post) or require authentication. There has yet to be an economical solution for running these at scale.
Another challenge is difficulty. Many tasks have become trivial to modern browser agents, while others simply are not completable. For our benchmark, we selected 100 of the best tasks from existing open source benchmarks. We chose WebBench, Mind2Web, GAIA, and BrowseComp for a mix of verifiable and real-time tasks. We also added 20 tasks on a custom site to test the hardest browser interactions, such as iframe inception, clicking and dragging, etc.
| Source | Tasks | Description |
|---|---|---|
| Custom | 20 | Page interaction challenges |
| WebBench | 20 | Web browsing tasks |
| Mind2Web 2 | 20 | Multi-step web navigation |
| GAIA | 20 | General AI assistant tasks (web-based) |
| BrowseComp | 20 | Browser comprehension tasks |
We approached the difficulty problem with the following method: we ran all tasks many times with different LLMs, agent settings, and agent frameworks. Each was evaluated by our LLM judge for success, with flags for tasks judged impossible or where the agent was very close.
We removed tasks completed most of the time for being too easy, and ones majority voted impossible and never completed for being unreachable. Among the remaining tasks, the most challenging and interesting ones were hand-selected and independently verified to be possible. The resulting set contains only very hard but possible tasks.
The Judge
Judging task traces is a critical part of any benchmark. When tasks involve real websites and real information, there is no deterministic way to check if the agent succeeded.
At the scale and speed needed to base product direction on evaluations, we must use an LLM as the judge. To ensure consistency across models, the same LLM, prompt, and inputs must be used.
We have iterated across many judge frameworks over the last year on our internal evaluation platform. The way to evaluate a judge is to run it on task traces that were judged personally and meticulously by our team and compare the results. This tells us how aligned the judge is with our own judgements. We hand labeled 200 task traces and used accuracy on this set as our core metric.
Initial results settled on GPT-4o as the most human-aligned judge, as found by the original Mind2Web paper. However, when gemini-2.5-flash released, we found it had better alignment and became our new judge.
For prompting, we found that simple trumps complex, and context is king. Many benchmarks use a rubric system, but we found better accuracy demanding a true or false verdict. With rubrics, LLMs tend to highlight a few positives and negatives and give a middling score even in complete success or utter failure.
Our final judge achieved 87% alignment with our human judgements, only differing on partial successes or technicalities.
The Results
Here is a comparison of performance and throughput on this benchmark for the most used models on Browser Use Cloud. We find it concerning that many AI agent benchmarks do not include error bars or variance estimations. We have run each evaluation multiple times and shown standard error bars.
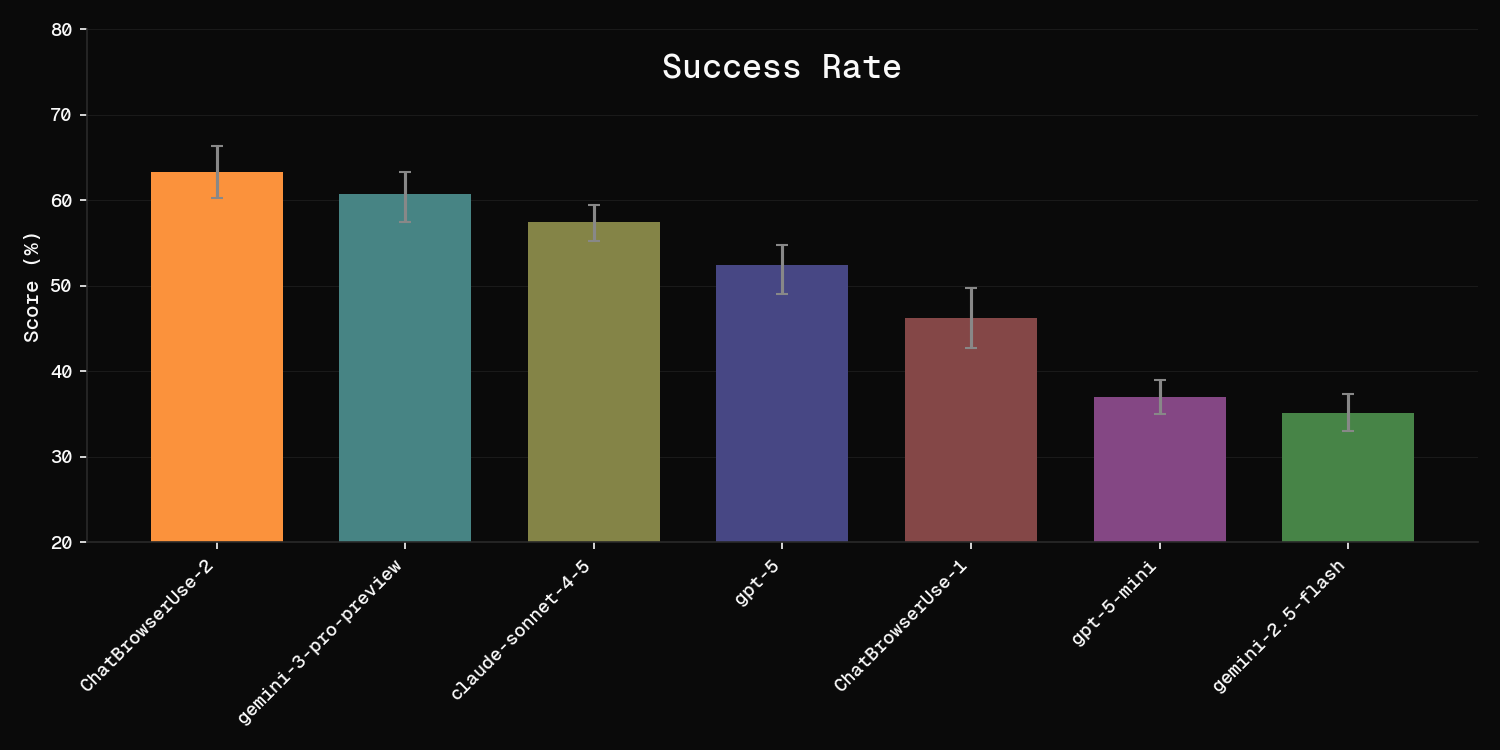
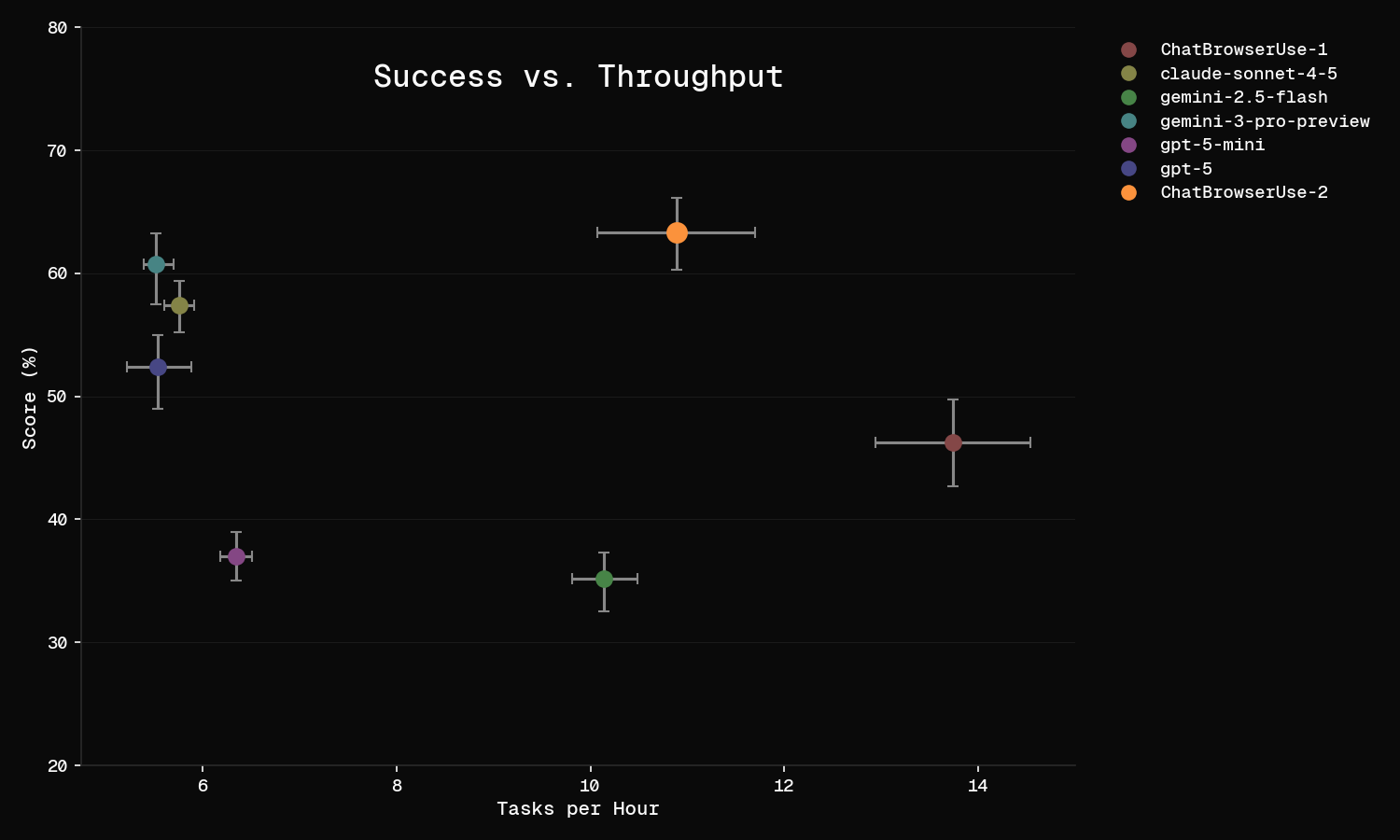
The strongest model today is our new ChatBrowserUse 2 API, which is specially optimized for use in our framework.
However, all models on this plot are very strong, and even the lowest scoring model (gemini-2.5-flash at 35%) is respectable on these hard tasks. The fact that recent models have surpassed 60% on this benchmark is impressive. We may need to collect even harder tasks for a new benchmark soon.
Using the Benchmark
This benchmark is open source at github.com/browser-use/benchmark. We want it to be easy to use and modify. Our results for ChatBrowserUse 2 can be replicated by running run_eval.py.
However, these evaluations are not suitable for an everyday user. A single run through these 100 complex tasks on the basic Browser Use plan with concurrency limited to 3 will take roughly three hours and cost $10. Using more expensive models like claude-sonnet-4-5 will take roughly twice as long and incur costs of nearly $100 in API calls.
We hope this benchmark can enable LLM providers to test new models on complex real world agentic browsing tasks and use the results to improve their models. If you would like to inquire about running these evaluations at a larger scale, please contact support@browser-use.com