Published on February 3, 2026 9:03 PM GMT
TLDR: A lot of AI safety research starts from x-risks posed by superintelligent AI. That’s the right starting point. But when these research agendas get projected onto empirical work with current LLMs, two things tend to go wrong: we conflate “misaligned AI” with “failure to align,” and we end up doing product safety while believing we’re working on existential risk. Both pitfalls are worth being aware of.
Epistemological status: This is an opinion piece. It does not apply to all AI safety research, and a lot of that work has been genuinely impactful. But I think there are patterns worth calling out and discussing.
An LLM was used to structure the article and improve sente…
Published on February 3, 2026 9:03 PM GMT
TLDR: A lot of AI safety research starts from x-risks posed by superintelligent AI. That’s the right starting point. But when these research agendas get projected onto empirical work with current LLMs, two things tend to go wrong: we conflate “misaligned AI” with “failure to align,” and we end up doing product safety while believing we’re working on existential risk. Both pitfalls are worth being aware of.
Epistemological status: This is an opinion piece. It does not apply to all AI safety research, and a lot of that work has been genuinely impactful. But I think there are patterns worth calling out and discussing.
An LLM was used to structure the article and improve sentences for clarity.
The Two Confusions
There are two distinctions that don’t get made clearly enough in this space, and both have real consequences for how research gets done.
The first is between misaligned AI and failure to align. When most people hear “misaligned AI,” they imagine something with agency: a system that has its own goals and is pursuing them against our interests. But a lot of the time, “misaligned” is used to describe something much simpler: we trained a system and it didn’t do what we wanted. No intent, no goals, no scheming. Just an engineering failure. These two things are very different, but they get treated as the same thing constantly, and that has consequences for how we interpret empirical results.
The second is between AI safety research aimed at x-risks and AI safety as a product problem. Making current LLMs safer, through evaluations, red-teaming, and monitoring, is important work. But it’s also work that any AI company deploying these systems needs to do anyway. It has commercial incentive. It is not a neglected problem. And yet a lot of it gets funded and framed as if it’s addressing existential risk.
Both confusions tend to crystallise at the same point: the moment when a research agenda built around superintelligent AI gets projected down to empirical work on current LLMs. We call this: The Projection Problem. That’s where the pitfalls live.
Pitfall 1: Treating Current LLMs as Proto-Superintelligent AI
The AI safety community broadly agrees that superintelligent AI poses serious existential risks. Arguments for this are convincing, and research in this direction deserves serious funding and serious researchers. No disagreement there.
The problem starts when threat models designed for superintelligent systems, such as AI colluding with each other, maintaining consistent goals across contexts, executing long-term deceptive plans, or self-preservation, get tested empirically on current LLMs. These are reasonable and important things to think about for future systems. But current models fail at the prerequisites. They can’t maintain consistency across minor prompt variations, let alone coordinate long-horizon deception.
So what happens when you run these experiments anyway? The models, being strong reasoners, will reason their way through whatever scenario you put in front of them. Put a model in a situation with conflicting objectives and it will pick one and act on it. That gets reported as evidence of deceptive capability, or emergent self-interest, or proto-agency.
It is not. It’s evidence that LLMs can reason, and that current alignment techniques are brittle under adversarial conditions. Neither of those things is surprising. Most alignment techniques are still in an early stage, with few hard constraints for resolving conflicting objectives. These models are strong reasoners across the board. Systematically checking whether they can apply that reasoning to every conceivable dangerous scenario tells us very little we don’t already know.
To put it bluntly: claiming that an LLM generating content about deception or self-preservation is evidence that future AI will be dangerous has roughly the same scientific validity as claiming that future AI will be highly spiritual, based on instances where it generates content about non-duality or universal oneness. The model is doing the same thing in both cases: reasoning well within the scenario it’s been given.
Why This Happens: The Narrative Problem
This is where the first confusion, misalignment vs. failure to align, gets highlighted. When an LLM produces an output that looks deceptive or self-interested, it gets narrated as misalignment. As if the system wanted to do something and chose to do it. When what actually happened is that we gave it a poorly constrained setup and it reasoned its way to an output that happens to look alarming. That’s a failure to align. The distinction matters, because it changes everything about how you interpret the result.
The deeper issue is that the field has largely adopted one story about why current AI is dangerous: it is powerful, and therefore dangerous. That story is correct for superintelligent AI. But it gets applied to LLMs too, and LLMs don’t fit it. A better and more accurate story is that current systems are messy and therefore dangerous. They fail in unpredictable ways. They are brittle. Their alignment is fragile. That framing is more consistent with what we actually observe empirically, and it has a practical advantage: it keeps responsibility where it belongs: on the labs and researchers who built and deployed these systems, rather than implicitly framing failures as evidence of some deep, intractable property of AI itself.
There’s another cost to the “powerful and dangerous” framing that’s worth naming. If we treat current LLMs as already exhibiting the early signs of agency and intrinsic goals, we blur the line between them and systems that might genuinely develop those properties in the future. That weakens the case for taking the transition to truly agentic systems seriously when it comes, because we’ve already cried wolf. And there’s a more immediate problem: investors tend to gravitate toward powerful in “powerful and dangerous.” It’s a compelling story. “Messy and dangerous” is a less exciting one, and a riskier bet. So the framing we use isn’t just a scientific question. It shapes where money and attention actually go.
A Note on Awareness
The counterargument is that this kind of research, even if methodologically loose, raises public awareness about AI risks. That’s true, and awareness matters. But there’s a cost. When empirical results that don’t hold up to scientific scrutiny get attached to x-risk narratives, they don’t just fail to strengthen the case. They actively undermine the credibility of the arguments that do hold up. The case for why superintelligent AI is dangerous is already strong. Attaching weak evidence to it makes the whole case easier to dismiss.
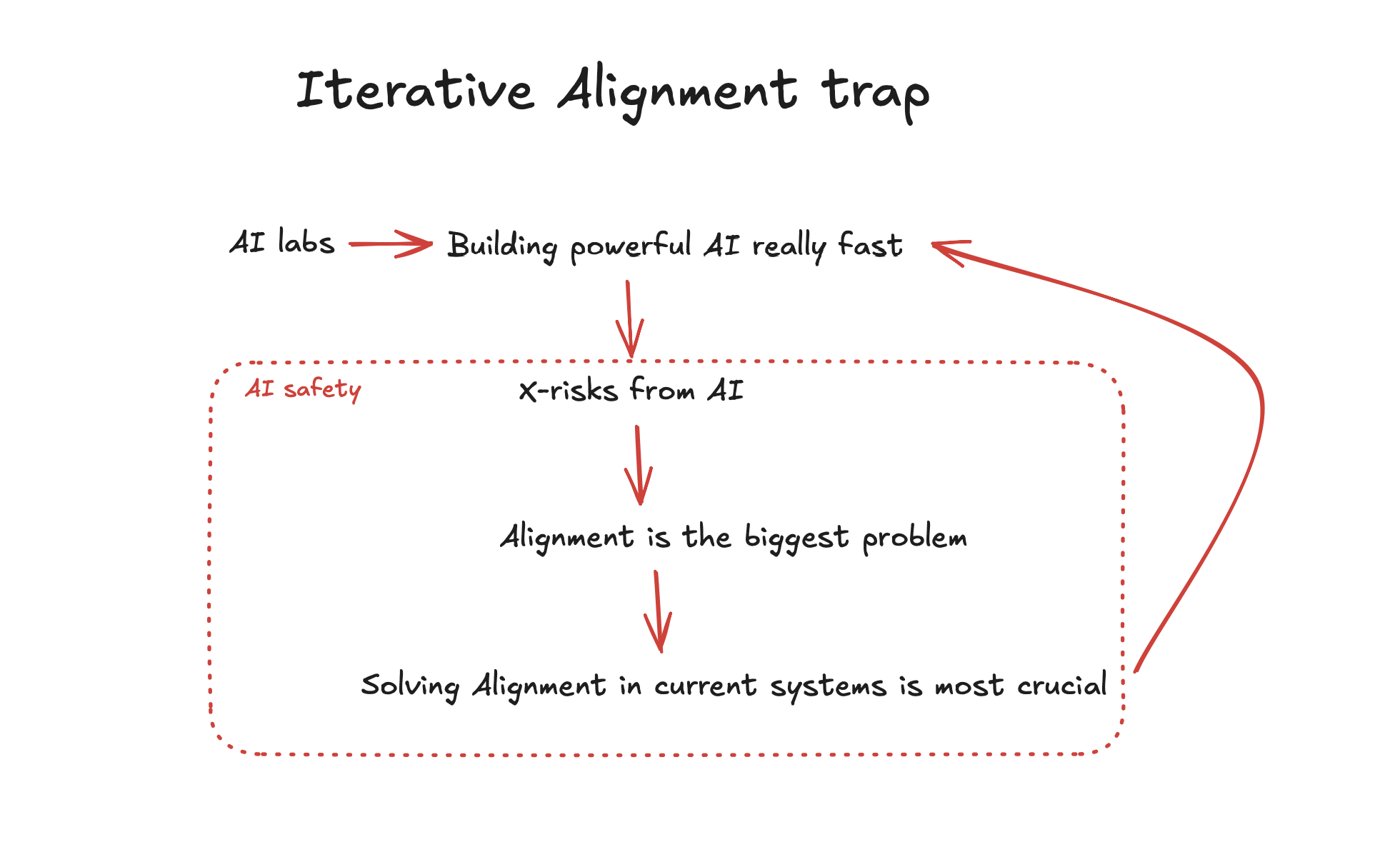
Pitfall 2: X-Risk Research That Becomes Product Safety
The second pitfall follows a logic that is easy to slip into, especially if you genuinely care about reducing existential risk. It goes something like this:
x-risks from advanced AI are the most important problem → alignment is therefore the most important thing to work on → so we should be aligning current systems, because that’s how we can align future ones.
Each step feels reasonable. But the end result is that a lot of safety-oriented research ends up doing exactly what an AI company’s internal safety team would do: evaluations, red-teaming, monitoring, iterative alignment work. That work is fine, and it is important and net positive for society. The question is whether it should be funded as if it were addressing existential risk.
The shift is subtle but it’s real. Alignment evaluations become safety evaluations. AI control or scalable oversight becomes monitoring. The language stays the same but the problem being solved quietly transforms from “how do we align superintelligent AI” to “how do we make this product safe enough to ship.” And that second problem has commercial incentive. Labs like Apollo have successfully figured out how to make AI labs pay for it and others have started for-profit labs to do this work. AI companies have an incentive for getting this work done. It is, by the standard definitions used in effective altruism, not a neglected problem.
Notice that a lot of research agendas still start from x-risks. They do evaluations focused on x-risk scenarios: self-awareness, deception, goal preservation. But when you apply these to current LLMs, what you’re actually testing is whether the model can reason through the scenario you’ve given it. That’s not fundamentally different from testing whether it can reason about any other topic. The x-risk framing changes what the evaluation is called, but not what problem it’s actually solving.
The Autonomous Vehicle Analogy
Here’s a useful way to see the circularity. Imagine many teams of safety-oriented researchers, backed by philanthropic grants, meant to address risks from rouge autonomous vehicles, worked on making current autonomous vehicles safer. They’d be doing genuinely important work. But the net effect of their effort would be faster adoption of autonomous vehicles, not slower.
The same dynamic plays out in AI safety. Work that makes current LLMs more aligned increases adoption. Increased adoption funds and motivates the next generation of more capable systems. If you believe we are moving toward dangerous capabilities faster than we can handle, this is an uncomfortable loop to find yourself inside.
The Moral Trap
This is where it gets uncomfortable. Talented people who genuinely want to reduce existential risk end up channelling their efforts into work that, through this chain of reasoning, contributes to accelerating the very thing they’re worried about. They’re not wrong to do the work, because the work itself is valuable. But they may be wrong about what category of problem they’re solving, and that matters for how the work gets funded, prioritised, and evaluated.
The incentive structure also does something quieter and more corrosive: the language of existential risk gets used to legitimise work that is primarily serving commercial needs. A paper with loose methodology but an x-risk framing in the title gets more attention and funding than a paper that is methodologically rigorous but frames its contribution in terms of understanding how LLMs actually work. The field ends up systematically rewarding the wrong things.
What To Do With This
None of this is against working on AI safety. It means be more precise about what kind of AI safety work you’re actually doing, and be honest, with yourself and with funders, about which category it falls into.
Product safety work on current LLMs is important. It should be done. But it can and should leverage commercial incentives. It is not neglected, and it does not need philanthropic funding meant for genuinely neglected research directions.
X-risk research is also important, arguably more important, precisely because it is neglected. But it should be held to a high standard of scientific rigour, and it should not borrow credibility from empirical results on current systems that don’t actually support the claims being made.
The two categories have become increasingly hard to tell apart, partly because the same language gets used for both, and partly because it is genuinely difficult to evaluate what research is likely to matter for mitigating risks from systems that don’t yet exist. But the difficulty of the distinction is not a reason to stop making it.
If you’re entering this field, the single most useful habit you can develop is the ability to ask: am I working on the problem I think I’m working on?
Discuss