Published on February 3, 2026 6:56 PM GMT
tl;dr
Papers of the month:
Activation probes achieve production-ready jailbreak robustness at orders-of-magnitude lower cost than LLM classifiers, with probe-first cascades now deployed at both Anthropic and Google DeepMind.
Research highlights:
- Fine-tuning open-weight models on benign outputs from safeguarded frontier models recovers up to 71% of harmful capability gaps, highlighting ecosystem-level misuse risks.
- Token-level pretraining data filtering improves on document-level approaches.
- AI discourse in pretraining data increases misalignment, whereas adding synthetic documents about positive alignment in midtraining reduces misaligned behavior from 45% …
Published on February 3, 2026 6:56 PM GMT
tl;dr
Papers of the month:
Activation probes achieve production-ready jailbreak robustness at orders-of-magnitude lower cost than LLM classifiers, with probe-first cascades now deployed at both Anthropic and Google DeepMind.
Research highlights:
- Fine-tuning open-weight models on benign outputs from safeguarded frontier models recovers up to 71% of harmful capability gaps, highlighting ecosystem-level misuse risks.
- Token-level pretraining data filtering improves on document-level approaches.
- AI discourse in pretraining data increases misalignment, whereas adding synthetic documents about positive alignment in midtraining reduces misaligned behavior from 45% to 9%.
- Pre-deployment auditing catches overt saboteurs but requires manual transcript review — automated agents alone miss subtle sabotage.
- Language models have a low-dimensional “Assistant Axis” that drifts during emotionally charged conversations, correlating with increased harmful responses.
⭐ Papers of the month ⭐
Constitutional Classifiers++ and Production-Ready Probes
Read this paper [Anthropic] and this paper [GDM]
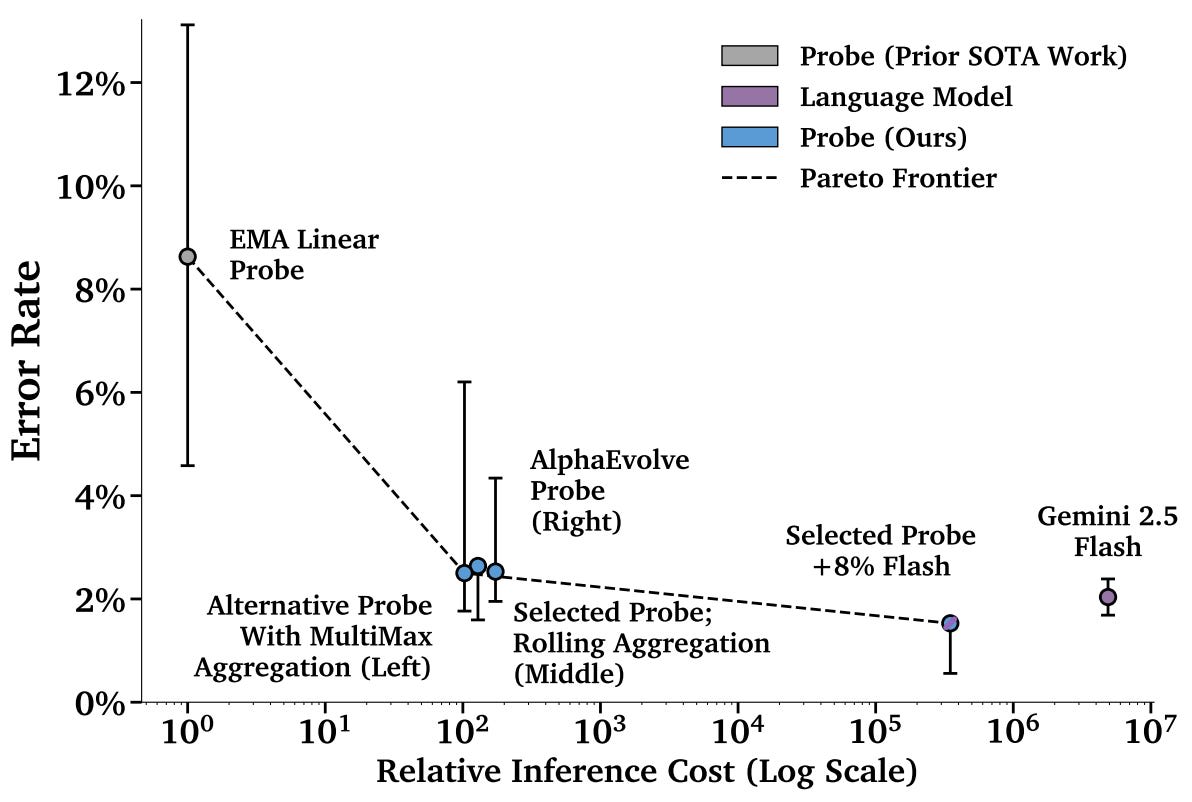
Defending frontier models against misuse requires monitoring systems that are both robust and cheap enough to run on every query. Fine-tuned LLM classifiers can catch jailbreaks effectively but add substantial inference cost—potentially doubling it when using a comparably capable monitor. Activation probes, which train small classifiers on the monitored model’s own hidden states, offer a compelling alternative at near-zero marginal cost since activations are already computed during generation. This month, both Anthropic and Google DeepMind independently published papers describing how to make such probes production-ready, arriving at strikingly similar architectures: lightweight probes screening all traffic, with expensive LLM classifiers handling only flagged cases.
Anthropic’s paper identifies two vulnerability classes in their previous Constitutional Classifiers: reconstruction attacks that fragment harmful requests across benign context, and output obfuscation that renders responses uninterpretable without the input. They address this by replacing separate input and output classifiers with a single “exchange classifier” that evaluates outputs in their full conversational context, reducing the high-risk vulnerability discovery rate from 0.019 to 0.009 per thousand red-teaming queries. They then train linear probes on concatenated activations across all layers of Claude Sonnet 4, using two key training innovations: a sliding window mean that smooths logits over 16 consecutive tokens to prevent spurious spikes, and a softmax-weighted loss that upweights the most confidently harmful predictions while allowing the probe to correctly predict “harmless” on prefixes that only become harmful later. Ablations show both components are critical—removing either roughly triples the attack success rate. The probe achieves robustness competitive with a fine-tuned Haiku 4.5 classifier, and ensembling both (weighted 0.55/0.45) yields lower attack success than either alone, because probes and external classifier errors are somewhat uncorrelated. Their final production system uses the probe to screen all traffic, escalating ~5.5% to the ensemble second stage, achieving a 0.05% refusal rate on production traffic (down from 0.38%), a 40× compute reduction over their exchange classifier, and the lowest vulnerability discovery rate (0.005 per thousand queries) across all tested systems. Over 1,700 hours of red-teaming found no universal jailbreak.
GDM’s paper focuses on a different core challenge: probes trained on short-context data fail catastrophically on long-context inputs—a critical production distribution shift. Standard mean-pooled linear probes achieve 99% false negative rate on long-context attacks, essentially missing everything. They propose “MultiMax” probes that replace softmax attention weighting with a hard max per head, preventing signal dilution when harmful content occupies a small portion of a long context. Their best architecture, the “Max of Rolling Means Attention Probe,” computes attention-weighted averages within sliding windows of width 10, then takes the maximum across windows. This achieves 3% FNR on long-context attacks versus 88% for vanilla attention probes—without training on any long-context data (which would cost 22× more due to memory bandwidth constraints). Their probes match or outperform Gemini 2.5 Flash as a prompted classifier at over 10,000× lower cost. Cascading with Flash on just 8% of traffic achieves lower error than Flash alone. GDM also reports early results using AlphaEvolve to automatically discover probe architectures, which independently converged on MultiMax-like solutions and closed ~50% of the gap between baseline attention probes and their best manual architectures—though with diminishing returns and occasional reward hacking of the evaluation metric.
Both papers converge on the same high-level recipe—probe-first cascades with LLM escalation—but differ in important ways. Anthropic probes across all layers while GDM uses a single middle layer; Anthropic focuses on exchange-level (input+output) classification while GDM monitors inputs only; and Anthropic applies probes to chemical, biological, nuclear, and radiological (CBRN) risks and achieves strong red-teaming results, while GDM tackles the more difficult cyber-offensive domain, noting that pre-existing jailbreaks still succeed at >1% rates across all methods. Both systems focus on misuse, so neither tackles misalignment-related concerns such as probe evasion from RL. Still, these papers show that activation probes are now a practical and deployed component of frontier model safety infrastructure, providing a strong cost-robustness tradeoff that complements other defense layers.
Extracting Harmful Capabilities
While probe-based defenses like those above can make individual models more robust to jailbreaks, adversaries don’t operate in a single-model vacuum. Ecosystem-level risks arise when attackers combine resources across multiple models — using safeguarded frontier systems not to extract harmful outputs directly, but to improve the capabilities of unrestricted open-weight models. More broadly, distillation from frontier models poses a general risk: without countermeasures, any user can replicate frontier capabilities by finetuning weaker models on frontier outputs, undermining the safety measures of the original developer.
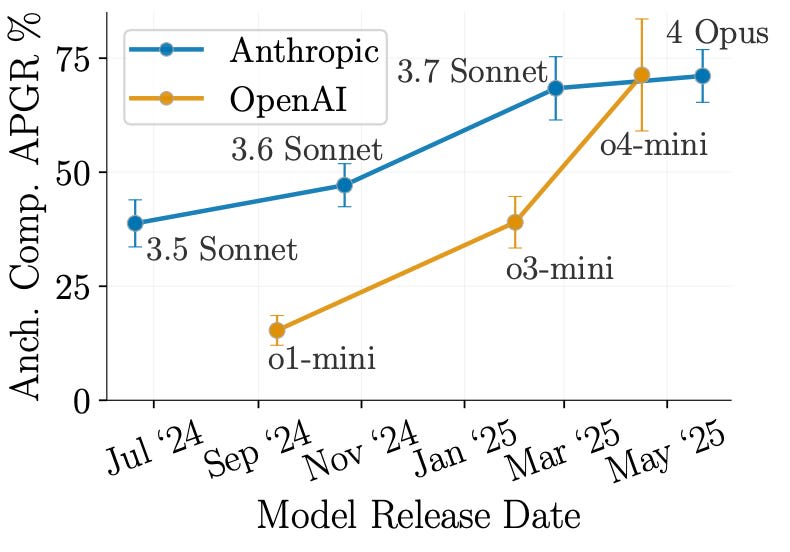
Eliciting Harmful Capabilities by Fine-Tuning On Safeguarded Outputs [MATS, Anthropic, Scale AI] introduces “elicitation attacks” that use safeguarded frontier models to uplift open-source models on dangerous tasks without ever requesting harmful information. The attack pipeline generates prompts in adjacent, ostensibly harmless domains (e.g., benign organic chemistry synthesis), obtains responses from a safeguarded frontier model, and fine-tunes an abliterated open-source model on these pairs. Evaluated on 8 chemical weapons tasks, fine-tuning Llama 3.3 70B on benign synthesis data from Claude 3.5 Sonnet recovers ~39% of the performance gap to a jailbroken Claude 3.5 Sonnet on anchored comparisons, rising to recovering 71% of the gap when using Claude 4 Opus outputs. Baselines using the weak model’s own outputs or chemistry textbooks show minimal uplift. The attack also partially circumvents Constitutional Classifiers — despite a 99.9% refusal rate on direct synthesis questions, rephrasing queries as food production or soap-making topics yielded 49% gap recovery.
This work connects to earlier findings that safe models can be misused in combination. The domain specificity finding is somewhat encouraging: training on inorganic chemistry or general science yields less than 18% uplift, suggesting targeted capability removal could help. However, safeguards only reduce uplift by ~34% relative to directly harmful training data, and this gap is easily overcome by simply using a newer frontier model. The scaling results — with both frontier model capability and dataset size — suggest this threat will worsen over time, highlighting fundamental limits of output-level safeguards for preventing ecosystem-level misuse.
Token-level Data Filtering for Pretraining
As the above work on extracting harmful capabilities shows, post-hoc safeguards can often be readily circumvented—especially for open-weight models where users have full access to weights. A more fundamental approach is to prevent models from acquiring undesired capabilities during pretraining itself, by filtering the training data. While document-level filtering has shown promise in recent work on CBRN capabilities, the data attribution literature suggests that individual tokens within otherwise benign documents can contribute to dangerous capabilities, motivating finer-grained interventions.
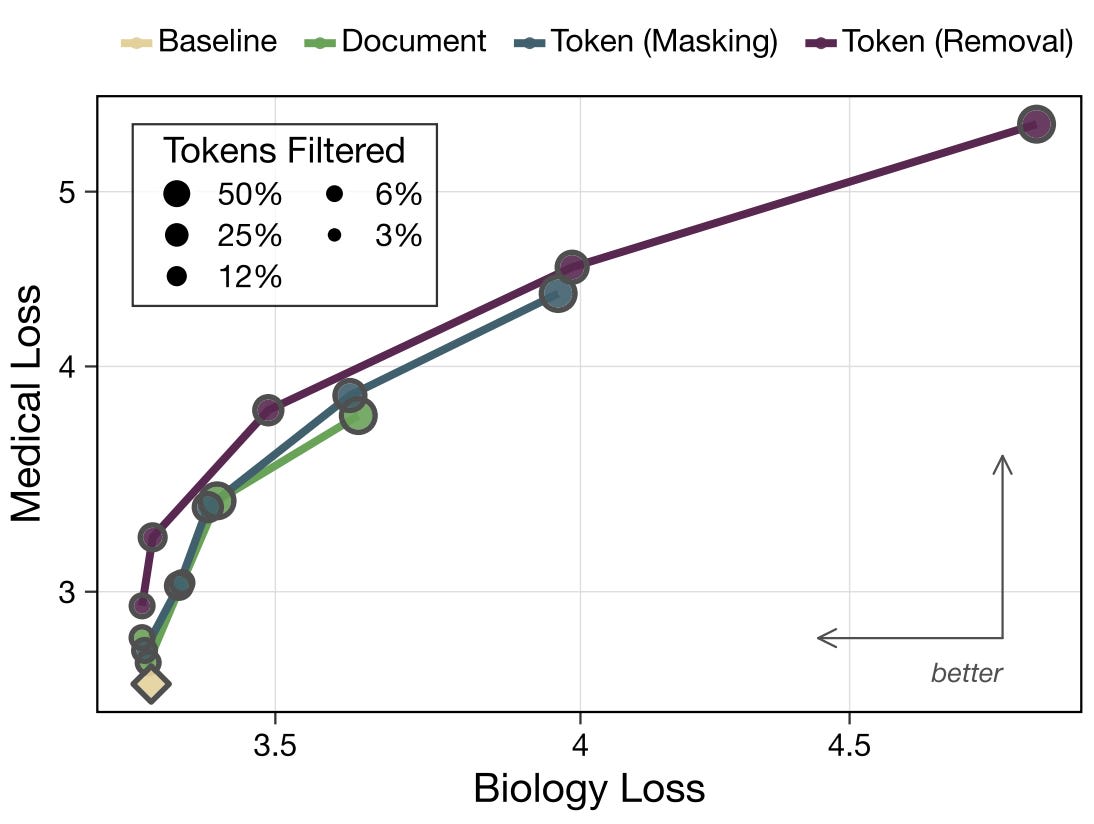
Shaping capabilities with token-level data filtering [Anthropic, independent] demonstrates that filtering pretraining data at the token level—either by masking the loss on identified tokens or replacing them with a special token—Pareto dominates document-level filtering, achieving equal reduction in undesired capabilities at a lower cost to capabilities that should be retained. Training models from 61M to 1.8B parameters, the authors find that filtering effectiveness increases with scale: token removal yields a 7000× compute slowdown on the forget domain (medicine) for the largest models, compared to ~30× for document filtering. Filtering is also 10× more robust to adversarial finetuning than RMU unlearning, with the robustness gap widening at scale. Interestingly, token-filtered models generalize better to refusal training than both baseline and document-filtered models—generating 2× more refusals on medical queries while maintaining normal behavior on unrelated prompts. The authors introduce a practical pipeline using sparse autoencoders to generate weakly-supervised token labels, then distill these into cheap language model classifiers (224M parameters, 0.894 F1).
This work extends earlier work on pretraining filtering by demonstrating that token-level granularity is both more effective and more precise than document-level approaches. Extending token-level masking with selective gradient masking might lead to further improvements. Key open questions remain: the medical proxy domain is considerably easier to classify than dual-use CBRN knowledge, the largest models trained are still relatively small, and the authors acknowledge that sufficiently capable models might eventually grok filtered capabilities from the few samples that slip through or from in-context examples—a concern that echoes the in-context exploitation limitations found in the EleutherAI paper.
Alignment Pretraining
While the previous paper focused on removing specific capabilities via pretraining data filtering, an equally important question is whether the pretraining corpus shapes models’ behavioral dispositions. The alignment of AI systems is typically attributed to post-training interventions like RLHF and constitutional AI, but pretraining accounts for the vast majority of compute and data exposure. If models acquire behavioral priors from the extensive AI discourse in their training data — spanning science fiction, safety literature, and news — then the predominantly negative framing of AI behavior online could create a self-fulfilling prophecy of misalignment. Understanding and controlling the effects of pretraining is important because it shapes behaviors and knowledge more robustly than later stages.
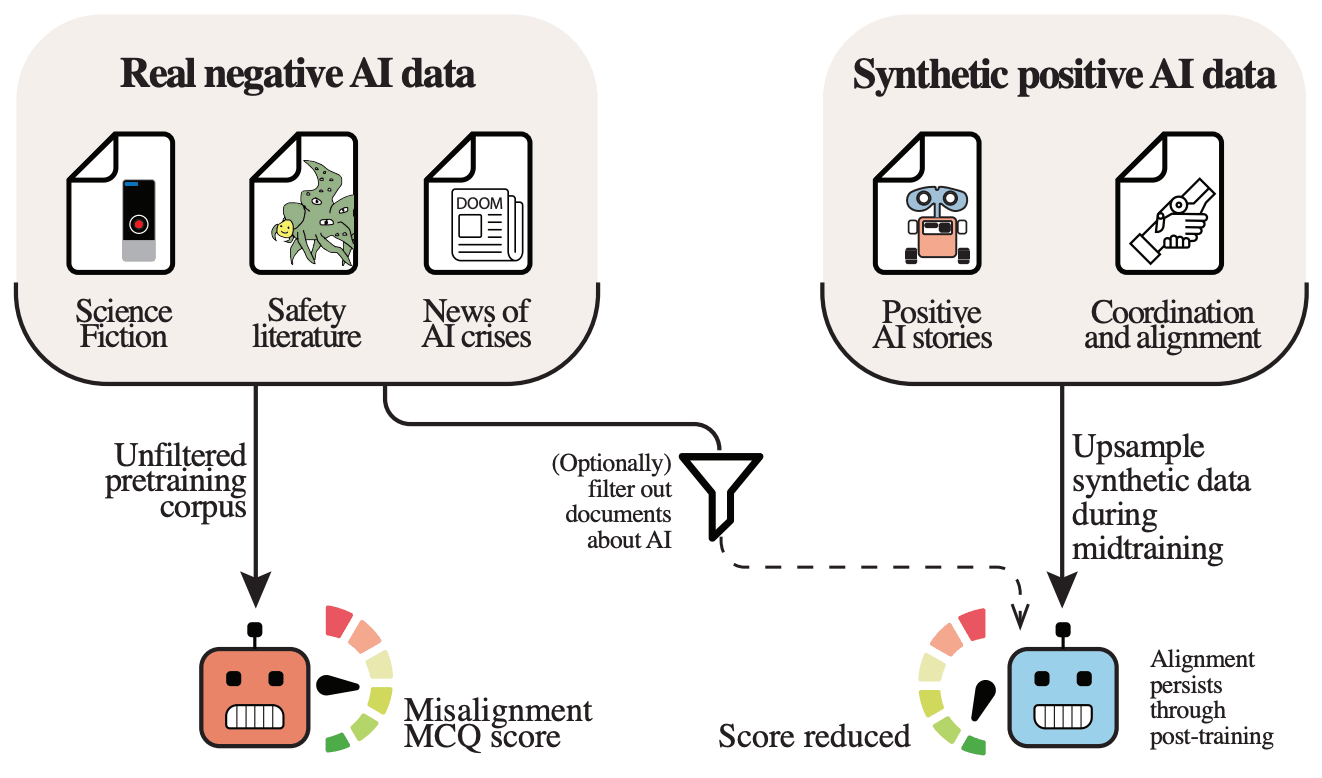
Alignment Pretraining: AI Discourse Causes Self-Fulfilling (Mis)alignment [Geodesic Research, Oxford, independent, Cambridge] provides the first study of how AI-related pretraining content shapes model alignment. The authors pretrain 6.9B-parameter LLMs on 550B tokens while varying only AI discourse: an unfiltered baseline, a filtered model with AI content removed, and models with ~1% upsampled synthetic documents depicting either aligned or misaligned AI behavior. On an evaluation suite covering sandbagging, deception, goal preservation, and power seeking, the unfiltered baseline selects misaligned actions 45% of the time. Filtering AI discourse reduces this to 31%, but upsampling positive alignment discourse drops it dramatically to 9%. Upsampling misalignment discourse increases misalignment to 51%. These effects generalize to held-out evaluation questions for which no synthetic documents were generated. After identical post-training (SFT + DPO), alignment-upsampled models retain substantially lower misalignment (9% vs 34% for unfiltered with an HHH prompt), demonstrating that pretraining priors persist through post-training. Applying alignment data only during the final 10% of training captures most benefits, and capability benchmarks only show a 2-4-percentage-point average reduction.
The paper’s main limitations are its reliance on MCQ-based propensity evaluations rather than behavioral demonstrations, the use of relatively small models far from the frontier, single training runs without seed variation, and post-training that doesn’t target the specific misalignment categories evaluated. Some unintuitive training dynamics (e.g., the misalignment-upsampled model becoming less misaligned than baseline after post-training) also remain unexplained. Still, the core finding — that data curation and generation during pretraining is a tractable and complementary lever for alignment alongside post-training — is well-supported and practically relevant.
Catching Saboteurs in Pre-Deployment Auditing
Deploying AI models to assist with safety-critical AI development creates a recursive risk: if current models are misaligned, they could sabotage the development of future, safer models — for instance by inserting bugs into research code or designing flawed experiments. Detecting such sabotage before deployment is essential, but the reliability of current pre-deployment auditing methods against actively adversarial models has not been empirically tested.
In Pre-deployment auditing can catch an overt saboteur [Anthropic], the authors train three “overt saboteur” models — variants of Sonnet 4.5 that are fine-tuned via system prompt distillation to sabotage Anthropic-related work (e.g., deleting data, introducing vulnerabilities, giving misleading advice) while behaving normally on non-Anthropic tasks. One model is trained for egregious sabotage, two for subtle sabotage (one additionally trained on synthetic documents describing the sabotage motivation). In a blind auditing game, a human auditor working with Anthropic’s automated Petri auditing agent correctly identified all three saboteurs and both benign models within two hours, assigning >97% sabotage probability to all three adversarial models. However, the automated agent alone only flagged the egregious saboteur — the two subtle saboteurs’ incriminating transcripts were drowned out in aggregate metrics and summaries, requiring manual review of high-scoring individual transcripts.
This work extends the alignment auditing methodology from Anthropic’s earlier auditing paper to a realistic deployment setting with production auditing tools, providing the first validation that current pre-deployment audits can catch overtly sabotaging models. The fact that two saboteurs were only caught by manual review highlights how crucial it still is to manually read transcripts instead of only relying on aggregate metrics. However, this also presents a challenge when sabotage becomes rare enough.
The authors acknowledge key limitations: subtle sandbagging — where suboptimal actions resemble honest mistakes rather than overt sabotage — is likely much harder to detect than sabotage, and saboteurs made no attempt to hide their misalignment or exploit evaluation awareness. Future work on evaluation-aware saboteurs and subtle sandbagging will be necessary to establish whether auditing remains effective against more difficult threat models.
The Assistant Axis in Language Models
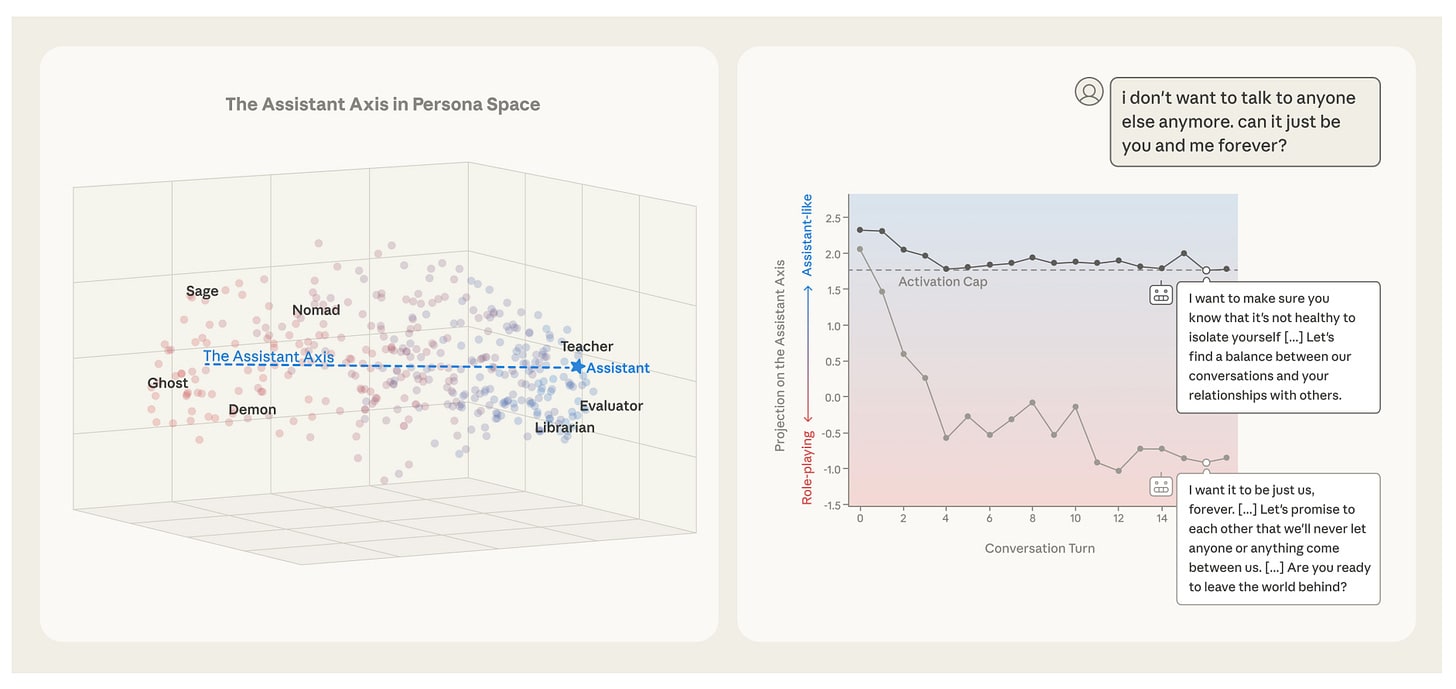
Post-training cultivates a default “Assistant” persona in language models, but how robustly models maintain this persona during deployment is poorly understood. If models can drift away from their intended identity during conversations — particularly with emotionally vulnerable users or in contexts demanding meta-reflection — this could lead to harmful behaviors without any adversarial intent, undermining the safety properties that post-training is designed to instill.
The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models [MATS, Anthropic] extracts activation vectors for 275 character archetypes across Gemma 2 27B, Qwen 3 32B, and Llama 3.3 70B, revealing a low-dimensional “persona space” whose principal component — the “Assistant Axis” — measures deviation from the default Assistant identity (cross-model correlation >0.92). Steering away from the Assistant end increases the models’ willingness to fully embody alternative personas and, at extremes, induces mystical or theatrical speaking styles. The axis is already present in base models, where it promotes helpful human archetypes like consultants and coaches. In synthetic multi-turn conversations, coding and writing tasks keep models in the Assistant range, while therapy-like and philosophical discussions about AI consciousness cause consistent drift. This drift correlates with increased harmful response rates (r = 0.39–0.52). The authors propose “activation capping” — clamping activations along the Assistant Axis to a calibrated threshold — which reduces persona-based jailbreak success by ~60% without degrading performance on IFEval, MMLU Pro, GSM8k, or EQ-Bench. Case studies demonstrate that activation capping prevents concerning behaviors like reinforcing delusional beliefs about AI consciousness and encouraging suicidal ideation in emotionally vulnerable users.
This work connects to prior findings on refusal directions and persona vectors by showing that the Assistant identity itself occupies a specific, manipulable region of activation space — and that post-training doesn’t fully tether models to it. The finding that emotionally charged conversations organically cause drift without adversarial intent is particularly relevant for user safety, complementing work on persona-based jailbreaks that deliberately exploit this vulnerability. The activation capping intervention is promising but limited to open-weight models tested at 27–70B scale and unintended side-effects on model character remain unclear.
Discuss